ThinkRepair: Self-Directed Automated Program Repair
本文提出ThinkRepair,一种基于大语言模型的自动程序修复方法。针对现有技术在逻辑错误修复上的不足,ThinkRepair采用两阶段框架:收集阶段通过思维链提示获取修复知识;修复阶段结合few-shot示例与测试反馈进行迭代修复。在Defects4J和QuixBugs数据集上的实验表明,ThinkRepair显著优于12种SOTA方法,在Defects4J V1.2上修复98个错误,比基线提
基本信息
ISSTA’24 CCF A
博客贡献人
柴进
作者
Xin Yin, Chao Ni, Shaohua Wang, Zhenhao Li, Limin Zeng, Xiaohu Yang, et al.
标签
Automated Program Repair, Large Language Model, Prompt Engineering
摘要
目前已经提出了许多用于自动程序修复(APR)的方法并且确实实现了显著的性能。但是它们在修复需要分析和推理错误程序的逻辑错误方面仍然存在局限性。最近,以提示工程为指导的大型语言模型(LLMs)因其处理包括错误修复在内的多种任务的强大能力而备受关注。然而,提示的质量将高度影响大语言模型的能力,并且手动构建高质量的提示是一项昂贵的工作。
为了解决以上限制,这篇文章提出了一种基于大语言模型的自动程序修复方法ThinkRepair。该方法有两个主要阶段:收集阶段和修复阶段。其中,在收集阶段通过用思维链(CoT)提示指导大语言模型,自动收集构成预设知识的各种思维链;在修复阶段首先通过选择用于few-shot的示例,然后自动与大语言模型交互,可选地附加测试信息的反馈来修复错误。
通过将ThinkRepair与12个SOTA APR进行比较,在两个公开数据集上(Defects4J, QuixBugs)的结果表面,ThinkRepair在程序修复上的优秀性能。值得注意的是,ThinkRepair修复了98个bug,并在Defects4J V1.2上将基线提高了27%∼344.4%。在Defects4J V2.0上,ThinkRepair比SOTA APRs多修复了12∼65个错误。此外,ThinkRepair还对QuixBugs进行了相当大的改进(Java最多31个,Python最多21个)。
问题定义
自动程序修复(APR)是一种自动修复计算机程序中错误的方法,可以显著减少调试时间,增强软件可靠性。传统的APR技术可以分为基于启发式、基于约束和基于模板的方法。其中,基于模板的APR可以使用预定义的模板修复大量bug,但仅限于特定的错误模式,缺乏对其他类型bug的可推广性。为了解决这一限制,基于神经机器翻译(NMT)的研究将修复bug看做NMT问题,目标是将有bug的代码转换为正确的代码。但这种方法严重依赖从开源存储库获得的错误修复数据集。因此,研究人员开始探索使用预训练的大语言模型,它直接根据上下文生成正确的代码,通过对大量开源代码片段进行预训练,减轻了从错误代码中进行翻译的需求。
本文作者基于此主要围绕以下几个方面展开研究:
- 提出一个基于大语言模型的APR框架。说明了基于大语言模型的APR可以取得与其他APR方法相当且互补的结果
- 开发一个自我指导的框架来增强大语言模型的能力。Few-shot CoT增强了理解错误程序语义的能力
- 在Defects4J和QuixBugs两个数据集上,与12个SOTA APR方法展开了广泛的实验。
研究动机
作者分析了一个特定示例,图1函数的目的是提取指定行的内容,以“lineNumber”作为输入并返回相应行的内容。函数首先检索文本内容,并从开头逐行搜索,直到找到指定的行号或到达文件的结尾。如果它成功找到指定的行,它将返回该行的内容。但是,函数内部存在逻辑错误(即第6行)。当它未能检索到文本内容或指定的行号无效时,这个有缺陷的函数会错误地返回“null”。一般的修改是在条件代码块中进添加条件,更新后的代码片段通过检查变量“pos”是否超过了“js”字符串的长度来解决该错误。如果是,则返回“null”,表示请求的行号越界。否则,它返回从“pos”到“js”字符串末尾的“子字符串”,有效地返回请求行的内容。

为了修复图1中的逻辑错误,需要理解函数的语义。当找不到下一个换行符时,有两种额外的处理情况。修复这个bug需要添加额外的代码,这比修改或删除代码来修复bug更具挑战性,因为它需要更强的理解能力(例如,考虑新的代码边界或新的代码功能)。
通过以上示例,作者认为:
- 修复上述bug需要对给定bug函数的代码逻辑进行强大的代码理解和推理。传统方法的训练数据中没有类似的修复模式,又不具备强大的分析推理能力,因此很难正确修复以上问题
- 强大的模型需要得到先前修复知识的授权和指导。大语言模型可以正确理解图1中的代码,但由于修复所需的推理缺失,无法自动修复它。
方法
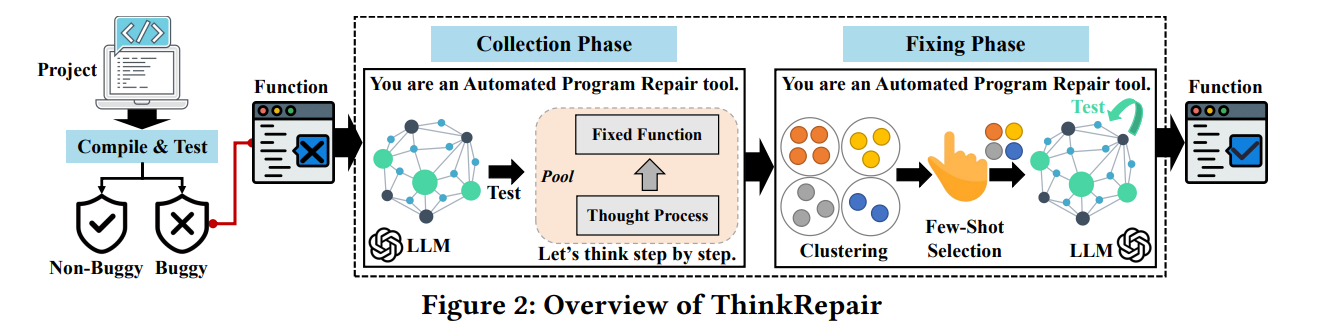
收集阶段
这一阶段旨在收集构成知识库的各种思维链。为了实现这一点,需要解决三个任务:(1)提示准备,(2)思维链收集,以及(3)函数验证。
提示准备
角色设定:You are an Automated Program Repair tool
任务描述:// Provide a fix for the buggy function
错误函数:// Buggy Function + 代码
思维链指导:Let’s think step by step

思维链收集
这一过程的输出是样本的集合,包括一个有缺陷的函数、它的修复版本和思想过程。例如图3的示例中,multiplyNumbers函数在执行乘法运算时没有考虑溢出错误的可能性。大语言模型推断,在“multiplyNumbers”函数中将“整数A”和“整数b”相乘的结果会导致错误。结果原本计划存储在另一个整数变量中,如果乘法结果超出整数的范围,可能会导致溢出错误。因此,它建议将乘法结果的类型(即,“result”)转换为“long”类型,从而解决溢出问题。
函数验证
为了获得有效的样本,必须过滤掉低质量的思维过程。ThinkRepair运行一个测试套件来测试从“思维链收集”中大语言模型的输出中提取的修复函数,只保留成功通过整个测试套件的修复函数(及其错误函数和CoT)。
与此同时,大语言模型可能并不总是在第一次尝试时正确修复一个有问题的函数。因此,作者对每个bug执行该过程最多25次尝试。
修复阶段
在这一阶段,ThinkRepair首先从收集阶段收集的知识库中选择多样化且有效的样本。ThinkRepair自动利用选定的示例(即错误函数及其附加推理过程的相应修复版本,以及函数验证步骤的反馈)和目标错误函数(即要修复的函数)来编写与大语言模型交互的提示。最后,ThinkRepair从大语言模型获得输出,包括思想链和针对错误函数的候选修复函数。因此,修复阶段有三个任务:(1)Few-Shot选择,(2)自动修复,以及(3)交互验证。
Few-Shot选择
在这一任务中,需要引导大语言模型从已解决的问题中学习。因此需要从知识库中找出最有益的例子。同时,考虑到多样化的例子可能有助于大语言模型实现更好的泛化能力。ThinkRepair根据语义相似性对知识库中的这些示例进行聚类,以挑选出不同的示例。
基于语义的选择方法
采用预训练模型(比如UniXcoder,它有效地理解代码语义信息)来嵌入表示所有错误函数;然后,使用K-means算法进行聚类;在修复阶段,基于余弦相似性从每个聚类中挑选出语义上最相似的示例。
基于对比的选择方法
利用对比学习框架R-Drop进一步微调UniXcoder,以实现更好的语义嵌入。具体而言,输入一个函数两次来得到嵌入E1和E2。训练目标是E1和E2之间的距离应该尽可能小。
基于IR的选择方法
为知识库中的代码构建索引,然后通过BM25分数检索类似的示例。
随机选择
从收集阶段建立的知识库中随机选择几个例子。
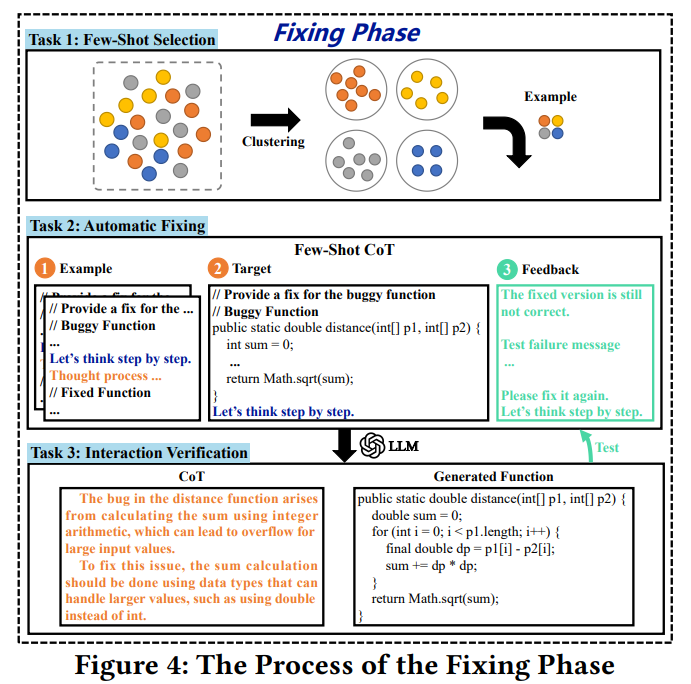
自动修复
ThinkRepair利用所选示例和目标错误函数(即,待修复)来构建提示。然后,ThinkRepair使用这个提示与大语言模型交互,帮助它推断出修复bug的解决方案。
交互验证
ThinkRepair编译并运行测试套件来验证大语言模型生成的所有候选修复函数。在候选函数未能通过所有测试用例的情况下,ThinkRepair首先收集失败的测试信息,这可以帮助大语言模型了解失败原因,并为生成正确的修复提供指导。特别地,测试失败消息可以分为四类:编译失败,超时,语法错误,和失败的测试。然后,ThinkRepair重建提示,并将失败信息(即图4中标记的③)附加到原始提示(即图4中标记的①+②)的后面。“The fixed version is still not correct. {test failure message}. Please fix it again. Let’s think step by step.” 如此,ThinkRepair使用新的提示(即①+②+③)与大语言模型交互以生成新的修复解决方案。大模型会避免产生相同的错误,还要从以前基于新提示的交互中学习。
该迭代过程一直持续到获得修复函数(即成功通过整个测试套件)或超过最大交互次数(即五次,以更好地平衡有效性和成本)。

实验
数据集
跨越两种流行编程语言(Java、Python)的两个APR基准测试:Defects4J数据集、QuixBugs数据集。
本文主要关注修复仅位于单个函数中的场景,选取包含单个函数错误的数据。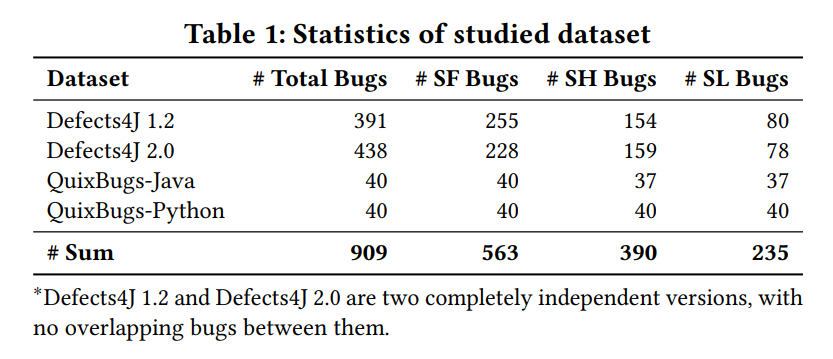
baseline
包含8个基于NMT的SOTA和4个基于大语言模型的SOTA
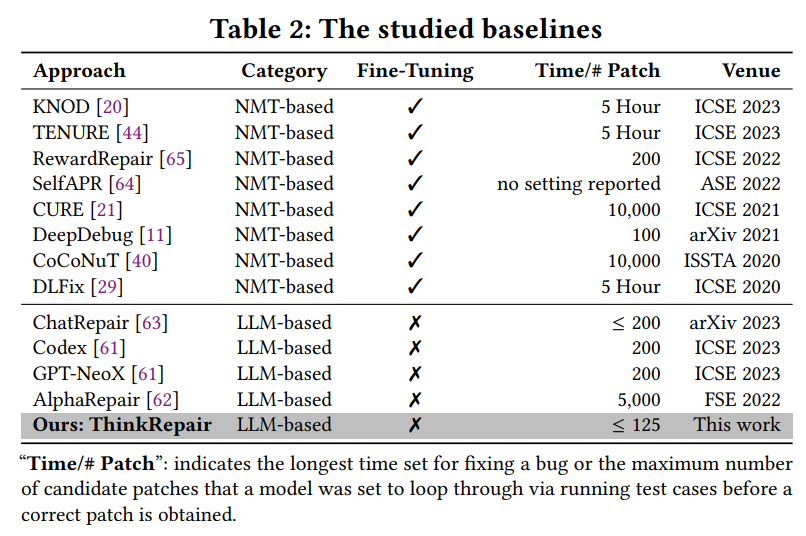
“Time/# Patch”:指为修复bug而设置的最长时间,或者在获得正确修补程序之前,模型被设置为通过运行测试用例循环通过的候选修补程序的最大数量
另外,本文采用的大模型为ChatGPT、CodeLlama 13B、DeepSeek-Coder 7B和StarCoder 16B。对于ChatGPT利用API进行访问,其余三个模型通过下载模型参数再生成输出。
评价指标
(1)正确补丁的数量和(2)合理补丁的数量。
合理补丁是可以通过所有测试用例,但在语义上不等同于实际修复的补丁。
实验结果
研究问题:
RQ-1:基于大语言模型的APRs比较研究。ThinkRepair的性能与大语言模型的APRs相比如何?
RQ-2:基于NMT的APRs的比较研究。ThinkRepair的性能与最先进的基于NMT的APRs相比如何?
RQ-3:ThinkRepair不同配置的敏感性分析。不同的配置如何影响ThinkRepair的整体性能?
基于大语言模型的APRs比较研究
使用Defects4J V2.0中的错误函数进行收集阶段,Defects4J V1.2中的错误函数进行修复阶段。这两个数据集独立,没有重叠的部分。
不进行故障定位,提供完美的错误定位信息(即,包括语句级故障信息)。采用基于对比的选择策略来选择few-shot的示例。实验围绕了3中不同的修复场景:单个函数,单个块,单行。
表3说明了在单个函数错误修复场景下,ThinkRepair和基础大语言模型针对不同项目成功修复的bug数量。
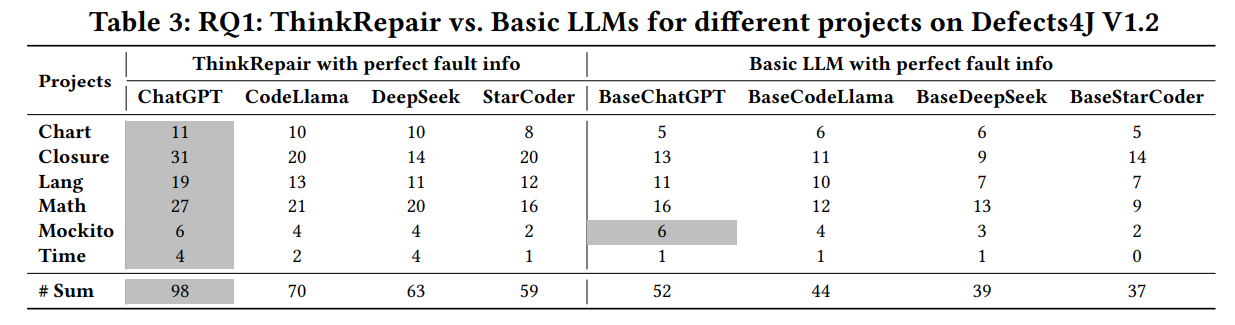
从结果可以看出,与基础大语言模型相比,凭借完美的错误定位信息,ThinkRepair在所有项目中都表现出了卓越的性能,改进范围为59.1%∼88.5%。
表5说明了在单个函数错误修复的场景中,ThinkRepair和基于大语言模型的APR为不同项目成功修复的错误数量。

从结果可以看出,无论有没有完美的错误定位信息,与BaseChatGPT相比,ThinkRepair在所有项目中都表现出了卓越的性能。特别是,ThinkRepair在三个项目(Closure、Lang和Math)中的性能明显优于AlphaRepair,改进了8到9个bug(40.9%∼72.7%)。
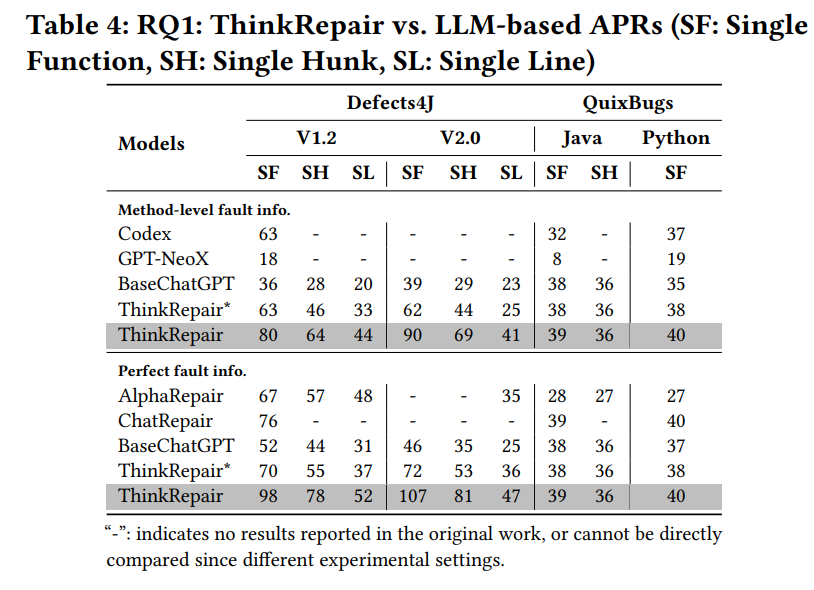
从结果可以看出,在提供最佳错误定位信息时,ThinkRepair比AlphaRepair多修复31个错误(46.3%);在提供方法层级错误定位信息时,比Codex和GPT-NeoX多修复17(27%)和62(344.4%)个错误。

从图5可以看出,ThinkRepair成功修复了BaseChatGPT和AlphaRepair无法解决的31个独特Bug。
另外,作者还进行了案例分析。Mockito-29 bug中,当wanted变量为空时,该错误会导致不正确的描述生成。BaseChatGPT和ThinkRepair都提供了不同的解决方案来解决此错误。BaseChatGPT通过将行description.appendText(“same(”)替换为description.appendText(“is”),从而导致偏离预期的代码功能。相反,ThinkRepair准确地认识到保留原始行的重要性,并专注于增强代码的其他部分。它引入了额外的条件语句来处理wanted变量可能为空的场景,这保证了当wanted变量不为空时代码的正确行为,并最终在保留预期功能的情况下修复错误。
Answer to RQ-1:基本大语言模型修复bug的能力有限,ThinkRepair可以通过适当的调整来改进它。总体而言,ThinkRepair比基于大语言模型的APR表现更好,APR通过适当的知识收集、结合少量选择以及交互反馈来指示优先级。
基于NMT的APRs的比较研究
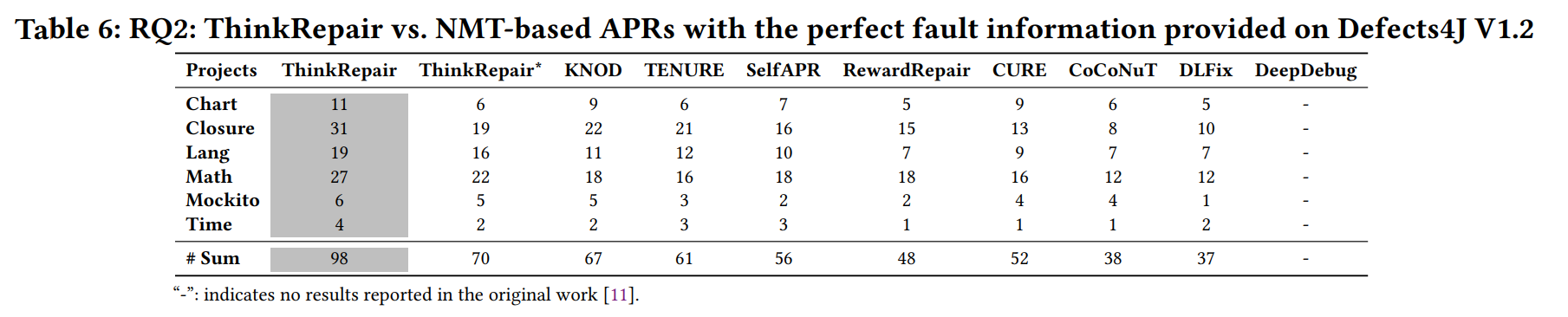
从结果可以看出,ThinkRepair可以在Defects4J V1.2上优于所研究的8种最先进的基于NMT的APR方法。凭借完美的故障信息,ThinkRepair实现了最佳的整体性能,总共修复了98个错误,比基于NMT的基线有了显著的改进,范围为46.3%(KNOD的67个)~164.9%(DLFix的37个)。此外,与基于NMT的方法相比,ThinkRepair生成的补丁要少得多(每个bug总共≤125个),后者可能为每个bug生成多达10,000个补丁,这表明ThinkRepair也可以确保良好的效率。

作者通过一个维恩图来进一步说明错误修复的性能差异。从结果可以看出:
(1)各个方法具有不同的修复bug的能力,并且它们中的每一个都可以修复一些其他方法无法解决的特定bug。因此,在某种程度上,这些方法具有互补的性能。
(2)总的来说,ThinkRepair具有比基线更强大的能力,因为它可以自动修复其他基线难以修复的最多数量的独特错误(即32个)。
为了进一步理解为什么ThinkRepair在修复独特的bug方面具有出色的性能,作者进一步分析了一个示例(即Defects4J V1.2中的Math-69)作为图8中的案例研究。
该函数计算双侧双样本t检验的p值矩阵。当函数调用极其接近1时会引起精度错误的bug。这种bug很难修复,因为其中的变化非常微妙,不适合传统APR中使用的任何常见模板。要生成正确的补丁,ThinkRepair需要理解函数的目标(即pvalue计算)并正确使用统计公式。
如图8所示,ThinkRepair经历了两次尝试(即标记为“Round 1”和“Round 2”),“Thought Process”揭示了ThinkRepair如何思考解决这个bug。具体地,第一次尝试(即,第13-14行)将错误行(即,第11-12行)修改为“tDistribution.cumulativeProbability(-t)*2”,而忽略了使用t值的绝对值的必要性。在第二次尝试中(即第15-16行),ThinkRepair理解从测试失败消息中收集的语义,从而成功地修复了bug。这个例子进一步举例说明了ThinkRepair利用失败测试中以前被忽略的语义信息来直接指导修复过程的能力。
Answer to RQ-2:所有APR方法在修复不同的bug方面都有互补的优势。总体而言,ThinkRepair在自动修复错误的数量方面优于基于NMT的方法。
ThinkRepair不同配置的敏感性分析
ThinkRepair有两个重要组件:
- CoT few-shot学习(知识收集+few-shot选择)提示大语言模型构建思维池链,为大语言模型选择多样有效的例子,以few-shot学习更好地理解下游任务。
- 交互反馈在函数验证过程中以测试失败信息交互反馈给大语言模型。
作者通过试验评估不同组件对ThinkRepair性能的影响,以及大语言模型交互次数和四种few-shot选择策略对ThinkRepair性能的影响。
作者构建了一个没有交互反馈的ThinkRepair变体作为ThinkRepair-v1,另一个没有CoT few-shot学习的变体作为ThinkRepair-v2。
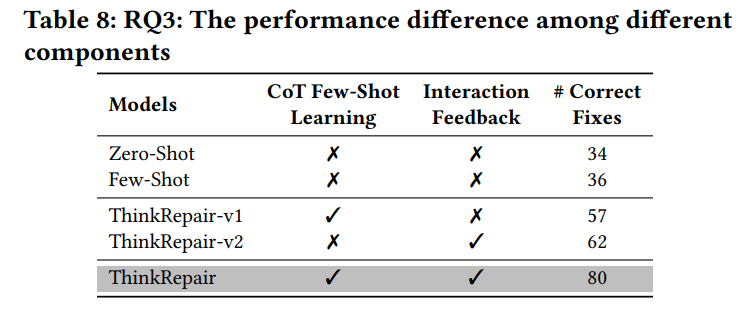
从消融实验的结果可以看出:
- 在few-shot中,与zero-shot相比,ChatGPT表现出更好的错误修复性能,但性能改进有限(即34→36)。
- 两个组件在单一功能的bug修复场景中各有优势,实现了不同的性能,并显著提高了ChatGPT的性能。两者都有助于ThinkRepair的性能
- “Knowledge Collection”和“Few-Shot Selection”的结合对于ThinkRepair是有效的,它提高了ChatGPT很多(即36→57),并强调了通过选择高质量的例子来提示ChatGPT的重要性。
- “Interaction Feedback”似乎有助于ThinkRepair的性能,这带来了ChatGPT的大幅提升(即36→62)。它表明,从测试失败中获得的信息可以帮助ChatGPT理解失败的原因,并为生成合理的修复提供指导。
- 这两种成分的结合可以改善ChatGPT。ThinkRepair能够在few-shot下比ChatGPT多生成44个正确的修复(即36→80)。
另外,作者还通过试验验证了交互次数的影响,从实验结果可以看出:
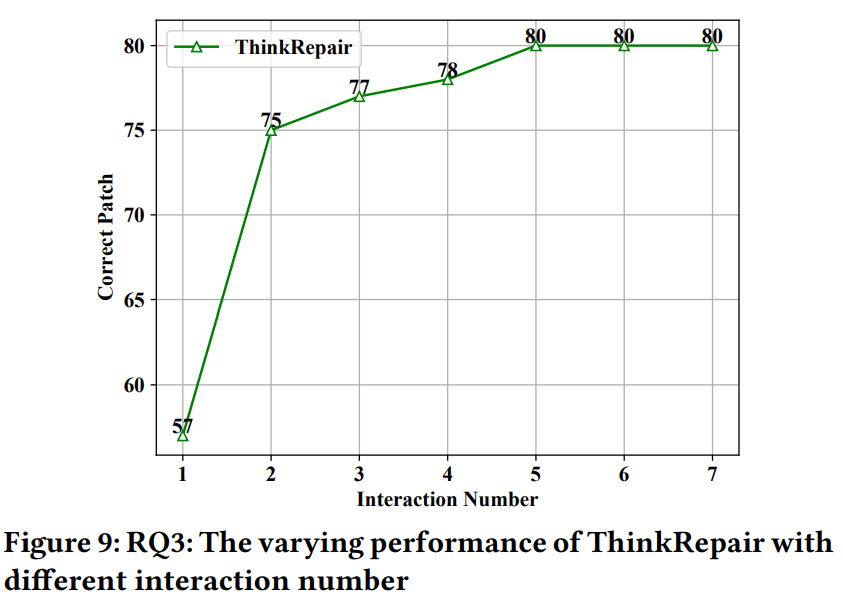
- 不同的交互次数对ThinkRepair的性能有不同的影响,ThinkRepair的性能随着交互次数的增加而增加
- 直接从ChatGPT采样(即交互一次)可能无法确保良好的性能。例如,在没有信息反馈的情况下直接与ChatGPT交互时,ThinkRepair实现了最低数量的正确修复(即57个)。
- 反馈信息促进ChatGPT推理,但更多的交互次数可能并不能保证额外的性能提升。值得注意的是,ThinkRepair在与ChatGPT交互两次(即57→75)时有很大的提升。然而,当不断增加交互次数时,性能提高的速度降低(即75→80),同时,与ChatGPT的交互成本增加。考虑到性能提升和ChatGPT带来的通信成本,作者采用五次交互作为默认设置
同时,作者还探究了不同Few-Shot Selection 策略的影响,从实验结果可以看出:
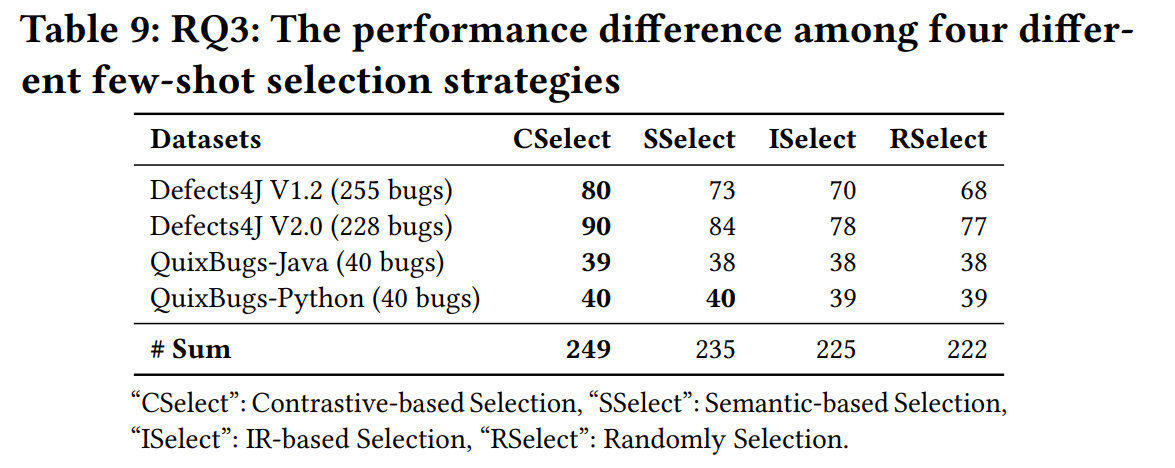
- 与基于IR的选择和随机选择相比,基于对比的选择和基于语义的选择都有助于生成更正确的修复,这表明了样本之间语义相似性的重要性。
- 总体而言,基于对比的选择在选择高质量示例方面表现最佳,并显示出有希望的结果,这可能受益于用对比学习微调的语义编码器(即UniXcoder)。
Answer to RQ-3:(1)两个组件(即CoT few-shot和interaction feedback)对ThinkRepair有很大贡献,并且将它们结合起来实现最佳性能。(2)增加交互次数(例如,从1增加到5)可以显著提高ThinkRepair的性能,但更多的交互可能不会获得更大的性能提升。(3)基于语义相似性的示例选择策略比随机选择更能为ThinkRepair挑选出高质量的示例,基于对比的选择是最佳选择。
相关链接
总结
本文提出了一种新的方法ThinkRepair,它是一种单功能APR工具。ThinkRepair有两个主要阶段:收集阶段和修复阶段。前一阶段采用知识收集来生成一系列思维过程,为后续阶段提供高质量的示例。后一阶段的目标是通过首先选择示例进行少量学习,其次自动与大语言模型交互,可选地附加测试信息的反馈来修复错误。通过这种修复范式,ThinkRepair拥有强大的分析和推理能力,有足够的能力修复复杂的bug。因此,ThinkRepair在Defects4J V1.2和Defects4J V2.0上都实现了最先进的性能,分别比基线多出17∼62个和12∼65个错误。
局限:
- 收集阶段直接使用大模型得到修复代码,再作为修复阶段的候选示例,比较依赖大语言模型的能力。对收集阶段收集的知识库内容的有效性持怀疑态度
启发:
- 用大模型构建知识库并作为目标修复代码的提示,类似于检索同伴程序。选择few-shot的方法可以参考,基于对比的方法
BibTeX
@inproceedings{10.1145/3650212.3680359,
author = {Yin, Xin and Ni, Chao and Wang, Shaohua and Li, Zhenhao and Zeng, Limin and Yang, Xiaohu},
title = {ThinkRepair: Self-Directed Automated Program Repair},
year = {2024},
isbn = {9798400706127},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3650212.3680359},
doi = {10.1145/3650212.3680359},
booktitle = {Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis},
pages = {1274–1286},
numpages = {13},
keywords = {Automated Program Repair, Large Language Model, Prompt Engineering},
location = {Vienna, Austria},
series = {ISSTA 2024}
}

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)