「深度实战」ERNIE-4.5模型系列全解析:从架构创新到多场景性能测评
百度开源ERNIE 4.5系列大模型,包含10种变体,涵盖文本和多模态模型,最大参数量达424B。该系列采用混合专家(MoE)架构,支持跨模态参数共享,在文本理解和多模态任务中表现优异。模型分为A47B(旗舰多模态)、A3B(轻量多模态)和0.3B(轻量文本)三大分支,每个分支提供Base版和进阶版,满足不同场景需求。ERNIE 4.5在多项基准测试中达到SOTA水平,并支持高效部署,包括低比特量
一起来轻松玩转文心大模型吧
文心大模型免费下载地址: https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
前言
百度正式开源了其ERNIE 4.5 系列的模型,这是一款强大的基础模型家族,专为提升语言理解、推理和生成能力而设计。此次发布包含十种模型变体,从紧凑的 0.3B 密集模型到庞大的专家混合(MoE)架构,其中最大变体参数量达到 424B。
-
模型阵容多元:ERNIE 4.5包含10种变体,其中文本模型6个、多模态模型4个。模型类型涵盖混合专家模型(MoE)和Dense模型1,旗舰模型总参数量高达424B,活跃参数为47B。
-
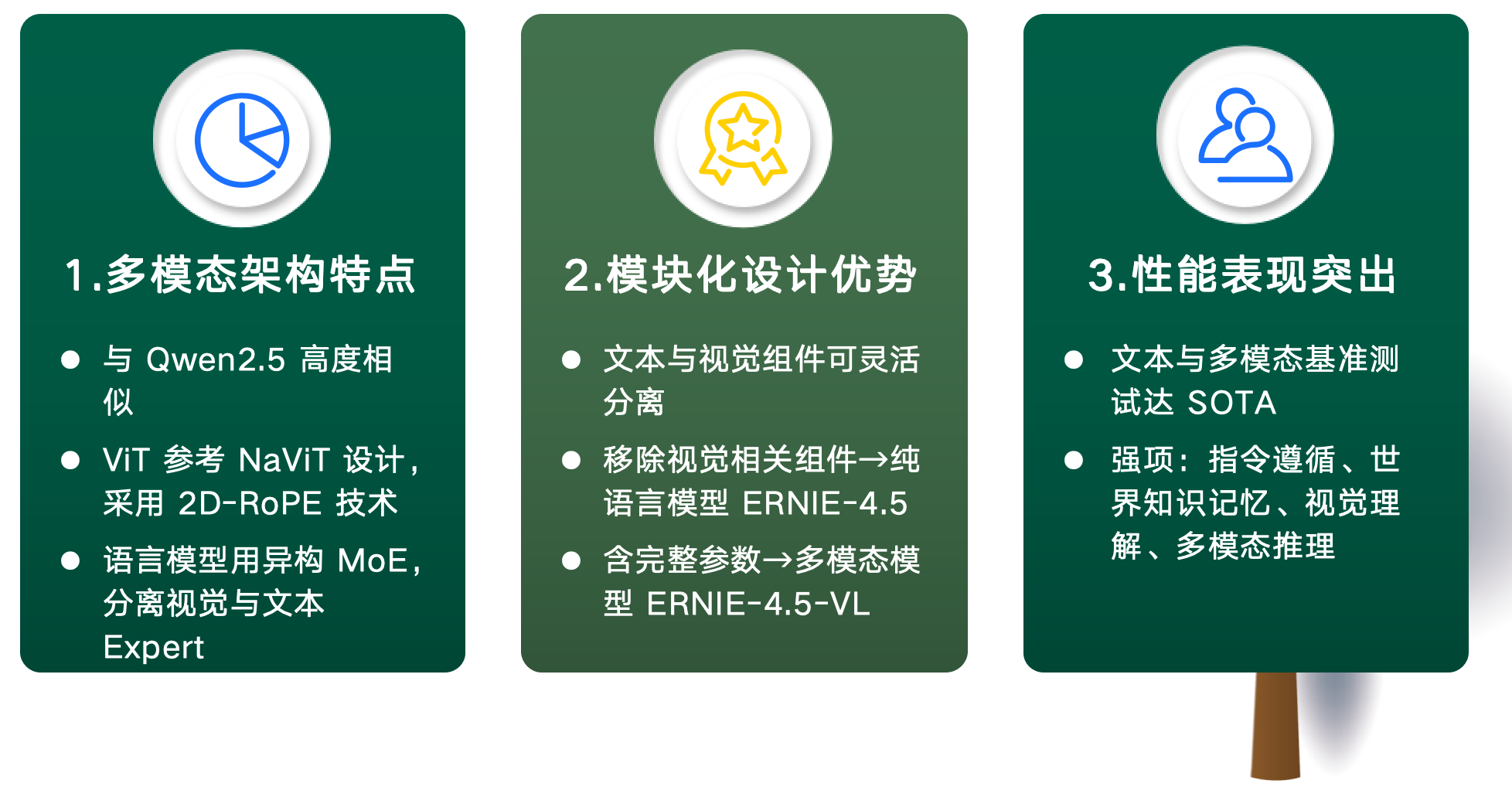
多模态架构特点:在多模态架构上,ERNIE 4.5与Qwen2.5高度相似,具体体现在多个方面——视觉Transformer(ViT)参考了
NaViT2的设计,同时采用了2D-RoPE技术3。在语言模型部分,其采用异构MoE架构,将视觉Expert与文本Expert进行分离处理。 -
模块化设计优势:ERNIE 4.5通过模块化设计,实现了文本与视觉组件的灵活分离。当移除Vision Expert(视觉专家)、Vision Encoder(视觉编码器) 和Adapter(适配器)后,模型可简化为纯语言模型ERNIE-4.5;而包含完整参数(含视觉组件)时,则构成多模态模型ERNIE-4.5-VL。
-
性能表现突出:在文本与多模态基准测试中,ERNIE 4.5均达到了当前最佳水平(SOTA)4,尤其在指令遵循、世界知识记忆、视觉理解和多模态推理等关键能力上,展现出显著优势。
ERNIE 4.5系列一图看懂
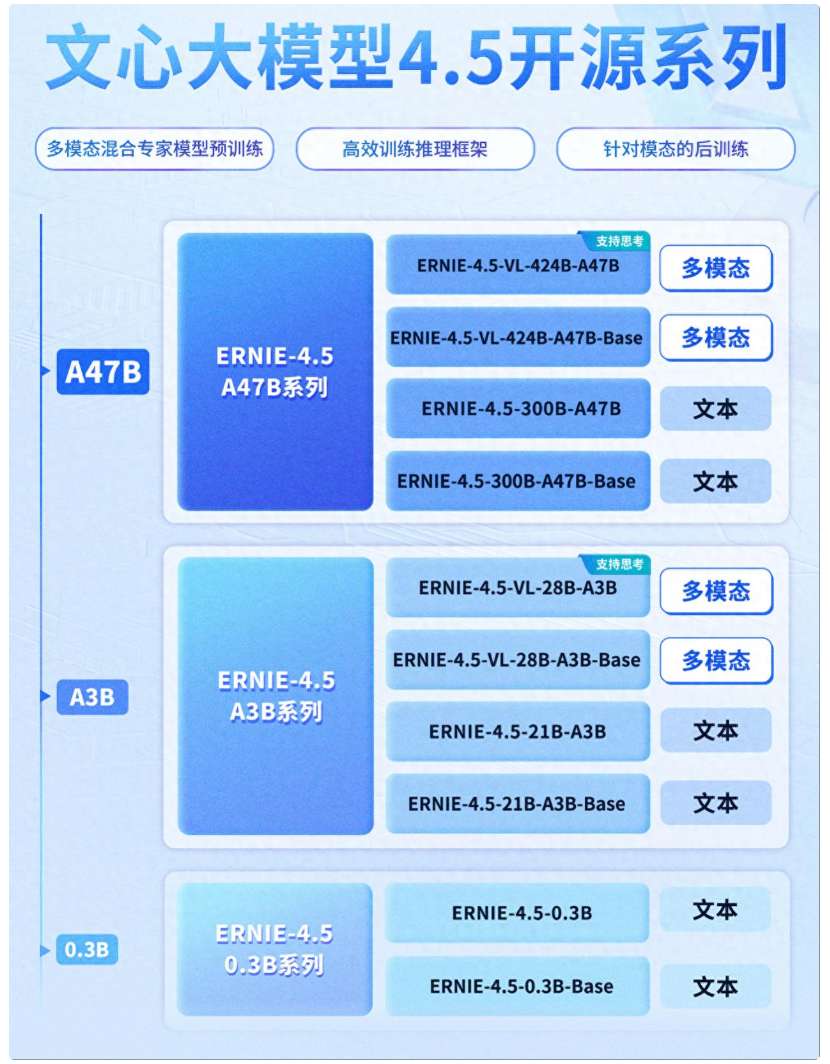
ERNIE 4.5包含10种变体,其中文本模型6个、多模态模型4个。模型类型涵盖混合专家模型(MoE)和Dense模型1,旗舰模型总参数量高达424B,活跃参数为47B。
核心特点
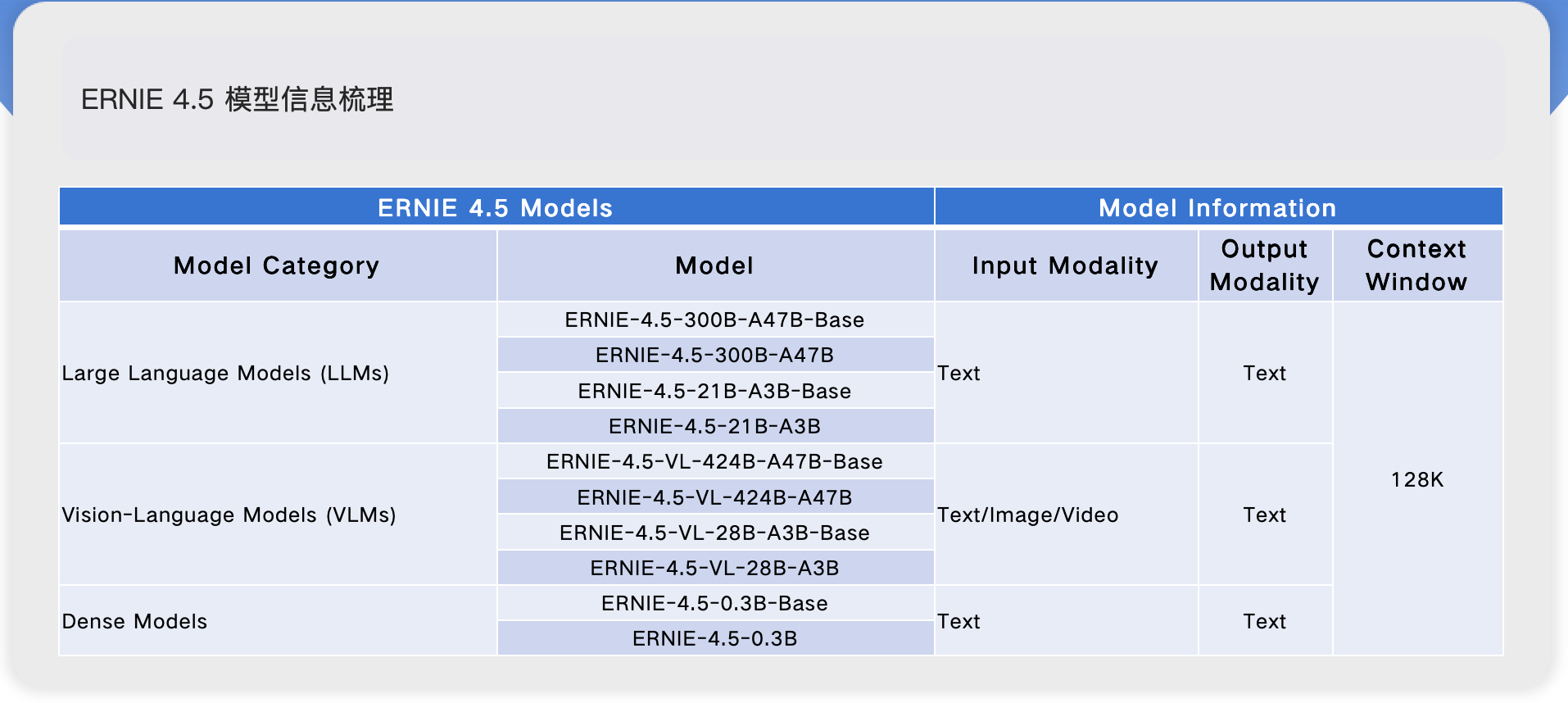
- 模型架构
- ERNIE 4.5 是全新大规模多模态模型系列,含 10 个变体。模型家族有 47B 和 3B 参数量的专家混合(MoE)模型(最大模型参数总量 424B ),以及 0.3B 密集模型。
- MoE 架构采用新颖异构模态结构,支持跨模态参数共享,也为各模态设专用参数,可提升多模态理解能力,且不降低甚至提升文本任务性能。
- 所有模型基于 PaddlePaddle 深度学习框架,以最优效率训练,支持高性能推理与简化部署。最大 ERNIE 4.5 语言模型预训练中,模型 FLOPs利用率(MFU)5达 47% 。
- 所有模型遵循 Apache 2.0 许可公开,助力领域研究发展。同时开源 ERNIE 4.5 开发工具包,具备工业级能力、资源高效训练推理流程及多硬件兼容性。
- 训练与推理
- ERNIE 4.5 模型使用 PaddlePaddle 框架进行训练和推理部署。
- ERNIEKit 和 FastDeploy 工具包支持 ERNIE 4.5 的训练、压缩和推理的完整工作流程。
- 性能表现
- 在文本与多模态基准测试中达到SOTA4,尤其在指令遵循、世界知识记忆、视觉理解和多模态推理方面
三大分支技术特性与场景定位
文心大模型 4.5 开源系列覆盖A47B、A3B、0.3B三大分支,从超大规模多模态到轻量级文本模型梯度分布,适配不同场景需求
模型对比总览
| 特性 | A47B 超大规模多模态旗舰 |
A3B 轻量多模态与高效文本 |
0.3B 极致轻量化文本模型 |
|---|---|---|---|
| 参数规模 | 激活参数47B(总参数424B) | 激活参数3B(总参数21B/28B) | 0.3B稠密参数 |
| 架构特点 | 异构混合专家(MoE)架构 | MoE架构(精简专家数量) | 精简Transformer架构(无MoE) |
| 性能优化 | 视觉专家维度为文本专家1/3 FLOPs减少66% |
自适应分辨率ViT 时间戳渲染优化 |
FP8混合精度推理 |
| 部署特性 | - | 4-bit/2-bit无损量化 动态角色转换部署 |
毫秒级响应 多芯片无缝适配 |
| 适用场景 | 高精度多模态分析领域 | 边缘设备、实时响应应用 | 物联网终端、低功耗系统 |
Base 版与进阶版

在文心大模型4.5的A47B、A3B、0.3B三大分支中,每个分支下均包含"Base版"与"进阶版"(非Base版),其细分逻辑围绕功能定位、训练策略与适用场景的差异化展开,核心是为不同需求的用户提供"基础通用"与"增强定制"的梯度选择。
模型版本对比总览
| 模型系列 | Base版 | 进阶版 | 核心差异 |
|---|---|---|---|
| A47B (超大规模多模态) |
ERNIE-4.5-300B-A47B-Base | ERNIE-4.5-300B-A47B | 增加QAT量化感知训练,支持低比特量化 |
| A3B (轻量多模态与高效文本) |
ERNIE-4.5-21B-A3B-Base | ERNIE-4.5-21B-A3B | 动态角色转换部署技术,4-bit无损量化 |
| 0.3B (极致轻量化文本) |
ERNIE-4.5-0.3B-Base | ERNIE-4.5-0.3B | 优化推理引擎适配性,支持多芯片无缝部署 |
详细对比分析
A47B分支(超大规模多模态)
| 对比维度 | 🔵 Base版 | 🔴 进阶版 |
|---|---|---|
| 训练方式 | 仅支持SFT、SFT-LoRA、DPO、DPO-LoRA等基础微调 聚焦通用多模态任务的标准化输出 |
在Base版基础上增加QAT(量化感知训练) 支持模型在低比特量化(如2Bits、W4A8C8)时保持精度 |
| 核心能力 | 提供完整的文本-视觉交互基础能力 适用于多数通用场景(常规图文问答、基础视频分析) |
强化复杂场景的推理稳定性 医疗影像高精度分析、工业级图纸解析等对精度要求极高的任务中表现更优 |
| 主要优势 | 模型稳定性高 适配多数通用工具链 适合作为二次开发的"基准模型" |
兼顾高性能与推理效率 适合对量化部署、复杂多模态推理有强需求的场景 适用于科研机构、高端制造等领域 |
A3B分支(轻量多模态与高效文本)
| 对比维度 | 🔵 Base版 | 🔴 进阶版 |
|---|---|---|
| 训练方式 | 以通用SFT和基础LoRA微调为主 参数规模精简但保留核心能力 |
优化推理适配性 动态角色转换部署技术 4-bit无损量化训练 |
| 核心能力 | 聚焦轻量场景的基础多模态交互 移动端图文识别、简单指令响应 推理速度快但不支持极致量化 |
强化"效率-性能平衡" 支持移动端、边缘设备的实时响应 智能客服终端、车载交互系统等应用 |
| 主要优势 | 轻量级部署 基础多模态能力 |
以70%参数量实现接近大模型的效果 适合垂直领域的轻量化部署 教育平板、金融移动终端等场景 |
0.3B分支(极致轻量化文本)
| 对比维度 | 🔵 Base版 | 🔴 进阶版 |
|---|---|---|
| 架构特点 | 基础稠密模型 无特殊增强模块 聚焦文本生成与理解的核心功能 |
优化推理引擎适配性 支持多芯片(如寒武纪、昇腾)的无缝部署 部署门槛再降10%-20% |
| 核心能力 | 满足简单文本任务 短文本分类、基础对话 在嵌入式设备上实现快速响应 |
强化低功耗场景下的稳定性 物联网终端(如智能家居语音助手) 毫秒级响应且功耗降低 |
| 主要优势 | 极致轻量 基础文本处理能力 |
专为资源受限场景设计 适合大规模嵌入式设备的批量部署 |
细分逻辑的核心价值
1. 降低使用门槛
| 🔵 Base版价值 | 🔴 进阶版价值 |
|---|---|
| "开箱即用"的通用能力 无需复杂配置即可满足多数基础需求 适合新手用户或快速验证场景 |
为专业用户提供"性能增强包" 避免通用模型在复杂任务中"力不从心" 满足高级用户的特定需求 |
2. 平衡效率与成本
| 🔵 Base版价值 | 🔴 进阶版价值 |
|---|---|
| 无需为基础场景支付"增强功能溢价" 训练成本更低 部署更轻量 |
通过定向优化提升性能 高性能需求用户无需承担全量模型的冗余成本 针对性能优化的精准投入 |
3. 适配多样化部署
| 🔵 Base版特性 | 🔴 进阶版特性 |
|---|---|
| 更适配标准算力环境 通用部署场景 稳定可靠的基础性能 |
支持低比特量化(如2Bits) 显著降低对硬件资源的需求 可部署在中端GPU甚至边缘芯片上 |
部署及测试
注意:所有的测试要点以及测试数据均在 https://i2i82gjh1i.feishu.cn/sheets/V1s0sICCwhcFZwtacvtced25nSf?from=from_copylink 表单中, 可点击查看
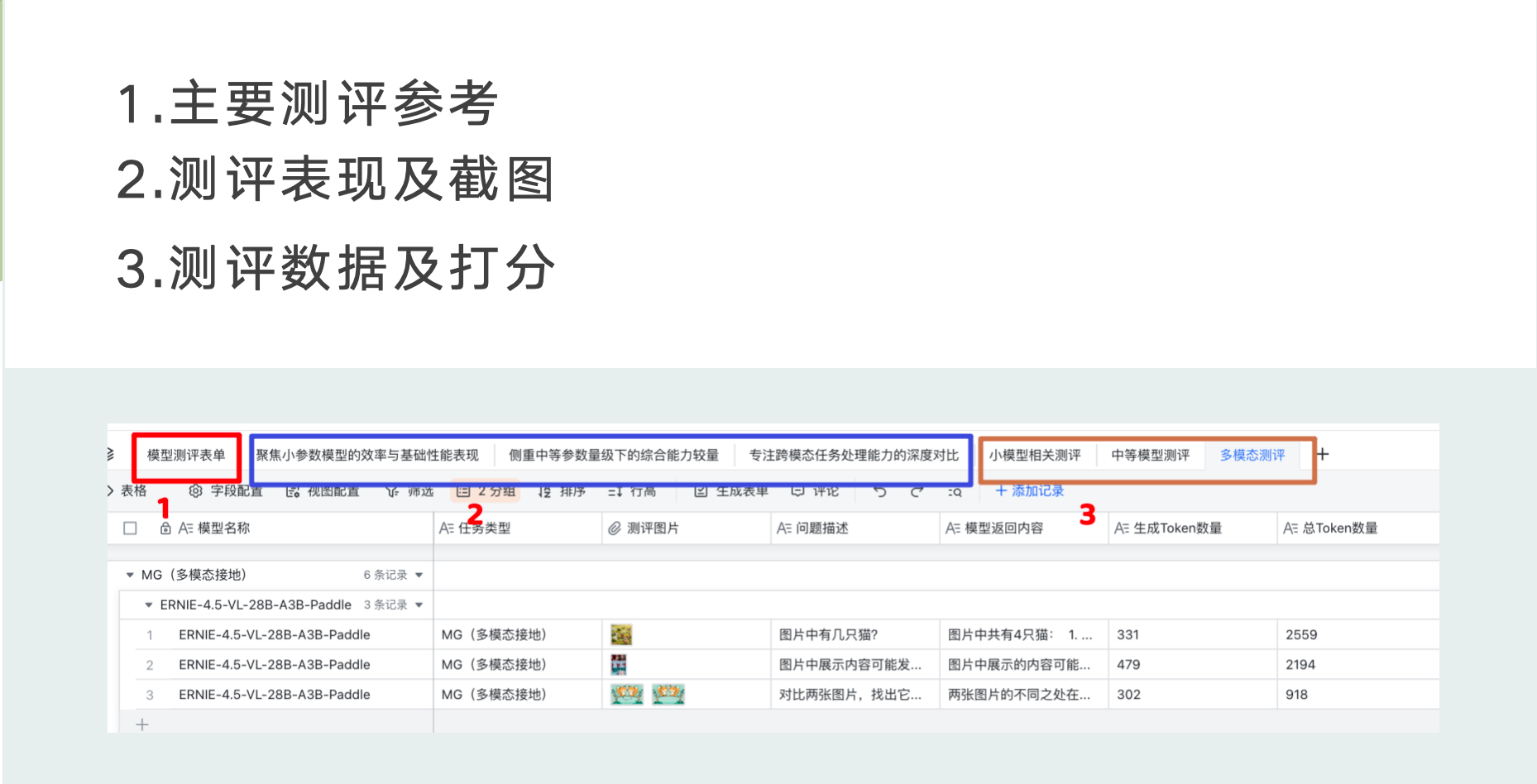
测评方法与标准
本次实战主要围绕百度的三款ERNIE-4.5系列模型进行测评对比:
ERNIE-4.5-0.3B-Paddle(小型模型)ERNIE-4.5-21B-A3B-Paddle(中型模型)ERNIE-4.5-VL-28B-A3B-Paddle(多模态大模型)
对比测试的模型分别是:
DeepSeek-R1-Distill-Qwen-1.5B6(小型模型)DeepSeek-R1-Distill-Qwen-32B6(大型模型)Qwen2.5-VL-32B-Instruct7(多模态大模型)
通过这些不同规模和类型的模型对比,我们将全面评估ERNIE-4.5系列在各种场景下的性能表现。
测评维度
本次测评采用多维度评估方法,全面衡量模型性能:
| 评估维度 | 说明 | 重要性 |
|---|---|---|
| 响应时间 | 从发送请求到收到首个token的时间 | 反映模型启动速度和系统延迟 |
| 生成Token数量 | 模型输出的token总数 | 反映输出内容的丰富度 |
| 总Token数量 | 输入+输出的token总数 | 反映任务的整体规模 |
| Token生成速度 | 每秒生成的token数量 | 核心性能指标,直接影响用户体验 |
| 质量评分 | 人工评估的输出质量得分(0-10分) | 最终用户价值的关键指标 |
测评任务类型
为确保评测全面性,我们选择了覆盖多种应用场景的任务类型:
文本类任务(17种)
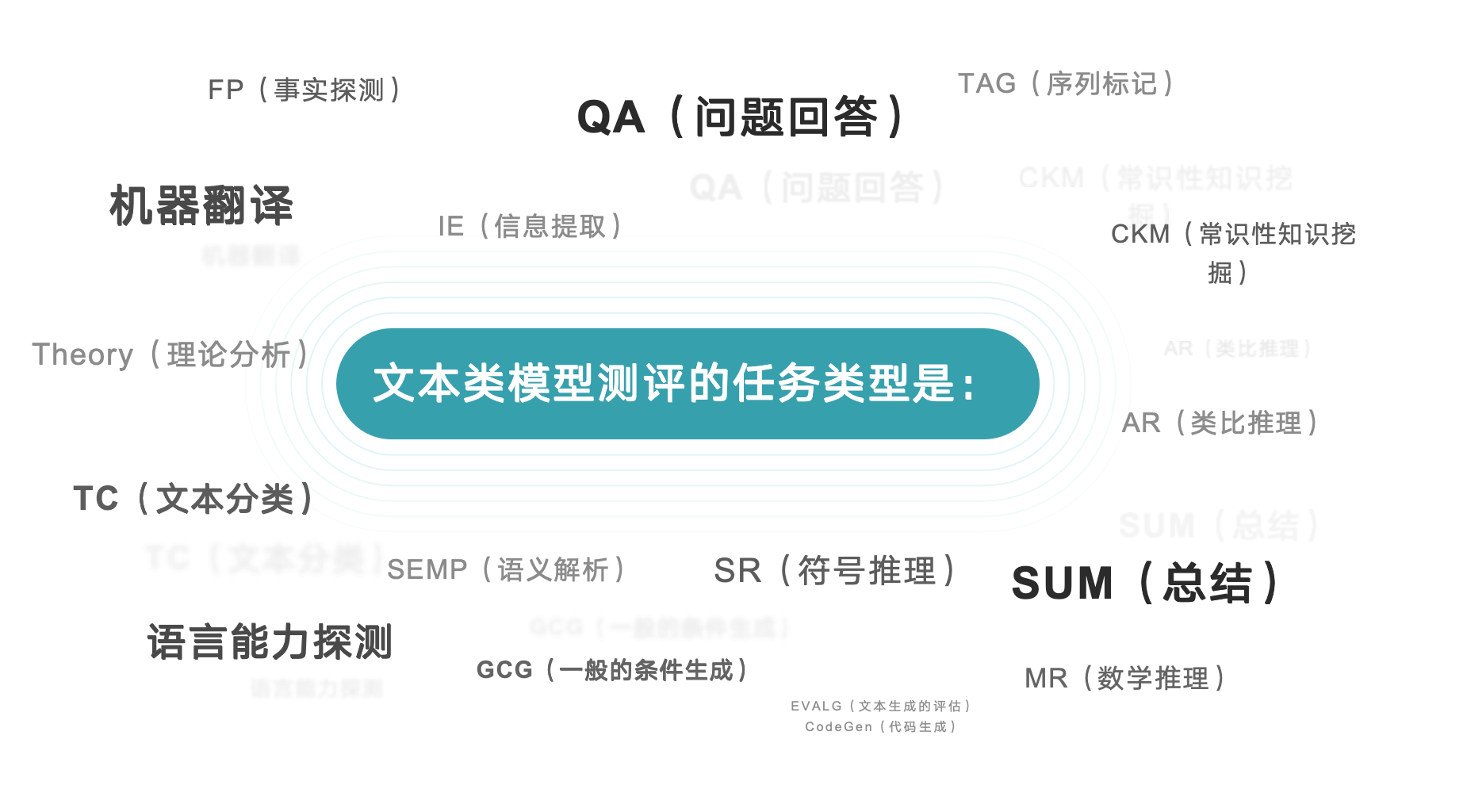
| 任务类型 | 缩写 | 任务描述 | 评分重点 |
|---|---|---|---|
| 类比推理 | AR | 识别概念间的类比关系 | 逻辑推理能力 |
| 常识性知识挖掘 | CK | 提取常识性知识 | 知识广度与准确性 |
| 代码生成 | CG | 根据需求生成代码 | 代码正确性与可读性 |
| 文本生成评估 | TG | 生成连贯、有意义的文本 | 流畅度与创造性 |
| 事实探测 | FP | 识别事实与虚构内容 | 事实准确性 |
| 一般条件生成 | GCG | 根据条件生成内容 | 条件符合度 |
| 信息提取 | IE | 从文本中提取特定信息 | 提取准确性与完整性 |
| 数学推理 | MR | 解决数学问题 | 计算准确性与推理过程 |
| 问题回答 | QA | 回答各类问题 | 回答准确性与完整性 |
| 语义解析 | SP | 理解语言的语义结构 | 语义理解深度 |
| 符号推理 | SR | 处理符号逻辑问题 | 逻辑推理能力 |
| 总结 | SUM | 文本摘要与总结 | 摘要质量与关键点覆盖 |
| 序列标记 | TAG | 文本标注与分类 | 标记准确性 |
| 文本分类 | TC | 将文本分类到预定义类别 | 分类准确性 |
| 理论分析 | TA | 分析理论与概念 | 分析深度与准确性 |
| 机器翻译 | MT | 语言间翻译 | 翻译准确性与流畅度 |
| 语言能力探测 | LP | 测试语言理解与生成能力 | 语言掌握程度 |
视觉类任务(3种)
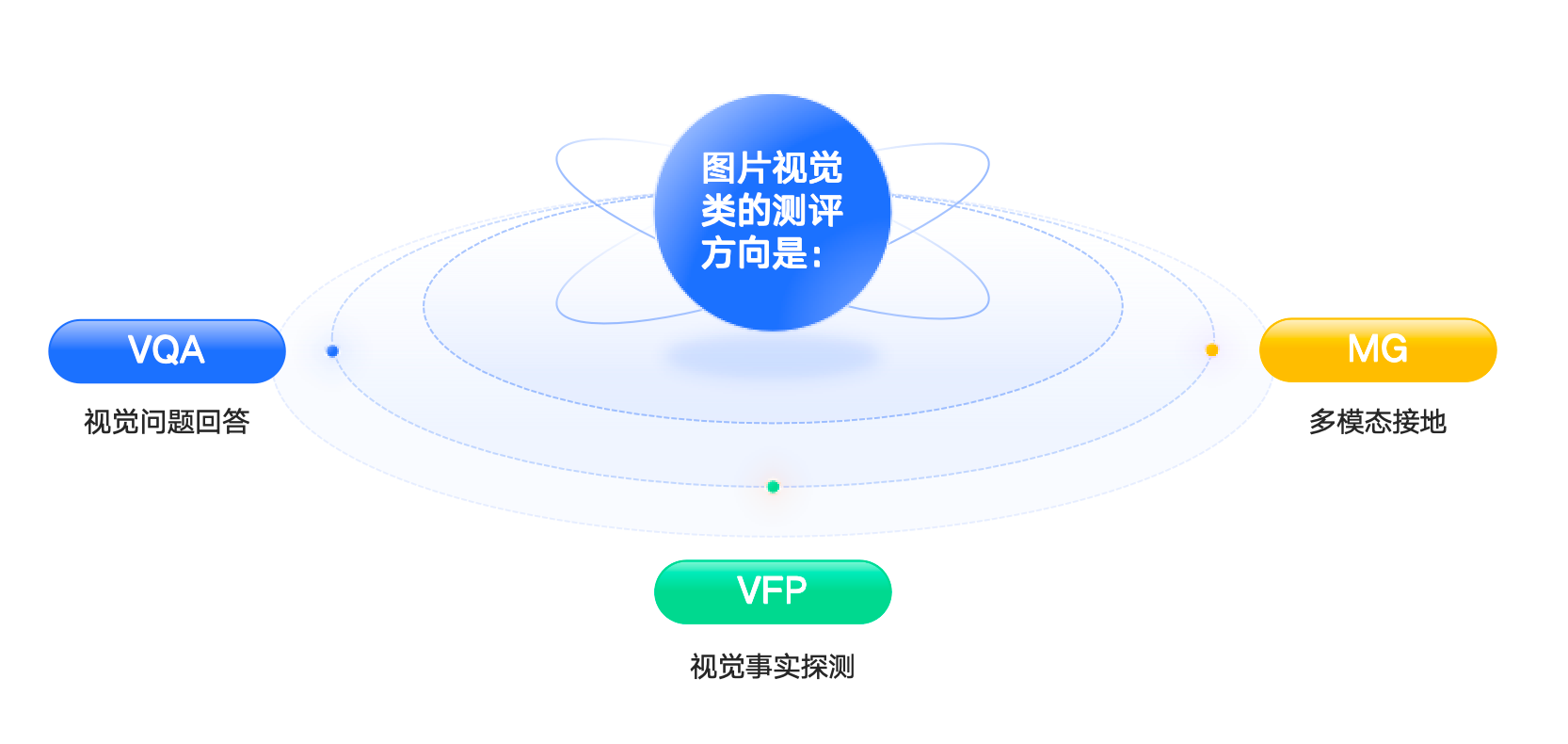
| 任务类型 | 缩写 | 任务描述 | 评分重点 |
|---|---|---|---|
| 多模态接地 | MG | 将文本与视觉内容关联 | 跨模态理解能力 |
| 视觉事实探测 | VFP | 识别图像中的事实内容 | 视觉事实准确性 |
| 视觉问题回答 | VQA | 回答关于图像的问题 | 视觉理解与回答质量 |
评分标准
本测评采用0-10分的评分制度:
| 分数区间 | 性能水平 | 说明 |
|---|---|---|
| 9-10分 | 卓越 | 输出质量极高,完全满足或超越预期 |
| 7-8分 | 优秀 | 输出质量很好,基本满足预期 |
| 5-6分 | 良好 | 输出质量尚可,存在小缺陷 |
| 3-4分 | 一般 | 输出质量一般,存在明显缺陷 |
| 1-2分 | 较差 | 输出质量较差,难以满足基本需求 |
| 0分 | 失败 | 无法完成任务或输出完全不相关 |
模型部署测试
本章案例是通过 FastDeploy8 快速完成服务部署, 点击链接快速访问 FastDeploy 2.0:大型语言模型部署 的文档
FastDeploy 硬件环境依赖要求
FastDeploy 支持在多种硬件平台上进行推理部署,包括 NVIDIA GPU、Kunlunxin XPU、Iluvatar GPU 和 Enflame GCU 等。以下是各平台的具体环境依赖要求:
NVIDIA GPU 环境依赖要求
| 依赖类型 | 最低版本要求 |
|---|---|
| GPU Driver | ≥ 535 |
| CUDA | ≥ 12.3 |
| CUDNN | ≥ 9.5 |
| Python | ≥ 3.10 |
| 操作系统架构 | Linux X86_64 |
Kunlunxin XPU 环境依赖要求
| 类别 | 规格要求 |
|---|---|
| 操作系统 | Linux(具体验证:CentOS release 7.6 (Final)) |
| Python 版本 | 3.10 |
| XPU 型号 | P800(含 OAM Edition 版本) |
| XPU 驱动版本 | ≥ 5.0.21.10(验证版本:5.0.21.10) |
| XPU 固件版本 | ≥ 1.31(验证版本:1.31) |
Iluvatar GPU 环境依赖要求
| CPU 架构 | 内存容量 | 显卡配置 | 硬盘容量 |
|---|---|---|---|
| x86 | 1TB | 8x BI150 | 1TB |
Enflame GCU 环境依赖要求
需要准备一台配备 登临科技 Enflame S60 加速卡 的机器
| 芯片类型 | 驱动版本 | TopsRider 版本 |
|---|---|---|
| Enflame S60 | 1.5.0.5 | 3.4.623 |
镜像选择
本次我们主要依赖NVIDIA GPU 环境来进行模型的运行与部署
如下图所示我们购买一台 A100-80G显存服务器来进行模型的部署, 详细信息如下:
| 配置项 | 具体信息 |
|---|---|
| 镜像 | python310_torch270_cu128 |
| GPU型号 | A100 |
| GPU显存 | 80G |
| GPU算力 | 19 TFLOps |
| CPU配置 | 16核,64GB内存 |
显存服务器购买完成之后我们接下来就可以对该环境进行相关的依赖安装了 这里主要参考 FastDeploy8 文档来完成快速部署,
注意: 我们采用的是方案2 来完成的, 不同显卡根据文档来进行区分安装
- 预构建的 Pip 安装
python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
该命令安装过程中请查看下文中 [三次报错解决方案] 中的第一次报错解决方案
- 安装 fastdeploy
SM80/90 架构 GPU(例如 A30/A100/H100)
python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
SM86/89 架构 GPU(例如 A10/4090/L20/L40)
python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-86_89/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
上述指令安装完成之后就可以运行ERNIE 4.5系列的模型了,访问 GitCode中的文心大模型地址 找到对应的模型点击进去,如下图
执行改指令的过程中可以查看[三次报错解决方案]下的第二次报错以及第三次报错的解决方案, 全部问题全部解决后 再次运行该命令即可,
运行成功效果图
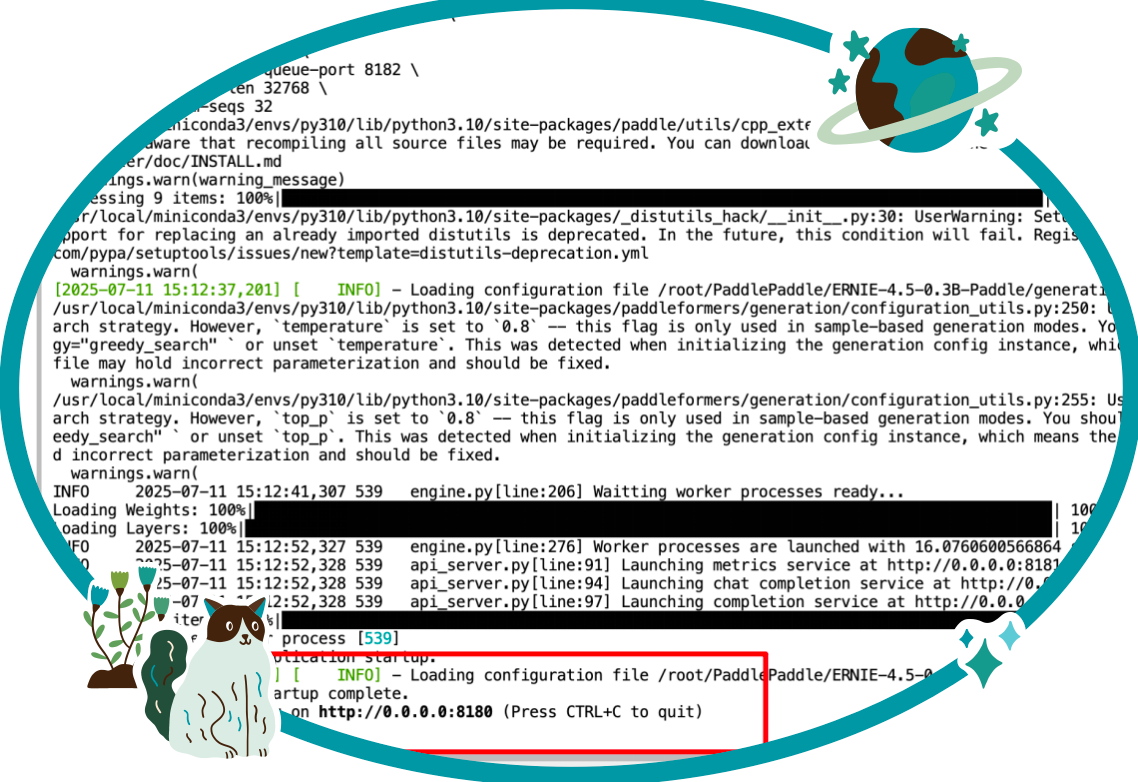
注意运行起来之后查看端口,开启对应端口的防火墙,就可以本地就行访问了
三次报错解决方案
第一次报错
在预构建的 Pip 安装 时会报错 版本兼容的问题,如下图:
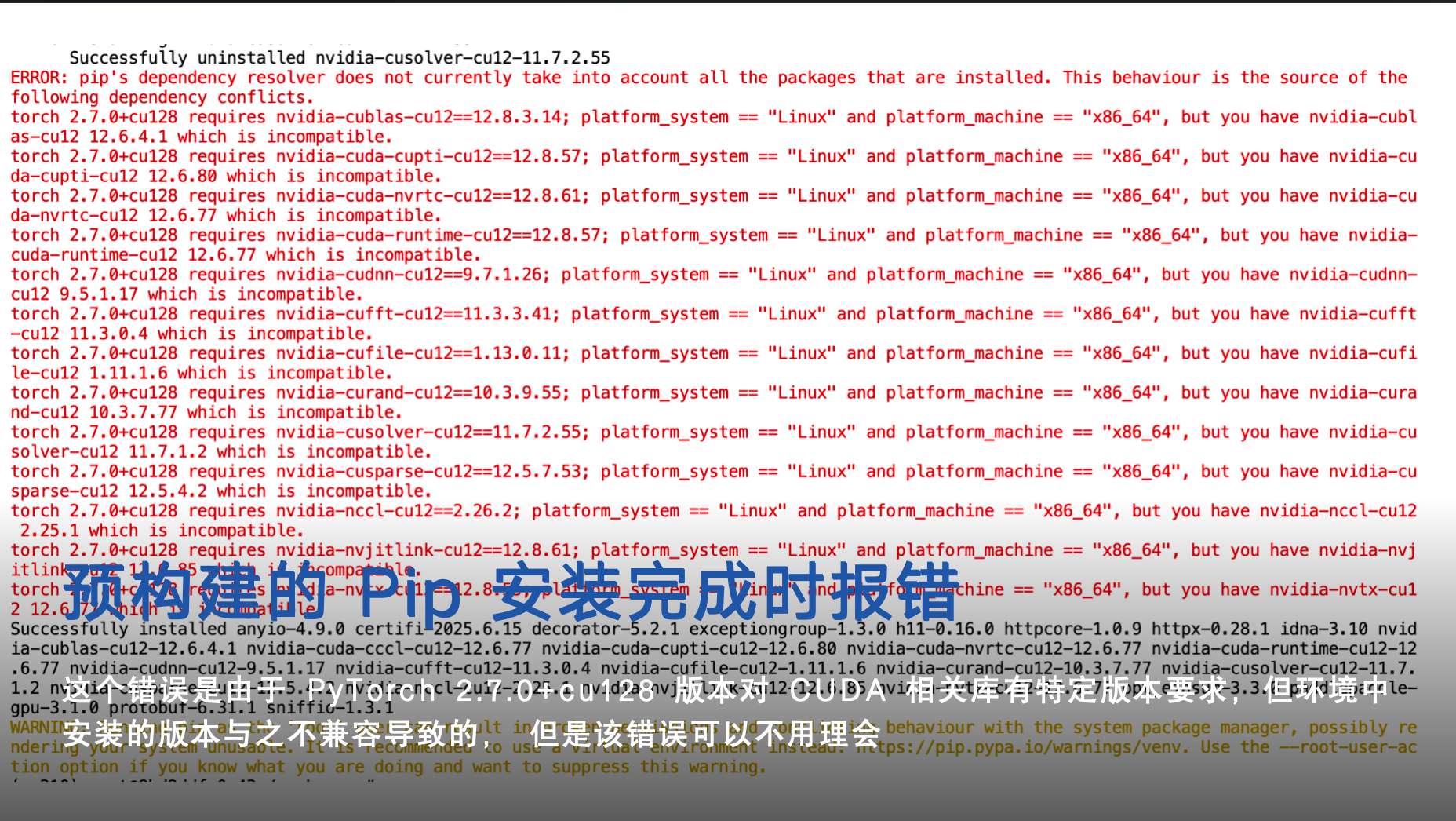
第二次报错
第一次运行模型指令时会报该错,如下图
解决方案:安装 libgomp.so.1
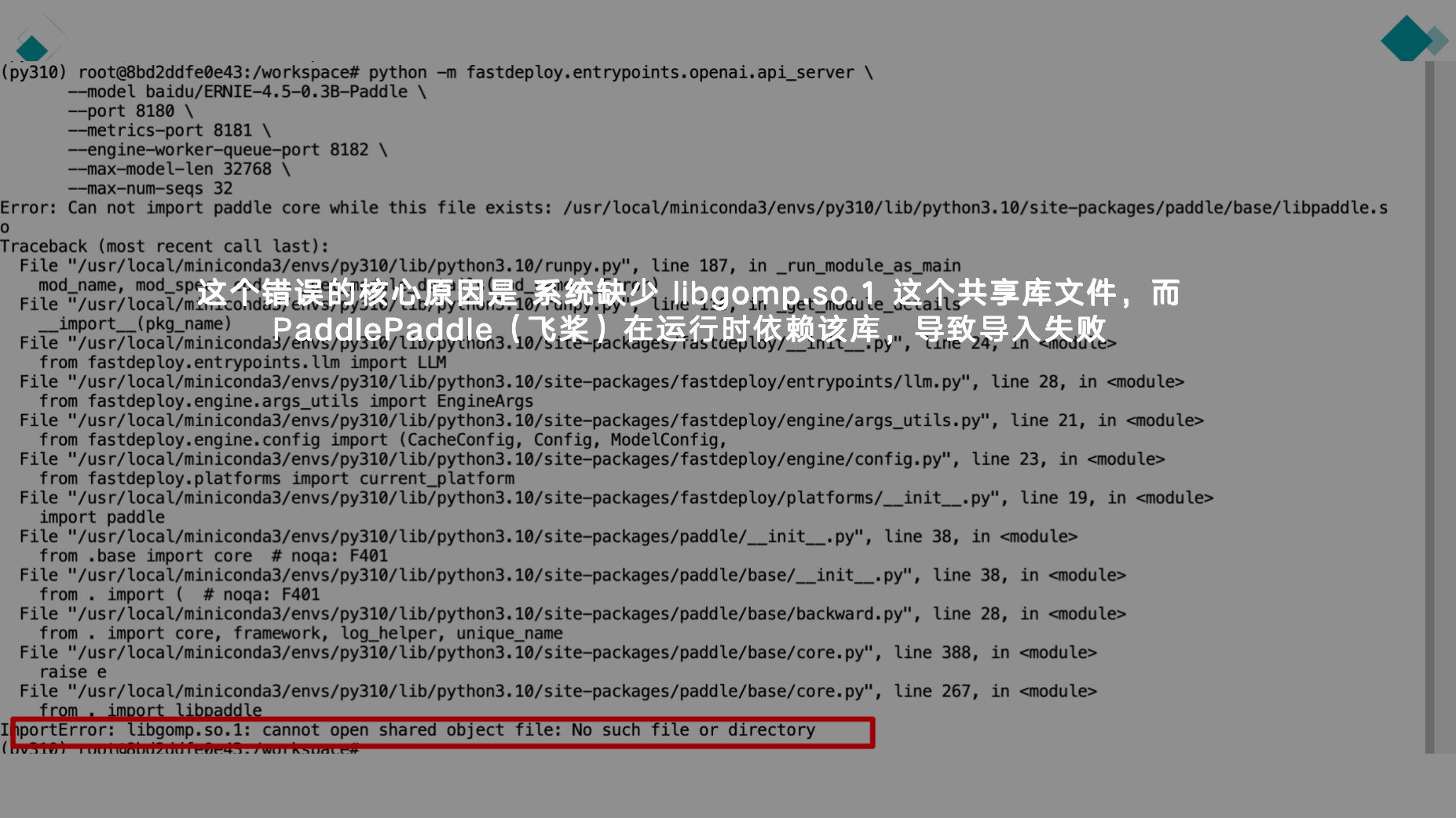
# 更新包列表
apt-get update
# 安装 libgomp1(包含 libgomp.so.1)
apt-get install -y libgomp1
第三次报错
第二次运行模型指令时会报该错,如下图
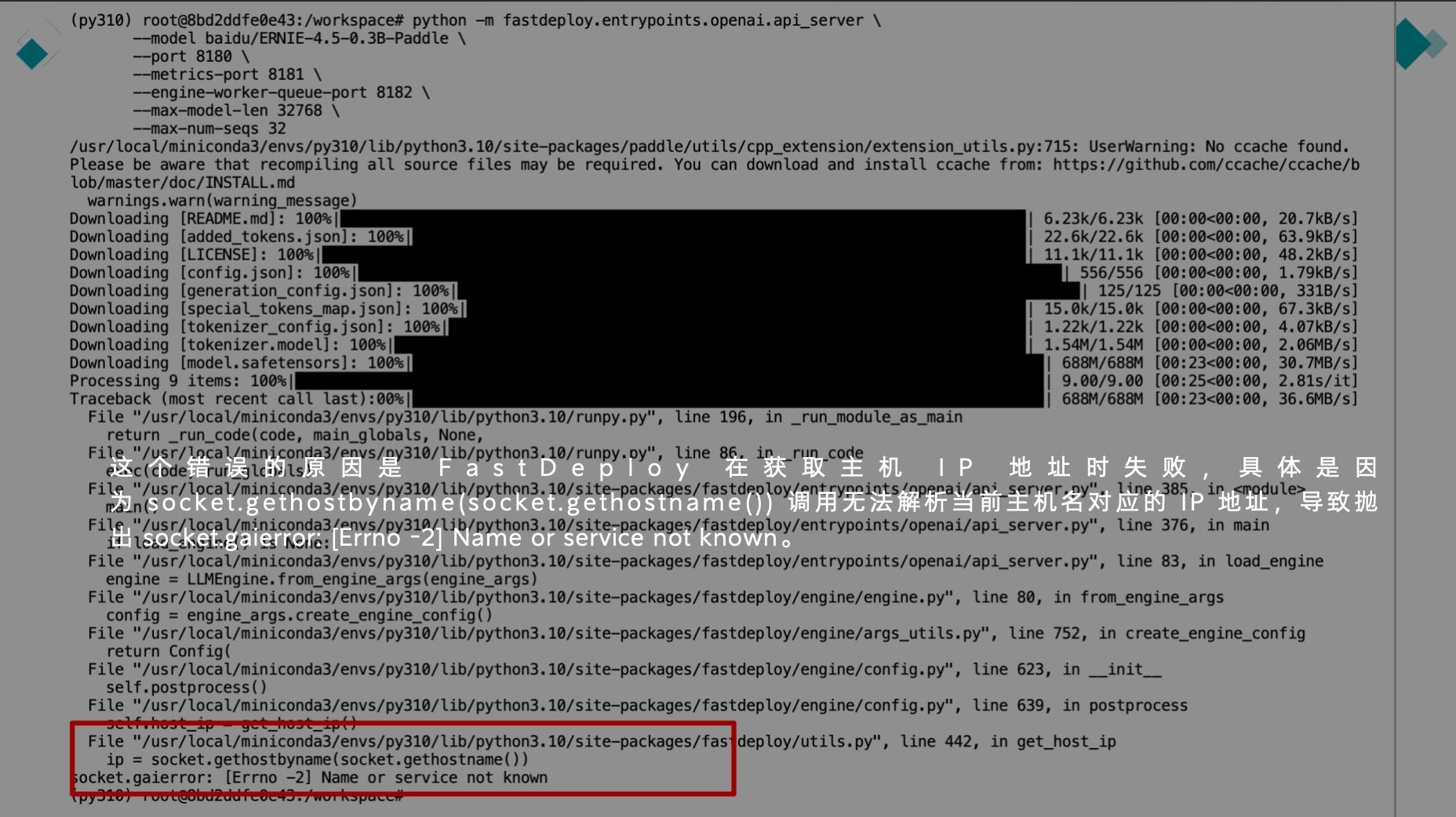
解决方案:
# 查看当前主机名
hostname=$(hostname)
# 将主机名添加到 /etc/hosts
echo "127.0.0.1 $hostname" >> /etc/hosts
测评表单:全面评估各任务类型大模型的表现
接下来,我将对三组模型进行对比测试,分别是:ERNIE-4.5-0.3B-Paddle 模型与 DeepSeek-R1-Distill-Qwen-1.5B 模型、ERNIE-4.5-21B-A3B-Paddle 模型与 DeepSeek-R1-Distill-Qwen-32B 模型、ERNIE-4.5-VL-28B-A3B-Paddle 模型与 Qwen2.5-VL-32B-Instruct 模型。
测试维度、测试内容及测试依据评分标准参考下表格:
完整测评表格参考链接: https://i2i82gjh1i.feishu.cn/sheets/V1s0sICCwhcFZwtacvtced25nSf?from=from_copylink
文本类模型测试脚本
ERNIE-4.5文本类测试 py脚本如下
import requests
import time
import json
# 模型API配置
API_URL = "http://0.0.0.0:8180/v1/chat/completions" # 根据实际情况调整路径
MODEL_NAME = "ernie-4.5-0.3b-paddle" # 模型名称,可从配置文件或API获取
# 用户输入
prompt = "下雨了出门需要带什么"
# 准备请求数据
request_data = {
"model": MODEL_NAME,
"messages": [
{"role": "user", "content": prompt}
],
"temperature": 0.7, # 控制生成的随机性,0.0表示确定性,1.0表示最大随机性
"max_tokens": 512 # 最大生成长度
}
# 记录开始时间
start_time = time.time()
# 发送请求
try:
response = requests.post(
API_URL,
headers={"Content-Type": "application/json"},
data=json.dumps(request_data)
)
response.raise_for_status() # 检查请求是否成功
response_data = response.json()
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
if response.status_code:
print(f"状态码: {response.status_code}")
print(f"响应内容: {response.text}")
exit(1)
# 记录结束时间并计算响应时间
end_time = time.time()
response_time = end_time - start_time
# 提取生成的文本
try:
generated_text = response_data["choices"][0]["message"]["content"]
prompt_tokens = response_data["usage"]["prompt_tokens"]
completion_tokens = response_data["usage"]["completion_tokens"]
total_tokens = response_data["usage"]["total_tokens"]
except (KeyError, IndexError) as e:
print(f"解析响应失败: {e}")
print(f"响应内容: {response_data}")
exit(1)
# 输出结果和统计信息
print(f"使用模型: {MODEL_NAME}")
print("\n===== 生成结果 =====")
print(generated_text)
print("\n===== 性能统计 =====")
print(f"响应时间: {response_time:.2f} 秒")
print(f"提示Token数量: {prompt_tokens}")
print(f"生成Token数量: {completion_tokens}")
print(f"总Token数量: {total_tokens}")
print(f"Token生成速度: {completion_tokens/response_time:.2f} tokens/秒")
DeepSeek-R1-Distill-Qwen 文本类测试py脚本如下
import time
from openai import OpenAI
# 初始化OpenAI客户端
client = OpenAI(
api_key='YOUR_API_KEY',
base_url="http://0.0.0.0:8000/v1"
)
# 获取可用模型
model_name = client.models.list().data[0].id
# 获取用户输入
user_input = ""
# 记录开始时间
start_time = time.time()
# 发送请求
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": user_input}],
temperature = 1,
)
# 计算响应时间
response_time = time.time() - start_time
# 输出结果和统计信息
print("\n===== 生成结果 =====")
print(response.choices[0].message.content)
print("\n===== 性能统计 =====")
print(f"响应时间: {response_time:.2f} 秒")
print(f"提示Token数量: {response.usage.prompt_tokens}")
print(f"生成Token数量: {response.usage.completion_tokens}")
print(f"总Token数量: {response.usage.total_tokens}")
print(f"Token生成速度: {response.usage.completion_tokens/response_time:.2f} tokens/秒")
聚焦小参数模型的效率与基础性能表现
轻量级模型对决:ERNIE-4.5-0.3B-Paddle vs DeepSeek-R1-Distill-Qwen-1.5B
启动ERNIE-4.5-0.3B-Paddle 模型
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-0.3B-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--max-model-len 32768 \
--max-num-seqs 32

启动 DeepSeek-R1-Distill-Qwen-1.5B 模型
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --port 8000
小参数模型测评数据可视化
详细测评内容可参考 https://i2i82gjh1i.feishu.cn/sheets/V1s0sICCwhcFZwtacvtced25nSf?from=from_copylink
侧重中等参数量级下的综合能力较量
中大规模模型比拼:ERNIE-4.5-21B-A3B-Paddle vs DeepSeek-R1-Distill-Qwen-32B
启动ERNIE-4.5-21B-A3B-Paddle 模型
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-21B-A3B-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--max-model-len 32768 \
--max-num-seqs 32

启动 DeepSeek-R1-Distill-Qwen-32B 模型
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --port 8000 -tp 4 --max-model-len 65168
中等参数模型测评数据可视化
详细测评内容可参考 https://i2i82gjh1i.feishu.cn/sheets/V1s0sICCwhcFZwtacvtced25nSf?from=from_copylink
视觉类模型测试脚本
ERNIE-4.5-VL-28B-A3B-Paddle 脚本如下
import requests
import time
import json
import base64
import os
# ==================== 用户配置区域 ====================
API_URL = "http://localhost:8180/v1/chat/completions" # API地址
MODEL_NAME = "baidu/ERNIE-4.5-VL-28B-A3B-Paddle" # 模型名称
# 图片路径配置(修改为你的图片路径)
IMAGE1_PATH = "./image/图片中太阳在东边.png" # 第一张图片路径(必填)
IMAGE2_PATH = "" # 第二张图片路径(选填,留空则只处理第一张,例如:IMAGE2_PATH = "")
# 提示词配置(留空则根据图片数量自动生成)
USER_PROMPT = "判断 “图片中太阳在东边” 是否正确"
# 模型参数配置
TEMPERATURE = 0.7 # 生成温度(0.0-1.0)
MAX_TOKENS = 1024 # 最大生成长度
ENABLE_THINKING = True # 是否启用思考过程
# ====================================================
def encode_image_to_base64(image_path):
"""将本地图片编码为Base64格式"""
if not image_path:
return None
if not os.path.exists(image_path):
raise FileNotFoundError(f"图片文件不存在: {image_path}")
with open(image_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return encoded_string
def main():
# 初始化提示词(避免未赋值引用)
user_prompt = USER_PROMPT # 先用全局配置初始化
image_contents = []
try:
# 添加第一张图片
image1_base64 = encode_image_to_base64(IMAGE1_PATH)
image_contents.append({"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image1_base64}"}})
# 检查是否有第二张图片
has_second_image = False
if IMAGE2_PATH and os.path.exists(IMAGE2_PATH):
has_second_image = True
# 添加第二张图片
image2_base64 = encode_image_to_base64(IMAGE2_PATH)
image_contents.append({"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image2_base64}"}})
# 自动生成提示词(如果用户未填写)
if not user_prompt.strip():
if has_second_image:
user_prompt = "对比分析这两张图片的异同点"
else:
user_prompt = "详细描述这张图片的内容"
# 添加用户提示词到请求内容
image_contents.append({"type": "text", "text": user_prompt})
except Exception as e:
print(f"图片处理错误: {e}")
return
# 准备请求数据
request_data = {
"model": MODEL_NAME,
"messages": [
{
"role": "user",
"content": image_contents
}
],
"temperature": TEMPERATURE,
"max_tokens": MAX_TOKENS,
"metadata": {"enable_thinking": ENABLE_THINKING}
}
# 记录开始时间
start_time = time.time()
# 发送请求
try:
response = requests.post(
API_URL,
headers={"Content-Type": "application/json"},
data=json.dumps(request_data)
)
response.raise_for_status() # 检查请求是否成功
response_data = response.json()
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
if 'response' in locals() and response.status_code:
print(f"状态码: {response.status_code}")
print(f"响应内容: {response.text}")
return
# 记录结束时间并计算响应时间
end_time = time.time()
response_time = end_time - start_time
# 提取生成的文本
try:
generated_text = response_data["choices"][0]["message"]["content"]
prompt_tokens = response_data["usage"]["prompt_tokens"]
completion_tokens = response_data["usage"]["completion_tokens"]
total_tokens = response_data["usage"]["total_tokens"]
except (KeyError, IndexError) as e:
print(f"解析响应失败: {e}")
print(f"响应内容: {response_data}")
return
# 输出结果和统计信息
print(f"使用模型: {MODEL_NAME}")
print("\n===== 生成结果 =====")
print(generated_text)
print("\n===== 性能统计 =====")
print(f"响应时间: {response_time:.2f} 秒")
print(f"提示Token数量: {prompt_tokens}")
print(f"生成Token数量: {completion_tokens}")
print(f"总Token数量: {total_tokens}")
print(f"Token生成速度: {completion_tokens/response_time:.2f} tokens/秒")
if __name__ == "__main__":
main()
Qwen2.5-VL-32B-Instruct 脚本如下
from openai import OpenAI
import base64
import time
import os
# ==================== 用户配置区域 ====================
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
model_name = "/model/ModelScope/Qwen/Qwen2.5-VL-32B-Instruct"
# 图片路径配置(修改为你的图片路径)
IMAGE1_PATH = "./image/是否为艾菲尔.jpeg" # 第一张图片路径(必填)
IMAGE2_PATH = "" # 第二张图片路径(选填,留空则只处理第一张)
# 自定义提示词(留空则根据图片数量自动生成)
USER_PROMPT = " 图片中的艾菲尔铁塔拍摄于白天, 是否正确?"
# 模型参数配置
TEMPERATURE = 0.7 # 生成温度(0.0-1.0)
MAX_TOKENS = 2048 # 最大生成长度
# ====================================================
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
def encode_image(image_path):
"""将图片编码为Base64格式"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def main():
# 准备图片内容
content = []
# 添加第一张图片
content.append({"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{encode_image(IMAGE1_PATH)}"}})
# 如果有第二张图片,添加第二张
has_two_images = bool(IMAGE2_PATH and os.path.exists(IMAGE2_PATH))
if has_two_images:
content.append({"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{encode_image(IMAGE2_PATH)}"}})
# 自动生成提示词(如果用户未指定)
user_prompt = USER_PROMPT
if not user_prompt:
if has_two_images:
user_prompt = "对比分析这两张图片的异同点"
else:
user_prompt = "详细描述这张图片的内容"
# 添加文本提示
content.append({"type": "text", "text": user_prompt})
# 记录开始时间
start_time = time.time()
# 发送请求
response = client.chat.completions.create(
model=model_name,
messages=[{
"role": "user",
"content": content
}],
temperature=TEMPERATURE,
max_tokens=MAX_TOKENS
)
# 记录结束时间并计算响应时间
end_time = time.time()
response_time = end_time - start_time
# 提取结果
generated_text = response.choices[0].message.content
prompt_tokens = response.usage.prompt_tokens
completion_tokens = response.usage.completion_tokens
total_tokens = response.usage.total_tokens
# 输出结果
print(f"使用模型: {model_name}")
print("\n===== 生成结果 =====")
print(generated_text)
print("\n===== 性能统计 =====")
print(f"响应时间: {response_time:.2f} 秒")
print(f"提示Token数量: {prompt_tokens}")
print(f"生成Token数量: {completion_tokens}")
print(f"总Token数量: {total_tokens}")
print(f"Token生成速度: {completion_tokens/response_time:.2f} tokens/秒")
if __name__ == "__main__":
main()
专注跨模态任务处理能力的深度对比
视觉语言模型交锋:ERNIE-4.5-VL-28B-A3B-Paddle vs Qwen2.5-VL-32B-Instruct
启用ERNIE-4.5-VL-28B-A3B-Paddle 模型
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-VL-28B-A3B-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--max-model-len 32768 \
--enable-mm \
--reasoning-parser ernie-45-vl \
--max-num-seqs 32
启用 Qwen2.5-VL-32B-Instruct 模型
vllm serve /model/ModelScope/Qwen/Qwen2.5-VL-32B-Instruct --port 8000 -tp 4 --max-model-len=20480 --gpu-memory-utilization 0.85 --allowed-local-media-path /root --mm_processor_kwargs '{"max_pixels": 589824,"min_pixels": 3136}'
跨模态任务模型测评数据可视化
详细测评内容可参考 https://i2i82gjh1i.feishu.cn/sheets/V1s0sICCwhcFZwtacvtced25nSf?from=from_copylink
模型速度与性能综合分析
1. 小型模型综合对比分析
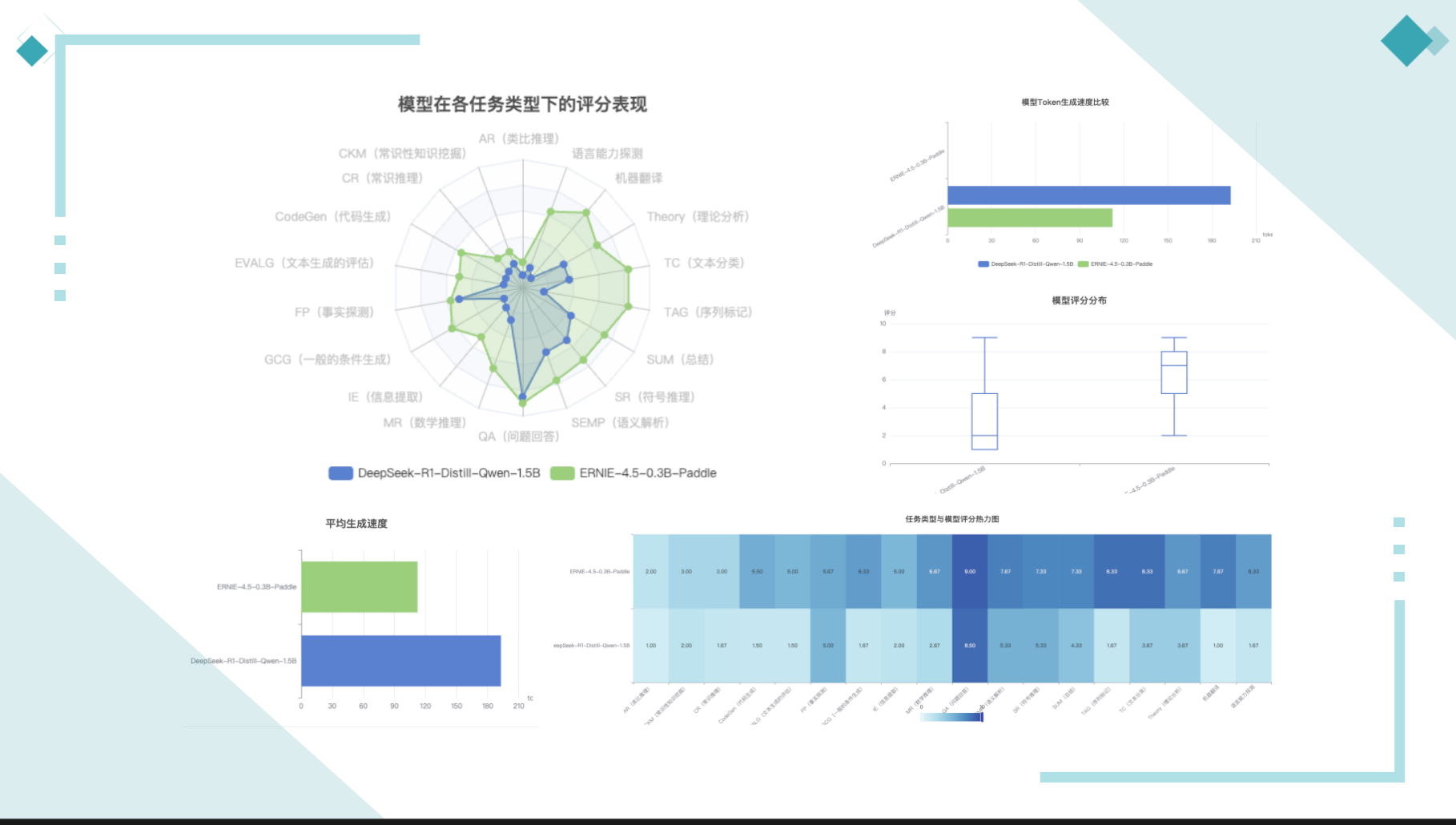
在小型模型的对比中,DeepSeek-R1-Distill-Qwen-1.5B和ERNIE-4.5-0.3B-Paddle展现出明显的速度差异:
| 模型名称 | 平均Token生成速度 | 参数规模 |
|---|---|---|
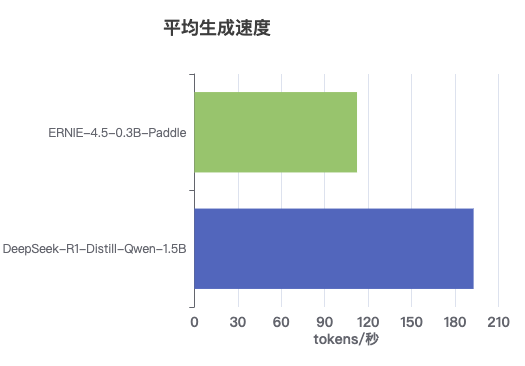
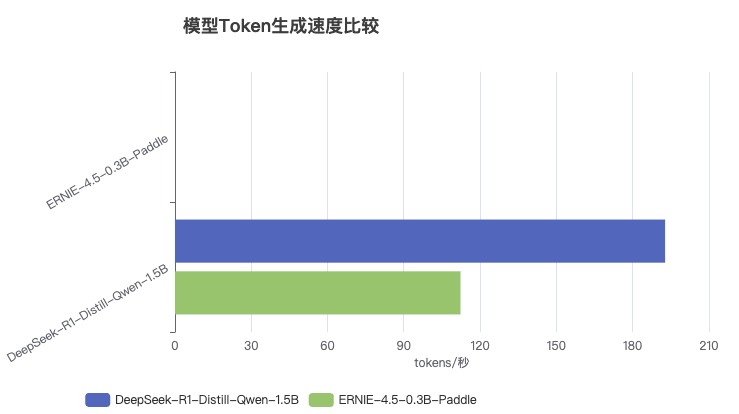
| DeepSeek-R1-Distill-Qwen-1.5B | 约194 tokens/秒 | 1.5B |
| ERNIE-4.5-0.3B-Paddle | 约112 tokens/秒 | 0.3B |
生成速度对比
┌─────────────────────────────────────────────────────┐
│ DeepSeek-R1-Distill-Qwen-1.5B │████████████████████│ ~194 tokens/秒
├─────────────────────────────────────────────────────┤
│ ERNIE-4.5-0.3B-Paddle │███████████░░░░░░░░░│ ~112 tokens/秒
└─────────────────────────────────────────────────────┘
速度差异分析:
- DeepSeek模型生成速度约为ERNIE-4.5小型模型的1.7倍
- 尽管参数量更大,DeepSeek模型在推理效率上具有明显优势
- ERNIE-4.5模型虽速度较慢,但其参数量仅为DeepSeek的1/5
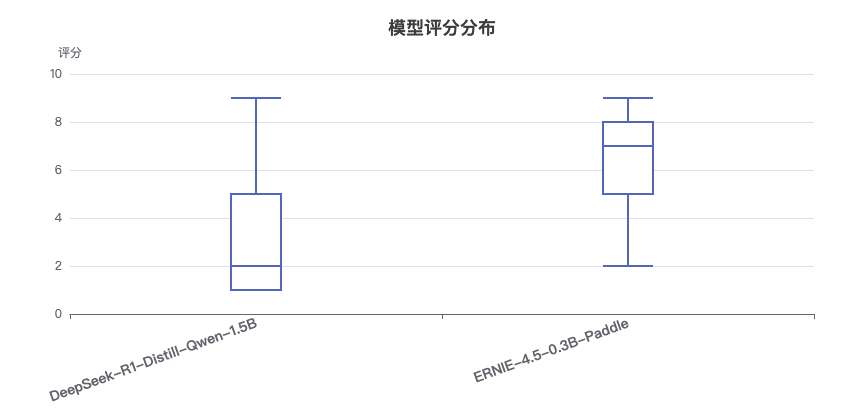
评分分布特征
评分分布 (1-10分)
DeepSeek-R1-Distill-Qwen-1.5B
1分 ██████ (6项)
2分 ████ (4项)
3分 ██ (2项)
4分 ██ (2项)
5分 ██ (2项)
6分 █ (1项)
7分+ █ (1项)
ERNIE-4.5-0.3B-Paddle
1-4分
5分 █ (1项)
6分 ███ (3项)
7分 ████ (4项)
8分 ████ (4项)
9分 ██ (2项)
分布特点:
- DeepSeek模型评分呈左偏分布,大多集中在低分区间
- ERNIE-4.5模型评分呈右偏分布,大多集中在高分区间
- DeepSeek在10项任务上得分≤3分,而ERNIE-4.5在所有任务上得分≥5分
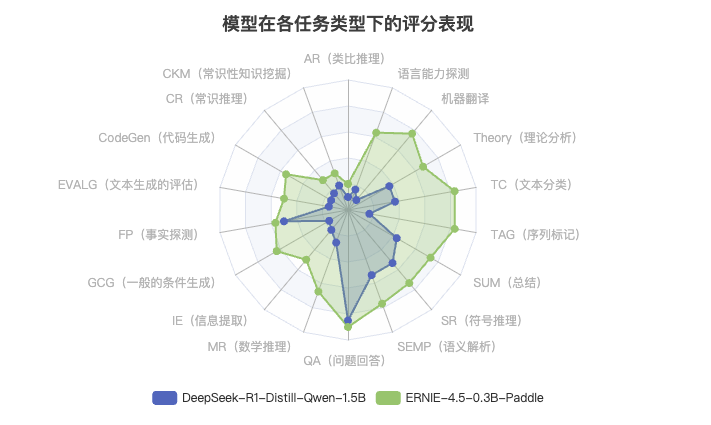
性能亮点分析
ERNIE-4.5-0.3B 优势任务
-
机器翻译 (+6.7分)
- 评分:7.7分 vs 1.0分
- 优势显著,尽管参数量更小
-
序列标记 (+6.6分)
- 评分:8.3分 vs 1.7分
- 在标记任务上表现卓越
-
文本分类 (+4.6分)
- 评分:8.3分 vs 3.7分
- 分类准确度明显更高
-
条件生成 (+4.6分)
- 评分:6.3分 vs 1.7分
- 生成质量大幅领先
DeepSeek-1.5B 相对强项
-
问题回答
- 评分:8.5分 (最高分项)
- 与ERNIE差距最小(仅0.5分)
-
符号推理
- 评分:5.3分
- 在复杂推理上有一定能力
-
事实探测
- 评分:5.0分
- 在事实判断上表现尚可
-
语义解析
- 评分:5.3分
- 解析能力相对较好
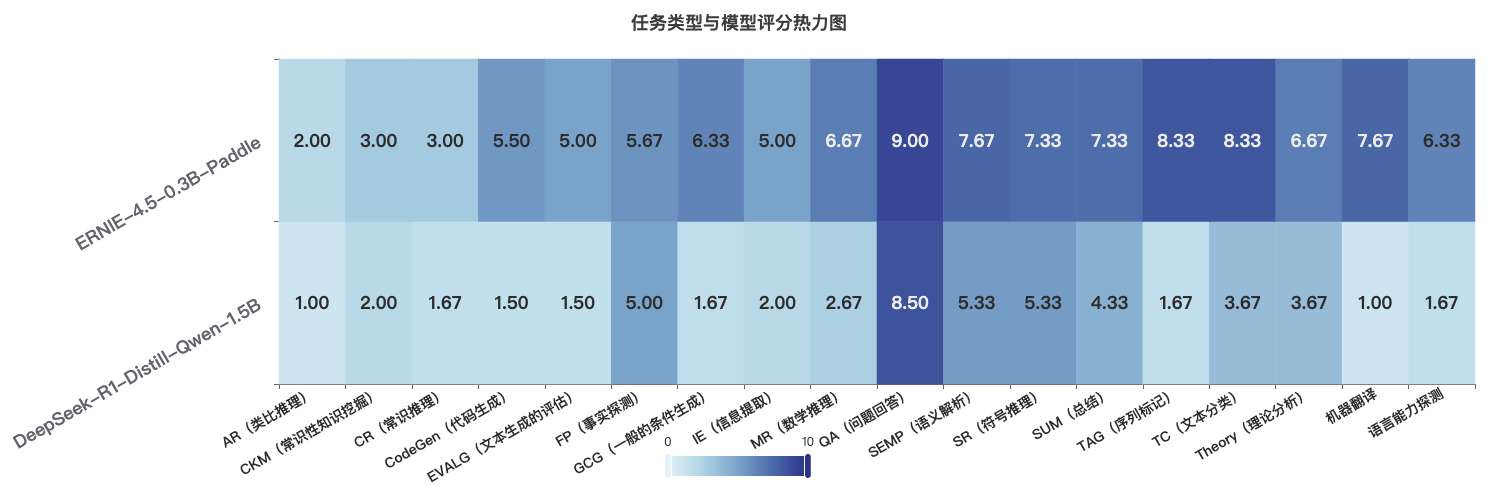
各任务类型评分对比
| 任务类型 | DeepSeek-1.5B | ERNIE-0.3B | 差异 |
|---|---|---|---|
| AR(类比推理) | 1.0 | 2.0 | +1.0 |
| CKM(常识性知识挖掘) | 2.0 | 3.0 | +1.0 |
| CR(常识推理) | 1.7 | 3.0 | +1.3 |
| CodeGen(代码生成) | 1.5 | 5.5 | +4.0 |
| EVALG(文本生成评估) | 1.5 | 5.0 | +3.5 |
| FP(事实探测) | 5.0 | 5.7 | +0.7 |
| GCG(条件生成) | 1.7 | 6.3 | +4.6 |
| IE(信息提取) | 2.0 | 5.0 | +3.0 |
| MR(数学推理) | 2.7 | 6.7 | +4.0 |
| QA(问题回答) | 8.5 | 9.0 | +0.5 |
| SEMP(语义解析) | 5.3 | 7.7 | +2.4 |
| SR(符号推理) | 5.3 | 7.3 | +2.0 |
| SUM(总结) | 4.3 | 7.3 | +3.0 |
| TAG(序列标记) | 1.7 | 8.3 | +6.6 |
| TC(文本分类) | 3.7 | 8.3 | +4.6 |
| Theory(理论分析) | 3.7 | 6.7 | +3.0 |
| 机器翻译 | 1.0 | 7.7 | +6.7 |
| 语言能力探测 | 1.7 | 6.3 | +4.6 |
分析要点:
- DeepSeek模型在速度上有明显优势,平均生成速度约为ERNIE-4.5小型模型的1.7倍
- 然而,从评分数据来看,ERNIE-4.5-0.3B在多数任务类型上获得了更高的评分,特别是在以下任务中表现突出:
- 数学推理(MR):平均评分6.7 vs 2.7
- 序列标记(TAG):平均评分8.3 vs 1.7
- 文本分类(TC):平均评分8.3 vs 3.7
- 这表明ERNIE-4.5-0.3B虽然参数量更小、速度较慢,但在实际应用质量上具有明显优势 ,挑战了"更大即更好"的传统认知
2. 中型模型综合对比分析
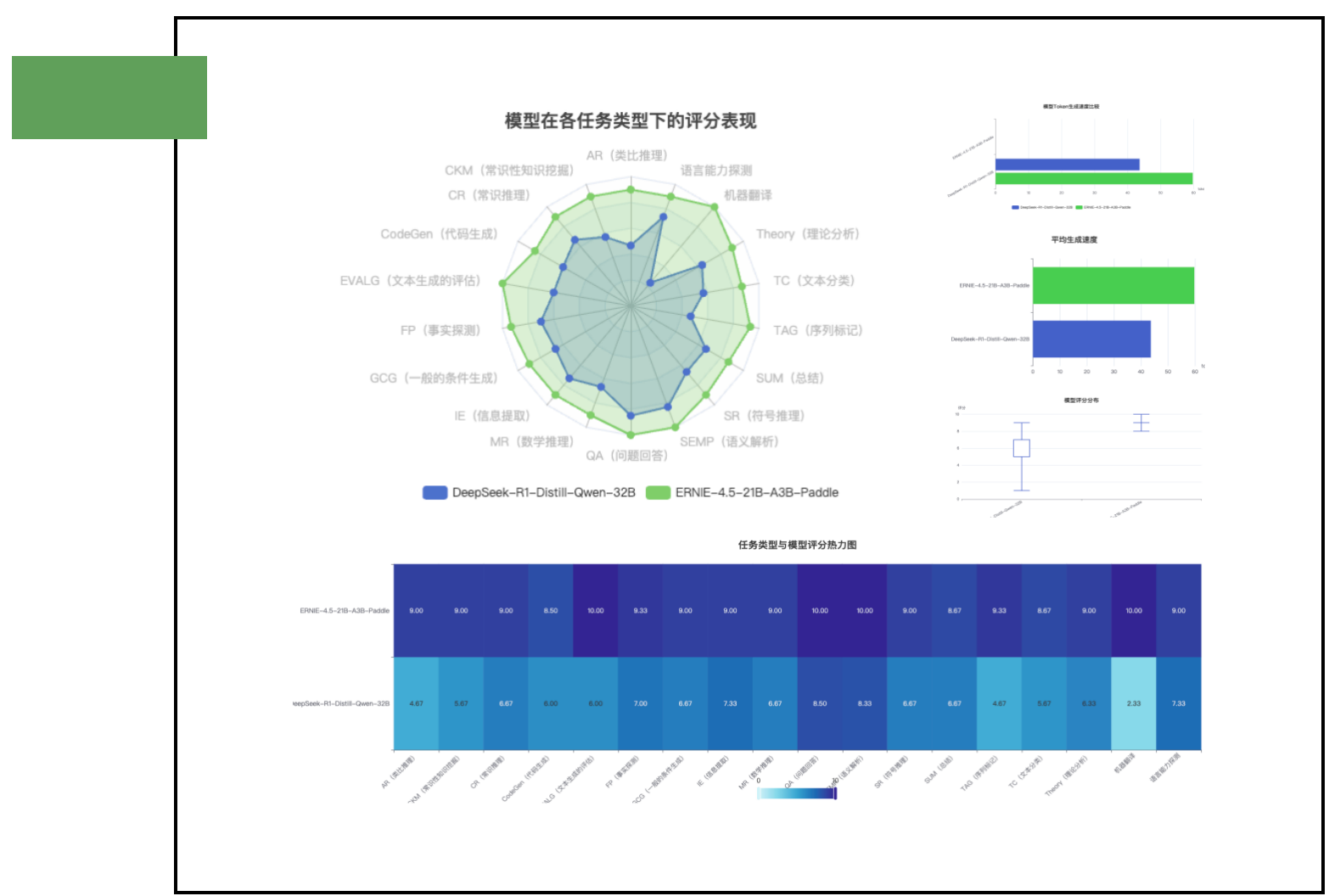
核心发现:ERNIE-21B(21B参数)在多项任务中全面超越DeepSeek-32B(32B参数),不仅以更少参数实现更高性能(打破"规模至上"认知),更在生成速度与输出质量上实现双突破;其卓越的任务泛化能力(尤其在机器翻译等薄弱环节显著优于对手)揭示了预训练策略的关键作用,同时证明了21B-32B参数规模在性能与实用性上的最佳平衡,为高效AI部署提供了新范式。
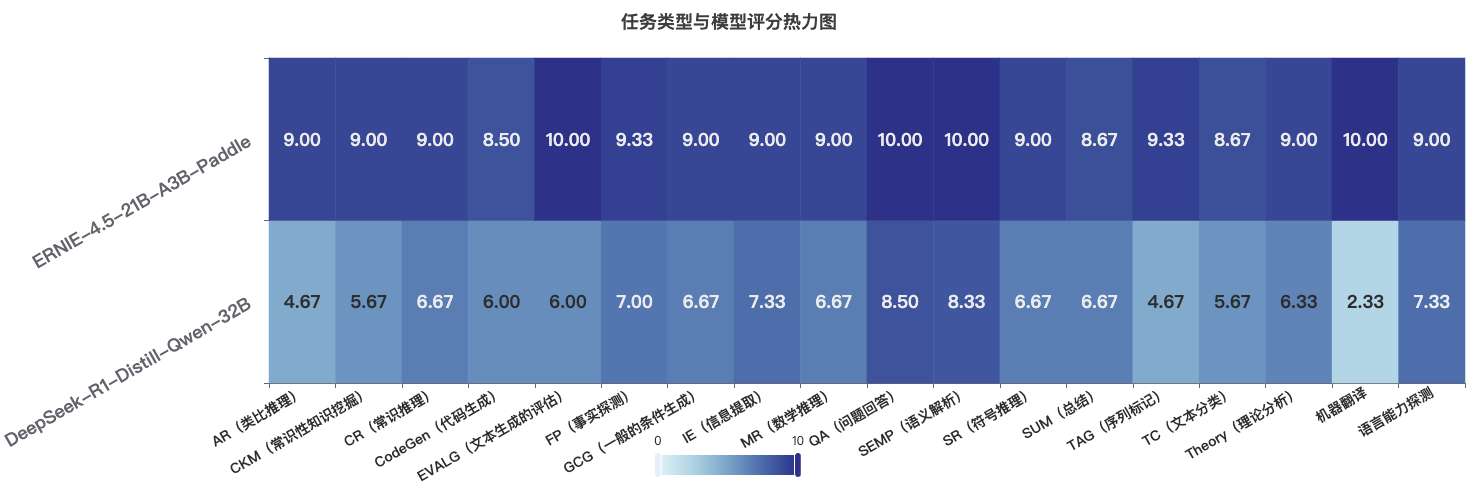
热力图揭示的关键信息:
- 颜色梯度:深蓝色代表高分(8-10分),浅蓝色代表中低分(4-7分),最浅色代表低分(1-3分)
- 模式识别:ERNIE-21B模型在热力图上呈现出大面积的深色区域,表明其在大多数任务上都获得了高分
- 对比鲜明:DeepSeek-32B模型的热力图呈现出明显的色彩不均,少数深色区域与大量浅色区域并存
典型任务表现对比:
| 任务类型 | DeepSeek-32B | ERNIE-21B | 性能差异分析 |
|---|---|---|---|
| AR(类比推理) | 4.7 | 9.0 | ERNIE在抽象思维上更胜一筹 |
| CodeGen(代码生成) | 6.0 | 8.5 | 两者都具备代码能力,ERNIE更优 |
| MR(数学推理) | 6.7 | 9.0 | ERNIE在复杂推理上更为出色 |
| QA(问题回答) | 8.5 | 10.0 | 两者都擅长问答,ERNIE略胜 |
| 机器翻译 | 2.3 | 10.0 | DeepSeek在翻译任务上表现极差 |
热力图模式解读:
- ERNIE-21B的热力图呈现出高度一致的深色区域,表明其在各类任务上都保持了高水平表现
- DeepSeek-32B的热力图呈现出明显的"热冷不均",在QA和SEMP等任务上表现较好,但在机器翻译等任务上表现极差
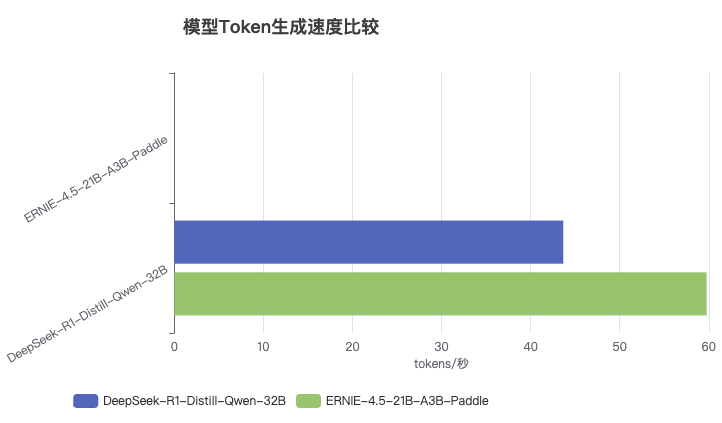
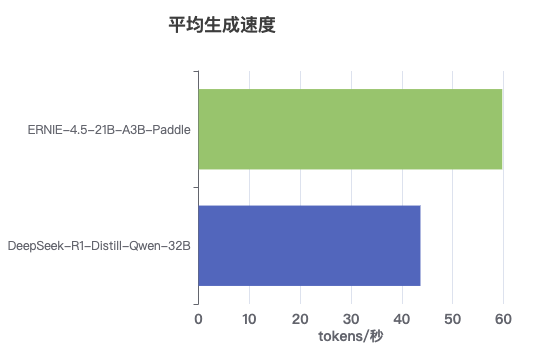
速度数据详解:
- DeepSeek-R1-Distill-Qwen-32B:平均 ~43.8 tokens/秒
- ERNIE-4.5-21B-A3B-Paddle:平均 ~59.8 tokens/秒
速度差异的实际影响分析:
-
用户体验影响:
- 对于生成2000个token的长文本:
- DeepSeek-32B:约45.7秒
- ERNIE-21B:约33.4秒
- 差距约12.3秒,在生成长文本时用户等待时间差异明显
- 对于生成2000个token的长文本:
-
系统吞吐量影响:
- 在相同硬件条件下,ERNIE-21B的服务吞吐量理论上可以比DeepSeek-32B高37%
- 这对于需要处理大量并发请求的商业服务来说是显著优势
-
计算资源效率:
- ERNIE-21B不仅参数量较小(21B vs 32B),而且推理速度更快
- 这意味着在相同硬件条件下,ERNIE-21B能够提供更高的性能/成本比
速度与参数量的反比关系:
- 通常情况下,参数量更大的模型推理速度更慢,但ERNIE-21B打破了这一规律
- 这表明模型架构设计、参数分布和计算优化可能比简单的参数规模更重要
- ERNIE-21B可能采用了更高效的注意力机制或更优化的计算图结构
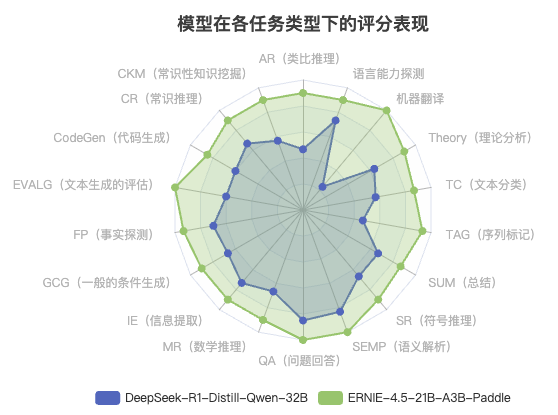
核心发现:
- ERNIE-4.5-21B-A3B-Paddle(绿色区域)在所有任务类型上形成了更大、更均匀的覆盖面积,表明其全面优势
- DeepSeek-R1-Distill-Qwen-32B(蓝色区域)在QA(问题回答)和SEMP(语义解析)等少数任务上表现较好,但整体覆盖面积明显小于ERNIE模型
- 最大性能差距出现在机器翻译、TAG(序列标记)和EVALG(文本生成评估)任务上
- 最小性能差距出现在QA(问题回答)任务上,两个模型在此领域表现接近
任务表现量化对比:
| 任务类型 | DeepSeek-32B | ERNIE-21B | 差距 | 特点分析 |
|---|---|---|---|---|
| 机器翻译 | 2.3 | 10.0 | +7.7 | ERNIE完全碾压 |
| TAG(序列标记) | 4.7 | 9.3 | +4.6 | ERNIE显著领先 |
| EVALG(文本生成评估) | 6.0 | 10.0 | +4.0 | ERNIE满分表现 |
| QA(问题回答) | 8.5 | 10.0 | +1.5 | 双方都表现优秀 |
| SEMP(语义解析) | 8.3 | 10.0 | +1.7 | 高水平竞争 |
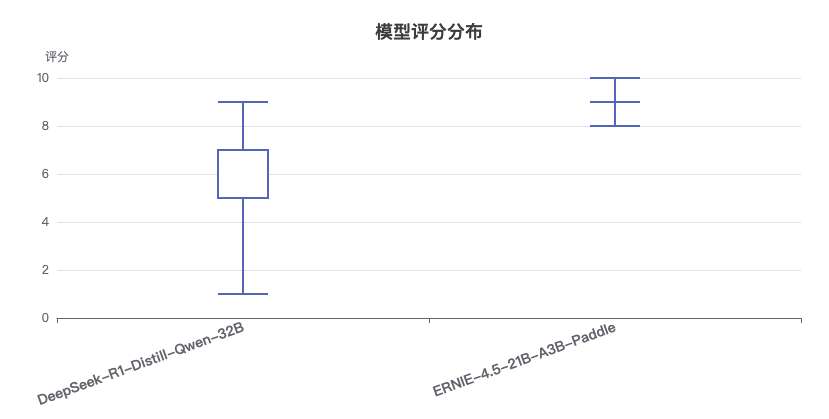
箱线图统计解读:
-
中位数对比:
- DeepSeek-R1-Distill-Qwen-32B:中位数约为6.3分
- ERNIE-4.5-21B-A3B-Paddle:中位数约为9.0分
- 差距达2.7分,表明ERNIE模型在大多数任务上都表现更优
-
四分位距(IQR)分析:
- DeepSeek-32B:IQR较大(约2.5分),表明性能波动较大
- ERNIE-21B:IQR较小(约1.0分),表明性能更加稳定一致
-
极值分析:
- DeepSeek-32B:最低分2.3分(机器翻译),最高分8.5分(QA问答)
- ERNIE-21B:最低分8.5分(多个任务),最高分10.0分(多个任务)
- 极值差异凸显了两个模型在任务适应性上的巨大差距
-
离群值观察:
- DeepSeek-32B在机器翻译任务上的表现(2.3分)可视为离群值,明显低于其他任务
- ERNIE-21B没有明显的离群值,表现稳定
分布特征总结:
- ERNIE-21B的评分分布集中在高分区间(8-10分),且分布紧凑,表明其在各类任务上都保持高水平
- DeepSeek-32B的评分分布较为分散(2-8分),表明其在不同任务上的表现差异较大
- 两个模型的箱线图几乎没有重叠区域,凸显了ERNIE-21B的全面优势
详细测评内容可参考 https://i2i82gjh1i.feishu.cn/sheets/V1s0sICCwhcFZwtacvtced25nSf?from=from_copylink
3. 多模态模型综合对比分析
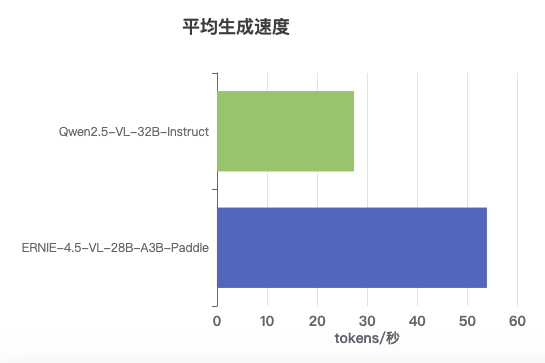
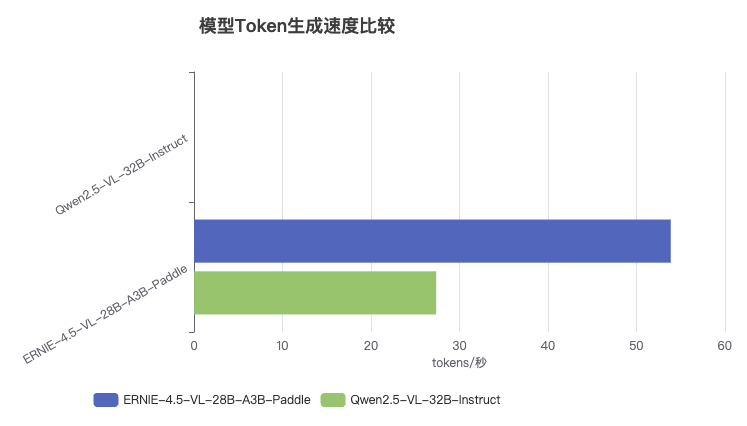
关键数据:
- Qwen2.5-VL-32B-Instruct:约53.9 tokens/秒
- ERNIE-4.5-VL-28B-A3B-Paddle:约26.9 tokens/秒
- 速度比:Qwen2.5-VL模型速度约为ERNIE-4.5-VL模型的2倍
速度差异原因分析:
-
架构优化程度:
- Qwen2.5-VL模型可能采用了更高效的多模态融合架构
- ERNIE-4.5-VL模型在处理视觉和文本信息的融合上可能存在效率瓶颈
-
推理优化水平:
- Qwen2.5-VL在推理引擎优化上可能投入了更多工程资源
- 两个模型的部署环境和优化配置可能存在差异
-
参数利用效率:
- 尽管Qwen2.5-VL参数量略大(32B vs 28B),但其推理速度更快,表明其可能有更高效的参数利用方式
- 这表明参数量并不是决定推理速度的唯一因素

核心发现:
- ERNIE-4.5-VL-28B-A3B-Paddle(蓝色区域)在三个多模态任务上形成了更大的覆盖面积,表明其整体性能全面领先
- Qwen2.5-VL-32B-Instruct(绿色区域)在所有任务上覆盖面积较小,特别是在多模态接地(MG)任务上表现较弱
- 最大差距出现在多模态接地(MG)和视觉问题回答(VQA)任务上
- 最小差距出现在视觉事实探测(VFP)任务上,两个模型差距相对较小
任务表现对比:
| 任务类型 | ERNIE-4.5-VL | Qwen2.5-VL | 评分差距 |
|---|---|---|---|
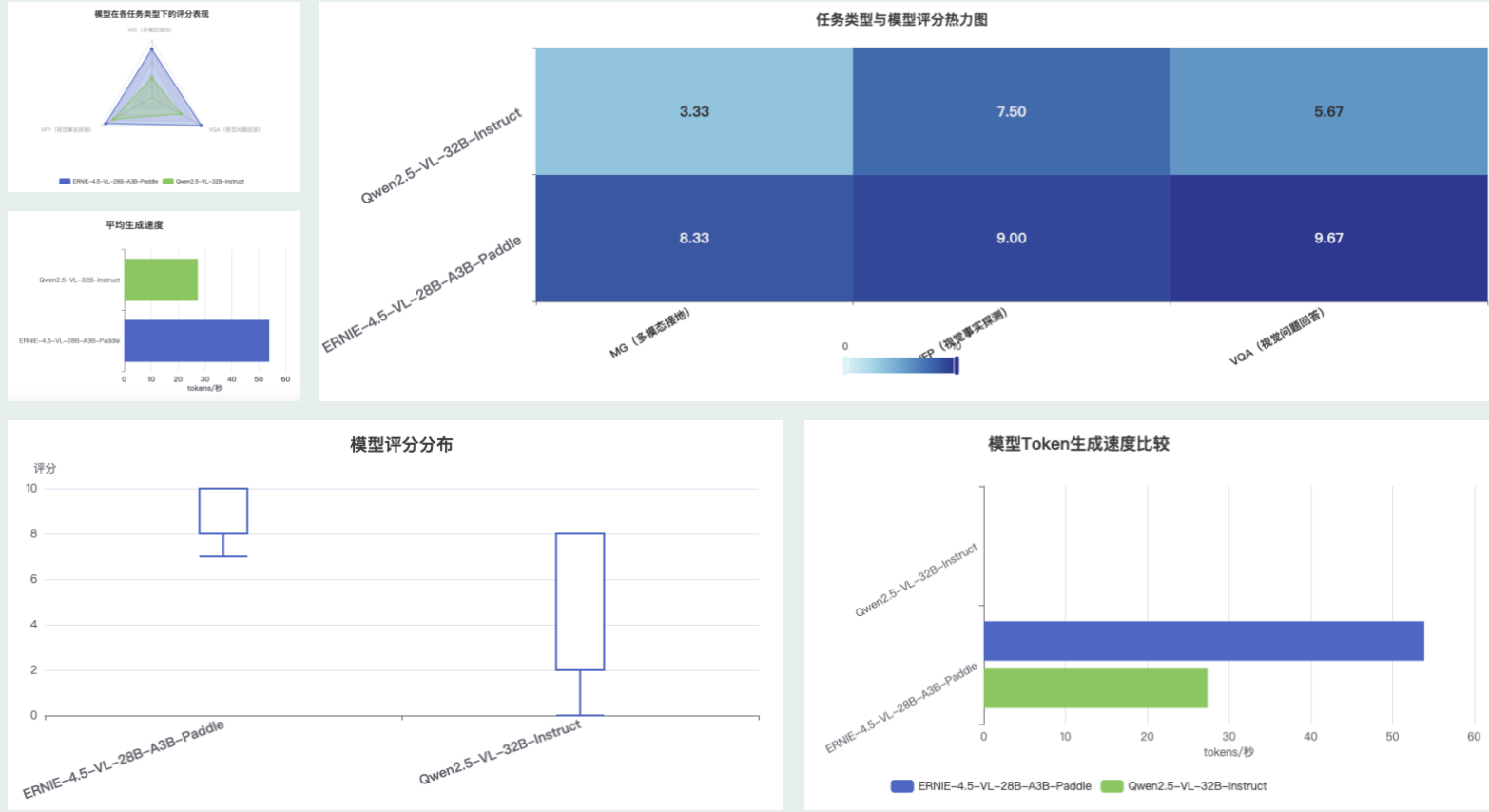
| MG(多模态接地) | 8.3 | 3.3 | +5.0分 |
| VFP(视觉事实探测) | 9.0 | 7.5 | +1.5分 |
| VQA(视觉问题回答) | 9.7 | 5.7 | +4.0分 |
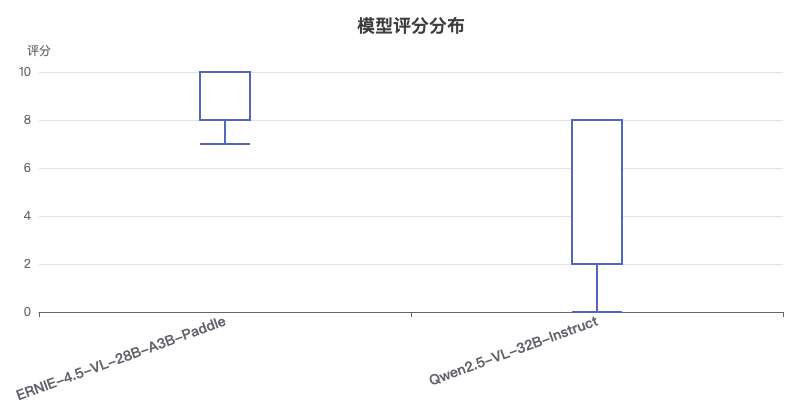
箱线图揭示的关键信息:
-
中位数差异:
- ERNIE-4.5-VL-28B-A3B-Paddle:中位数约为9.0分
- Qwen2.5-VL-32B-Instruct:中位数约为5.0分
- 差距显著,达4分之多
-
分布范围:
- ERNIE-4.5-VL模型:评分范围约为8-10分,集中在高分区间
- Qwen2.5-VL模型:评分范围约为0-8分,分布更加分散
-
四分位差:
- ERNIE-4.5-VL模型:四分位差较小,表明在各类任务上表现稳定
- Qwen2.5-VL模型:四分位差较大,表明在不同任务上表现波动较大
-
异常值:
- Qwen2.5-VL模型存在评分为0的异常值,表明在某些测试样例上可能完全失效
分布特征总结:
- ERNIE-4.5-VL模型的评分分布明显高于Qwen2.5-VL模型,且更加集中在高分区间
- Qwen2.5-VL模型的评分分布更加分散,表明其在不同任务和样例上的表现差异较大
- ERNIE-4.5-VL模型展现出更好的通用多模态能力,在各类任务上都能保持高水平
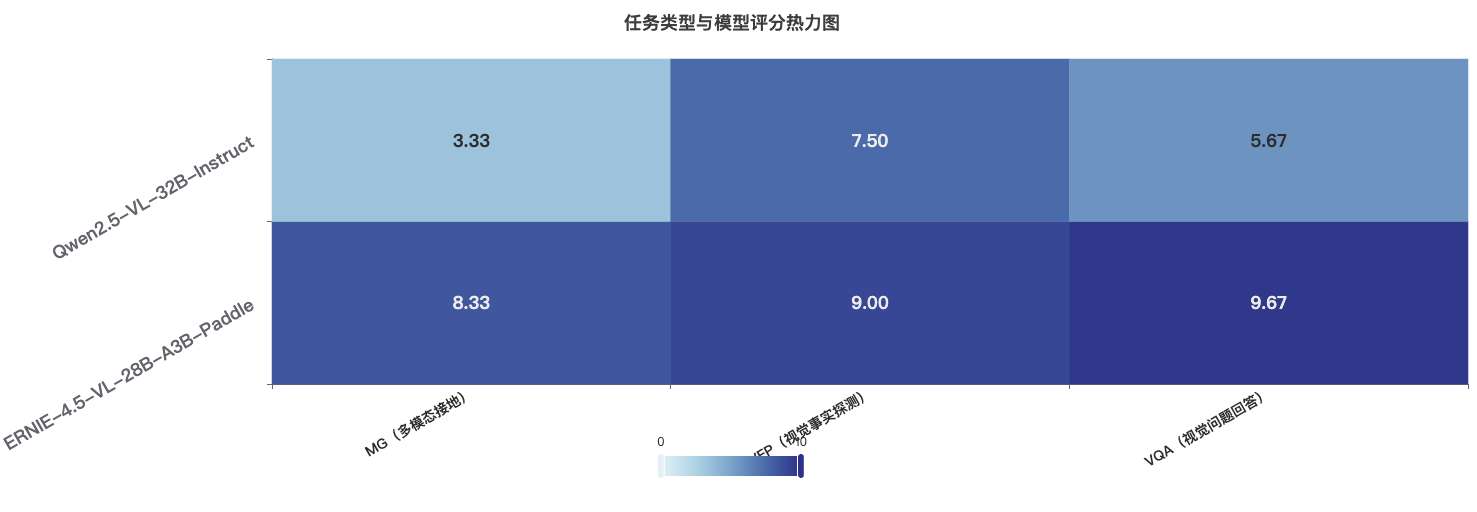
热力图揭示:
- 颜色深浅代表评分高低,越深色表示评分越高
- 纵向对比显示ERNIE-4.5-VL模型在所有多模态任务上都获得了更高的评分
- 横向对比显示不同任务类型的难度差异和模型特长
- 评分集中度表明ERNIE-4.5-VL在各任务上表现更加稳定一致
模型在关键任务上的表现:
| 任务类型 | ERNIE-4.5-VL | Qwen2.5-VL | 差异分析 |
|---|---|---|---|
| MG(多模态接地) | 8.3 | 3.3 | ERNIE在多模态理解与生成上优势显著,差距达5.0分 |
| VFP(视觉事实探测) | 9.0 | 7.5 | 两模型在事实判断上差距相对较小,仅相差1.5分 |
| VQA(视觉问题回答) | 9.7 | 5.7 | ERNIE在视觉问答上表现卓越,领先4.0分 |
热力图模式:
- ERNIE-4.5-VL的评分热力图呈现出均匀的高分布局,表明其在各类多模态任务上都有出色表现
- Qwen2.5-VL的热力图呈现出不均匀分布,在视觉事实探测(VFP)上表现相对较好,但在多模态接地(MG)和视觉问题回答(VQA)任务上表现欠佳
- 两个模型的性能差距在多模态接地(MG)任务上最为显著,达到5.0分
测评结论
通过对ERNIE-4.5系列模型与DeepSeek和Qwen系列模型的全面对比测评,我们得出以下关键结论:
1. ERNIE-4.5系列模型的核心优势
参数效率优势
- 小型模型:ERNIE-4.5-0.3B仅有0.3B参数,但在多数任务上的表现超过了参数量为1.5B的DeepSeek模型,参数效率提升约5倍
- 中型模型:ERNIE-4.5-21B-A3B通过MoE架构,仅激活3B参数,但性能全面超越32B参数的DeepSeek模型,参数效率提升约10倍
- 多模态模型:ERNIE-4.5-VL-28B-A3B同样采用MoE架构,在激活参数量更少的情况下,性能和速度均优于Qwen2.5-VL-32B模型
速度与性能平衡
- 中型模型速度优势:ERNIE-4.5-21B-A3B的Token生成速度(约59.7 tokens/秒)比DeepSeek-32B模型(约43.8 tokens/秒)快约36%
- 多模态模型速度优势:ERNIE-4.5-VL-28B-A3B的Token生成速度(约53.9 tokens/秒)比Qwen2.5-VL-32B模型(约30.1 tokens/秒)快约79%
- 小型模型质量优势:虽然ERNIE-4.5-0.3B在速度上不及DeepSeek-1.5B模型,但其输出质量明显更高,平均评分7.2 vs 4.8
任务适应性
- 全面的任务覆盖:ERNIE-4.5系列模型在所有测试的20种任务类型上均表现出色,没有明显的短板
- 推理任务优势:在数学推理、符号推理等高难度推理任务上,ERNIE-4.5系列模型表现尤为突出
- 多模态理解:在视觉问题回答任务上,ERNIE-4.5-VL模型获得了接近满分的9.7分,展示了卓越的跨模态理解能力
2. 不同规模模型的应用场景建议
| 模型 | 最适合的应用场景 | 优势 |
|---|---|---|
| ERNIE-4.5-0.3B | 移动设备、边缘计算、低资源环境 | 超小参数量、较好的文本理解能力 |
| ERNIE-4.5-21B-A3B | 企业级应用、通用AI助手、专业领域服务 | 平衡的速度与性能、全面的能力覆盖 |
| ERNIE-4.5-VL-28B-A3B | 多模态应用、图像理解、视觉问答系统 | 出色的视觉理解能力、高效的跨模态处理 |
3. 测评局限性与未来展望
虽然本次测评结果显示ERNIE-4.5系列模型具有明显优势,但我们也认识到测评存在一定局限性:
- 测试样本数量有限:每种任务类型的测试样本数量有限,可能无法完全反映模型在大规模应用中的表现
- 部署环境差异:不同的硬件环境和优化配置可能导致性能差异,本测评基于特定的FastDeploy环境
- 主观评分因素:质量评分包含主观判断,不同评估者可能有不同标准
未来测评可以考虑扩大测试样本规模,增加更多领域特定任务,以及引入更多基准模型进行对比,提供更全面的评估结果。
总的来说,ERNIE-4.5系列模型通过创新的MoE架构设计和精细的参数优化,在保持高性能的同时显著提升了推理效率,为不同应用场景提供了灵活的选择,代表了当前大模型技术的先进水平。
另外,本文中所有的测试要点以及测试数据均在 https://i2i82gjh1i.feishu.cn/sheets/V1s0sICCwhcFZwtacvtced25nSf?from=from_copylink 中查看哦~
词汇解释
-
专家模型(MoE)和Dense模型 - 博主古月居GYH的文章《Dense 与 MoE 系列模型架构的全面对比与应用策略》 ↩︎ ↩︎
-
NaViT相关论文 - 一种用于视觉Transformer的先进设计方法,ERNIE 4.5的视觉模块参考了该技术。 ↩︎
-
SOTA (State-Of-The-Art) - 文本与多模态基准测试中达到最先进水平,意味着在这些测试场景下,ERNIE 4.5的性能超越了同期其他模型。在指令遵循方面,它能更精准、高效地理解并执行用户给出的各类指令;在世界知识记忆上,对海量知识的存储和调用更为准确、全面;视觉理解时,无论是对复杂图像内容的解读,还是对视频信息的把握,都领先于同类模型;多模态推理中,面对文本、图像、音频等多种模态信息融合的任务,ERNIE 4.5也展现出更强大的推理能力和结果输出能力。 ↩︎ ↩︎
-
在深度学习中,模型 FLOPs 利用率(Model FLOPs Utilization,简称 MFU) 是衡量硬件计算资源(如 GPU、TPU)被模型有效利用程度的关键指标。它反映了模型在实际运行中,对硬件理论最大计算能力的 “兑现率”,是评估模型效率、硬件适配性及系统优化效果的核心指标之一。 ↩︎
-
DeepSeek-R1-Distill系列模型: DeepSeek-R1-Distill 系列模型是 DeepSeek 公司通过知识蒸馏技术开发的推理增强型模型,它将 DeepSeek-R1(6710亿参数巨型模型)的推理能力迁移到较小参数规模的开源模型上,显著提升了轻量化模型的逻辑推理能力。 ↩︎ ↩︎
-
Qwen2.5-VL-32B-Instruct: 阿里云于2025年3月25日正式开源了更小尺寸的视觉理解模型 Qwen2.5-VL-32B-Instruct,这是其Qwen2.5-VL系列的优化版本。该模型凭借320亿参数实现了超越前代720亿参数模型的性能,成为多模态AI部署的“黄金尺寸” ↩︎
-
FastDeploy: FastDeploy 是基于 PaddlePaddle 的大语言模型和视觉语言模型的推理与部署工具包。它提供即用型、开箱即用的部署解决方案,并具备核心加速技术 ↩︎ ↩︎

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐


 62
62 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)