ROD-MLLM: Towards More Reliable Object Detection in Multimodal LargeLanguage Models(CVPR 2025)
本文介绍了ROD-MLLM,一种利用自由形式语言进行可靠目标检测的新型MLLM。将基于语言的物体检测解耦为低级定位和高级理解,具体来说就是使用一个开放词汇检测器作为低级定位器,将其与用户的查询结合以获取候选物体,通过感兴趣区域对齐(ROI Align)提取后,局部物体特征被投影到语言空间,然后与全局视觉特征一起发送到大型语言模型。为了实现模型对自由形式描述检测能力的自由,还设计了一个自动化注释流程
研究方向:Image Captioning
1. 论文介绍
本文介绍了ROD-MLLM,一种利用自由形式语言进行可靠目标检测的新型MLLM。将基于语言的物体检测解耦为低级定位和高级理解,具体来说就是使用一个开放词汇检测器作为低级定位器,将其与用户的查询结合以获取候选物体,通过感兴趣区域对齐(ROI Align)提取后,局部物体特征被投影到语言空间,然后与全局视觉特征一起发送到大型语言模型。

为了实现模型对自由形式描述检测能力的自由,还设计了一个自动化注释流程来构建基于语言的物体检测数据集ROD。基于现有的检测和定位数据集,我们使用多模态语言模型(MLLMs)生成丰富的物体描述,并提出了一种基于思维链(COT)的条件判断方法来匹配描述与物体边界框,使得基于描述的物体定位能够从零到多个不等。
贡献:
- 提出了ROD-MLLM,它能够基于自由形式语言描述实现统一的物体定位,并且能够拒绝不存在的物体。
- 为基于语言的检测设计了一个自动化注释流程,并构建了包含超过50万个物体描述-图像对的ROD数据集。该数据集可以有效提升对自由对象描述的检测能力。
- 在各种与对象定位和生成相关的基准测试上进行实验,包括基于语言的物体检测、检索以及区域描述。我们的结果显示,与其他多模态语言模型相比,在这些任务上的表现更为出色。
2. 方法介绍
ROD-MLLM 架构。由低级定位和高级理解两部分组成。
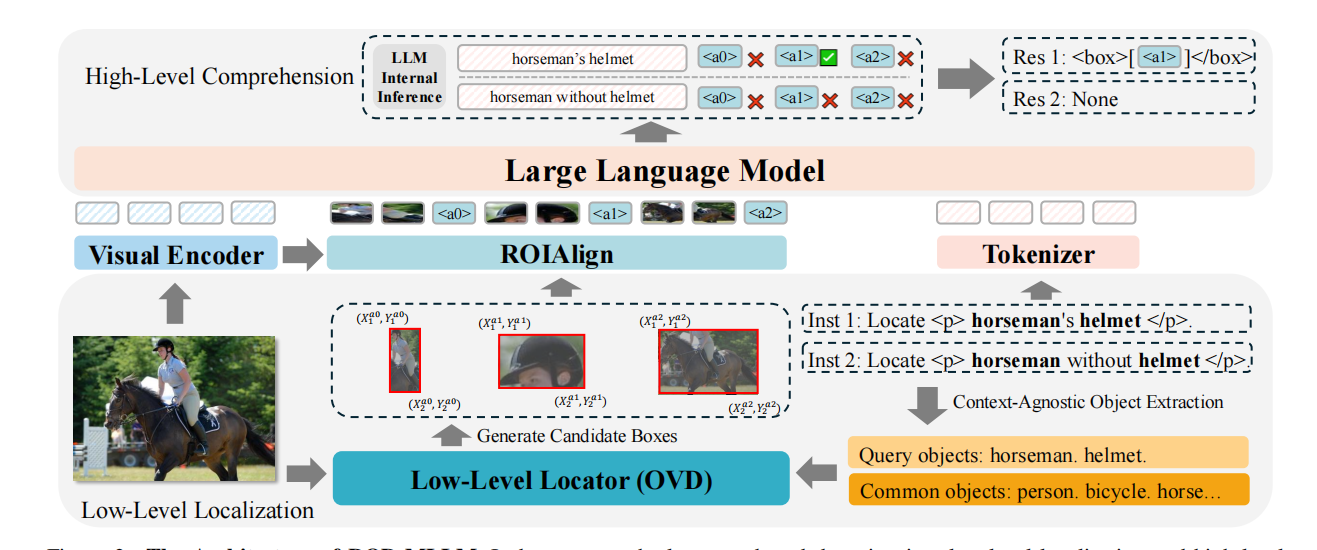
2.1 低级定位
基于查询的定位:
从用户查询中提取特殊标签<p>和</p>之间的对象表达式,并使用N-gram来提取提及的对象,然后将这些对象作为文本查询,供低级定位器(OVD)提取候选框 :
是低级定位器,
是图像,
是查询对象集合,而
是来自COCO的公共对象集合,用于在没有查询对象时增强常规视觉问答感知。
多粒度视觉输入:
图像 通过视觉编码器
编码得到多层特征
,
是视觉编码器的层数。我们在
层上使用一个两层 MLP 投影来获得语言空间中的全局图像嵌入
。对于候选框集合
,我们通过视觉编码器
编码从多层特征中构建一个三层特征金字塔
,并对这些金字塔层的特征取平均值来获得每个候选框的初步区域特征。接着,对每个框应用 8*8 的 ROI Align(感兴趣区域对齐) 操作,得到所有框的区域视觉特征
,将每个 8*8 特征切分为 2×2 的子块(共 4 块),再通过一个 MLP 层把每块各自映射为一个文本 token。这样,每个候选区域就由 4 个 token 表示,使得大语言模型(LLM)可以获得更细粒度的局部信息。
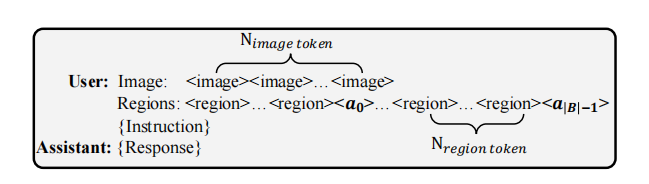
LLM 的视觉输入包含两种粒度:全局图像 token()和区域 token(
)。在每组区域 token 之后,插入一个特殊的“区域锚定 token”
<a_i>,用于在后续推理中引用并聚合该区域的信息。
2.2 高级理解
用LLM Vicuna 7B对低级定位结果进行高级理解,对于给定的文本表达,LLM判断每个区域是否满足要求,并提供最终输出。同样,当存在区域锚定token时,LLM可以解释相关图像内容,从而执行区域描述和指代对话。

我们的框架统一了多种任务形式,如指代、定位和检测。标签<p>和</p>用于包裹表达式。<box></box>中的每个锚定token用于指代具有坐标的特定区域。当图像中没有符合要求的对象时,LLM将输出“无”。
3. 数据标注流程
3.1 从检测数据集中构建数据

第一步:对象描述生成
从Objects365数据集中采样每张图像中包含的对象数量不超过10个和对象之间交并比小于0.5的10万张图片。对于一个图像-对象类别-坐标三元组⟨I,O,C⟩,我们将其输入到InternVL2-76B(书生·万象)中以生成一个对象描述。最终,我们获得了一组对象描述。
第二步:描述条件分解
将一个描述分解为几个必须满足的条件,以降低后续判断的难度。如图所示,描述“海豚在泳池边缘游泳”可以分解为三个条件。一个对象当且仅当它满足所有条件时才满足一个描述。通过少样本上下文学习,LLM 能够准确地将描述分解为条件。
第三步:基于思维链(COT)的条件判断
利用上一步分解得到的对象描述条件,我们对每个描述配对两张图像进行标注:
-
原始图像(source image),作为正样本,图中确实存在满足描述条件的目标对象;
-
随机采样的同类图像(randomly sampled image of the same category),作为负样本,该图像很可能不包含满足描述的对象。
将“对象列表 + 条件列表”一并喂给多模态大语言模型(MLLM),让它逐步回答:
-
先给出推理理由,即用语言描述图像中该对象的实际情况;
-
再给出判断结果,说明该对象是否满足某个条件。
最终获得了一系列“对象描述 + (匹配/不匹配)对象集合”的标注对。
3.2 从定位数据集中构建数据

第一步:生成存在的对象
Flickr30K实体为每张图片提供五个caption,以及caption内实体的坐标框注释,我们将其转化为一个以语言为基础的检测数据集,专注于单个对象的描述。具体来说,将每张图片的caption集合C={c1,c2,...,c5}输入到LLM (DeepSeek)中,并标记caption内的实体。手动设计prompt,指导LLM将实体扩展为描述性短语,以捕捉关于对象属性、状态、动作和关系的丰富信息。对于每张图片,我们生成大约5个存在对象的描述。
第二步:生成不存在的对象
为增强模型区分相似物体的能力,构造负样本,引导 LLM(DeepSeek)针对原图中的实体生成语义相近但实际不匹配的描述。
负样本类型包括1)类别一致但语义不符:与原实体属于同一大类,但实际动作、属性或关系不相符;2)带有否定语义:在描述中包含“without”、“that is not”等否定词,以增强模型对否定表述的理解。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)