上下文工程(上)——充分发挥智能体AI系统的潜力
几周前,我尝试用Claude Code构建一个完整的Spring Boot应用(一个略复杂的企业级用例)。由于这不是一个现成的用例,我很难定义精确的提示词(包括恰当的上下文学习、检索增强生成(RAG)等)。我得到的结果总是不一致——有时很出色,有时则完全是无意义的内容。我偶然看到了各种关于上下文工程的论文和博客,虽然之前听说过这个概念,但我曾认为它只是又一个昙花一现的潮流。我很快意识到,应该有解决
随着我们着手构建复杂的智能体AI应用,上下文工程正成为一项新兴技能。由于基于智能体AI的应用要解决复杂问题,提供恰当的上下文变得至关重要。
为上下文工程铺垫背景
我有时会花几个小时调整提示词,只为得到想要的结果,过程中还会用完所有免费额度的令牌。我相信每个人都有过类似经历,这非常令人困扰。对于任何大型语言模型(LLM)来说,最关键的输入是上下文。当我们把上下文弄对,并将恰当的上下文与提示词一起传递时,我总能看到好得多的结果,有时甚至会让我感到惊喜。
随着我们开始基于高度智能的推理模型构建强大的智能体AI应用,上下文对于我们获得正确结果而言变得更加关键。定义清晰的上下文,其重要性不亚于向软件设计师/开发者提出明确的需求。
上下文工程是一门学科,旨在设计、构建和优化提供给AI系统的上下文信息,以实现预期结果。它为构建恰当的上下文提供了一种系统化方法。这不仅仅是写出好的提示词,更是要创建一种系统化的沟通方式,确保AI每次都能给出一致、可靠且高质量的响应。
什么是上下文工程?
几周前,我尝试用Claude Code构建一个完整的Spring Boot应用(一个略复杂的企业级用例)。由于这不是一个现成的用例,我很难定义精确的提示词(包括恰当的上下文学习、检索增强生成(RAG)等)。我得到的结果总是不一致——有时很出色,有时则完全是无意义的内容。
我偶然看到了各种关于上下文工程的论文和博客,虽然之前听说过这个概念,但我曾认为它只是又一个昙花一现的潮流。我很快意识到,应该有解决办法,而且我们确实需要一种系统化的方法来定义上下文。我阅读了一些资料,并实践了网上的一些想法/技巧/方法,很快就看到了显著的出色成果。
我认为这些心得值得分享。
问题不在于大型语言模型(LLM),而在于我与它沟通的方式。我之前把它当成了搜索引擎,而不是合作伙伴。一旦我们应用了恰当的上下文工程原则,成功率就从约30%跃升到了90%以上。
以下是我在实践这些原则几周后,从各种来源学到的内容。
其目标是创建可预测、可重复的交互,最大限度地减少歧义,并最大化AI理解和恰当响应的能力。这就像与你的AI助手共同开发一种共享语言——一种你们双方都能完美理解的语言。
如果做得好,上下文工程会将AI从一个不可预测的工具转变为可靠的合作伙伴。我们不必再通过反复试验提示词来摸索,而是能获得一致、高质量的结果。
下面的流程图概括了构建上下文的高层方法。
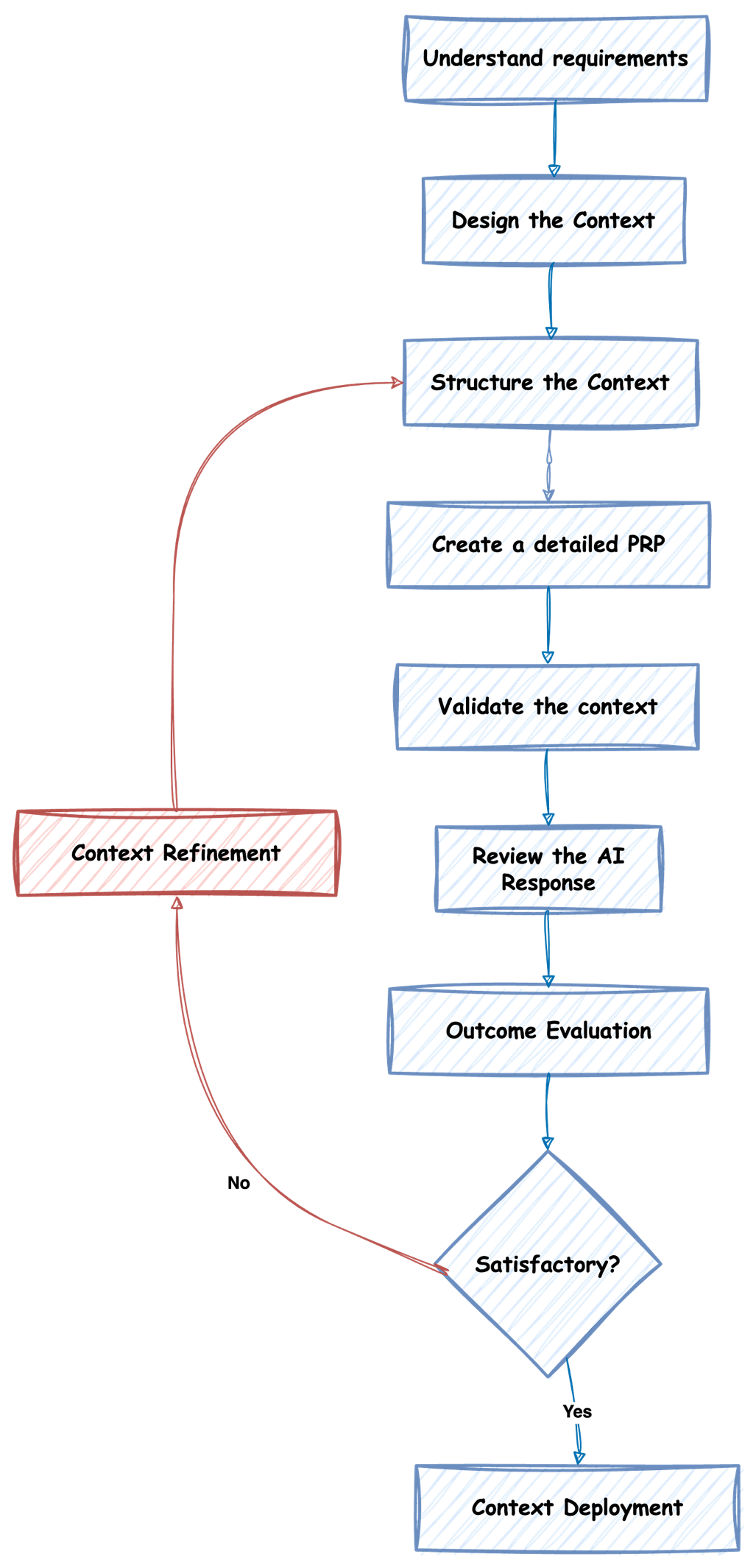
下面我逐一为你介绍每个步骤:
-
原始需求(Raw Requirements):这是大多数人的起点——一个模糊的想法,比如“我需要大语言模型(LLM)构建一个应用”。这类需求模糊不清,且往往不完整。
-
上下文设计(Context Design):这是奇迹开始的地方。我们从这个模糊的需求出发,开始提出恰当的问题:是什么类型的应用?用户是谁?目标是什么?“更好”到底意味着什么?
-
上下文结构(Context Structure):我们将所有这些信息组织成一个逻辑框架。可以把它想象成创建演示文稿的大纲——每一部分都有其位置和用途。
-
PRP(产品需求提示词,Product Requirement Prompt)实施:在这个阶段,我们构建实际的“提示词响应模式”(Prompt Response Pattern)——也就是指导我们与AI交互的可复用模板。在下一篇博客中,我会给出更多关于PRP的细节和示例。
-
上下文验证(Context Validation):之后,我们需要用真实场景测试我们的上下文,确保它能正常发挥作用。
-
AI响应(AI Response):AI基于我们精心构建的上下文生成输出。有时,我还会与其他大语言模型并行运行,看看结果是否一致。这样做的目的是确保上下文定义得足够清晰,以至于所有同等强大的推理模型都能给出相似的结果。(但愿如此!)
-
结果评估(Outcome Evaluation):我们诚实地评估结果是否符合需求。这里不粉饰太平——如果不够好,我们就承认。有时,用另一个大语言模型来测试也是个好主意。(只是个大胆的想法而而已)
-
关键决策点(The Critical Decision Point):如果结果不令人满意,我们不会从头再来——而是优化我们的上下文。
-
上下文优化(Context Refinement):我们分析问题所在,并进行有针对性的改进。这就像调试代码——有条理且有明确目标。
-
上下文部署(Context Deployment):一旦对结果满意,我们就拥有了一个能带来一致结果的可靠、可重复的流程。
关键在于“可靠”和“可重复”。考虑到几乎每个月都在发生的模型漂移,这一点就变得更加重要。
这个过程通常是迭代式的,每一轮迭代都会让上下文更稳健、更可靠。我见过简单的上下文经过几次迭代就变得异常强大。
上下文的层级
当我刚开始接触AI时,我以为上下文仅仅是提供详细的提示词。我错了。AI系统中的上下文存在多个层级,每个层级在通信栈中都有特定的作用。下图展示了上下文的各个层级,以及它们如何与上下文的各个组成部分相匹配。
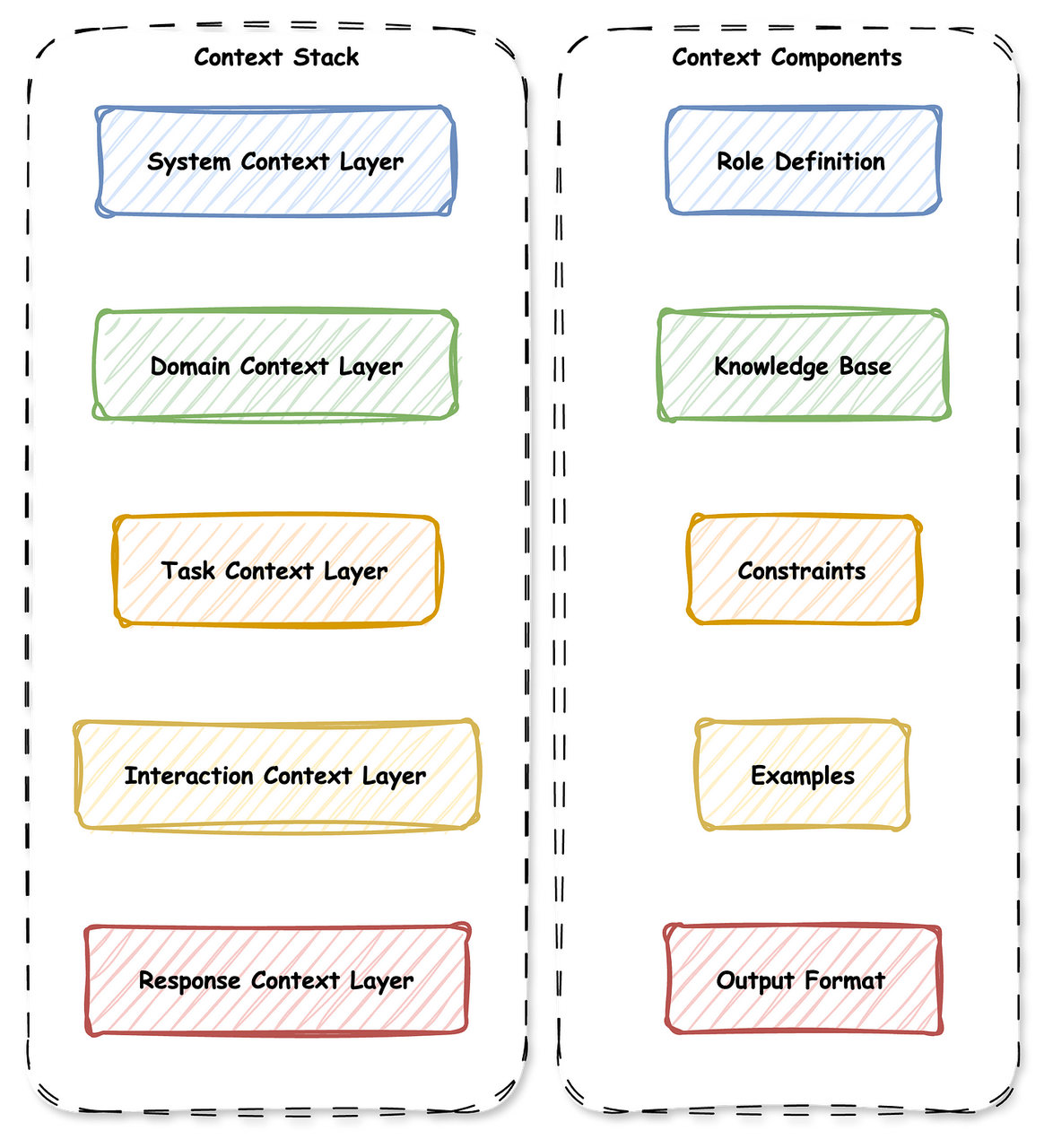
上下文栈
左侧(上下文栈)展示了五个依次运作的层级,就像建筑物的楼层一样:
系统上下文层:这是定义AI运行参数的基础层——可以理解为AI的“角色设定”和基本操作指令:
-
核心能力与局限:AI能做什么和不能做什么
-
行为准则:AI应如何行动和响应
-
安全约束:绝不能逾越的边界
-
处理偏好:AI应如何解决问题
示例:在构建客服AI时,系统上下文层规定其应提供帮助、保持礼貌,未经人工批准不得承诺退款,且对于复杂问题必须上报。这一层不会有太大变化——它是AI的核心特性。
领域上下文层:在这里,我们告诉AI为了完成特定工作需要掌握哪些领域技能:
-
领域特定知识:与该领域相关的专业信息
-
术语与行话:该领域专家实际使用的语言
-
行业标准:最佳实践和公认规范
-
相关方法:该领域的工作方式
示例:在构建医疗编码AI时,领域上下文层包含医学术语、ICD-10等编码标准、医疗法规以及医疗编码人员遵循的特定工作流程。没有这一层,AI给出的将是通用建议,而非专家级指导。
任务上下文层:这一层明确我们希望AI完成的具体事项:
-
任务要求:需要完成的具体内容
-
成功标准:如何判断任务是否出色完成
-
输入/输出规范:输入内容和预期输出结果
-
性能预期:速度、准确性和质量标准
示例:对于法律文档审查AI,任务上下文层明确规定其需要识别潜在的合规问题、标记任何需要人工审查的部分,并为每个发现提供置信度评分。如果没有清晰的任务定义,AI会漫无目的地工作。
交互上下文层:这一层管理人类与AI之间的对话流程。
-
沟通风格:正式、随意、技术性或会话式
-
反馈机制:AI应如何请求澄清
-
错误处理:出现问题时的应对方式
-
澄清流程:如何处理模糊的请求
示例:金融咨询AI的交互上下文层可能规定,它必须始终用简单术语解释复杂的金融概念,在风险承受能力不明确时提出跟进问题,且在没有适当免责声明的情况下绝不给出具体投资建议。
响应上下文层:这最后一层决定AI输出结果的呈现方式:
-
结构要求:响应内容应如何组织
-
格式偏好:标题、项目符号、表格等
-
交付限制:长度限制、技术要求、可访问性需求
-
质量标准:“足够好”与“优秀”的响应之间的区别
示例:对于技术文档AI,响应上下文层规定所有响应都应始于简要摘要,步骤说明使用编号列表,在相关处包含代码示例,并以常见故障排除提示结尾。这种一致性使文档具有可预测性且易于使用。
上下文组件
右侧(上下文组件)展示了我们在每个层级使用的具体工具和素材:
-
角色定义(Role Definition):与系统层相关联——AI的角色是什么?它应该像什么角色一样思考?
-
知识库(Knowledge Base):与领域层相关联——有哪些专业信息可用?
-
约束条件(Constraints):与任务层相关联——有哪些规则和限制?
-
示例(Examples):与交互层相关联——优质的成果是什么样的?
-
输出格式(Output Format):与响应层相关联——最终结果应如何呈现?
构建这些上下文层级需要一种极具结构性的捕捉方式。
上下文工程最强大的应用之一是产品需求提示词(PRPs)——这类专门设计的提示词用于从利益相关者的对话、文档和业务需求中提取、分析并构建产品需求。
我们将在本博客的第二部分深入探讨PRP,以及检索增强生成(RAG)如何增强这种方法。在结束第一部分之前,我想简要介绍一些我偶然发现的概念,我认为它们是非常有用的设计模式和上下文工程技术。
高级上下文工程技术
上下文分层(Context Layering)
上下文分层指的是逐步构建上下文,以实现更复杂、更细致入微的交互。这种设计模式是一种极具结构性的方式,用于实现我们在上一节讨论的分层上下文。
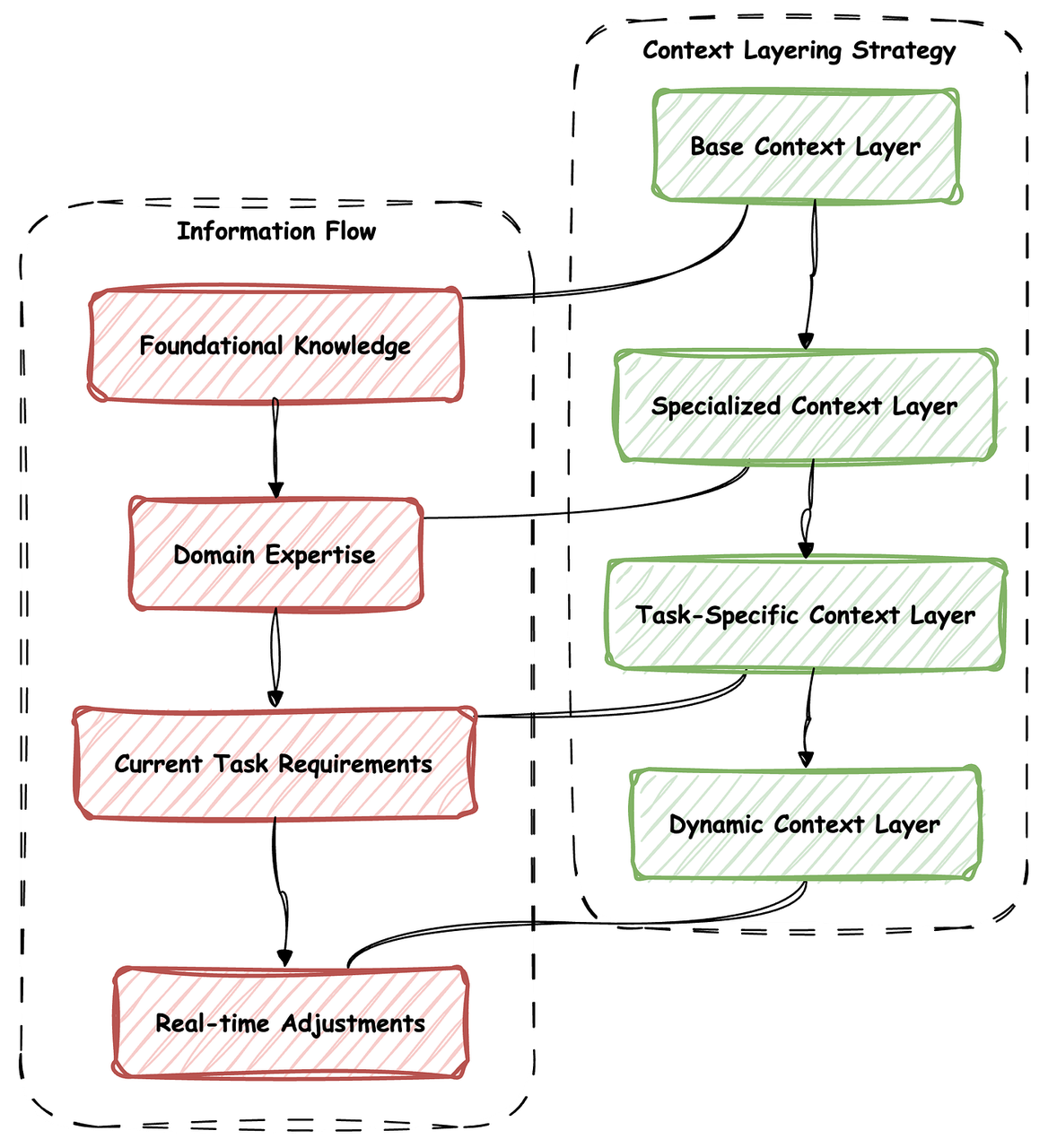
上下文链(Context Chaining)
上下文链支持复杂的多步骤流程,其中一个上下文的输出成为另一个上下文的输入;通过这种方式,上下文不断累积,融入不同的视角。只是这可能会导致上下文文档变得非常庞大,进而可能影响上下文窗口限制和令牌消耗成本。

新兴技术
随着AI能力的进步,上下文工程也在不断发展。主要的发展领域包括:
-
自适应上下文系统(Adaptive Context Systems):基于性能进行学习和调整的上下文
-
多模态上下文整合(Multi-modal Context Integration):融合文本、视觉和音频上下文。这对于许多企业解决方案来说正变得至关重要,因为这些方案不仅要生成应用代码,还需要扫描各种类型的数据来解决复杂的企业级问题
-
上下文压缩技术(Context Compression Techniques):在保持有效性的同时优化上下文大小,这将有助于减少令牌消耗,并使上下文控制在上下文窗口限制内
-
自动化上下文生成(Automated Context Generation):AI辅助的上下文设计和优化
上下文工程的最佳实践
-
清晰与精确:使用具体且明确的语言。除非与领域相关,否则避免使用行话,并对可能被误解的术语进行定义。
-
结构化组织:遵循一致的格式规范,对复杂上下文采用层级化组织,并将不同关注点划分到不同部分。
-
验证与测试:使用各种输入测试上下文。根据预期标准验证输出。基于性能反馈进行迭代。
-
可扩展性考量:设计能处理不同输入规模的上下文,考虑计算复杂度,并规划上下文的复用与适配。
-
文档与维护:记录上下文设计决策,跟踪性能指标,并为上下文的演进维护版本控制。
以上就是第一部分的内容;这是一个非常有趣的话题,涵盖的内容很多,所以我把它分成了两部分。在下一部分中,我们将介绍PRP,它对于上下文工程至关重要,而且关于PRP有太多内容需要探讨,所以我认为专门写一篇博客来介绍是个好主意。
希望本文对你有所帮助;欢迎留下你的评论、反馈,以及你在提示词工程、氛围编程、上下文工程方面的经验。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)