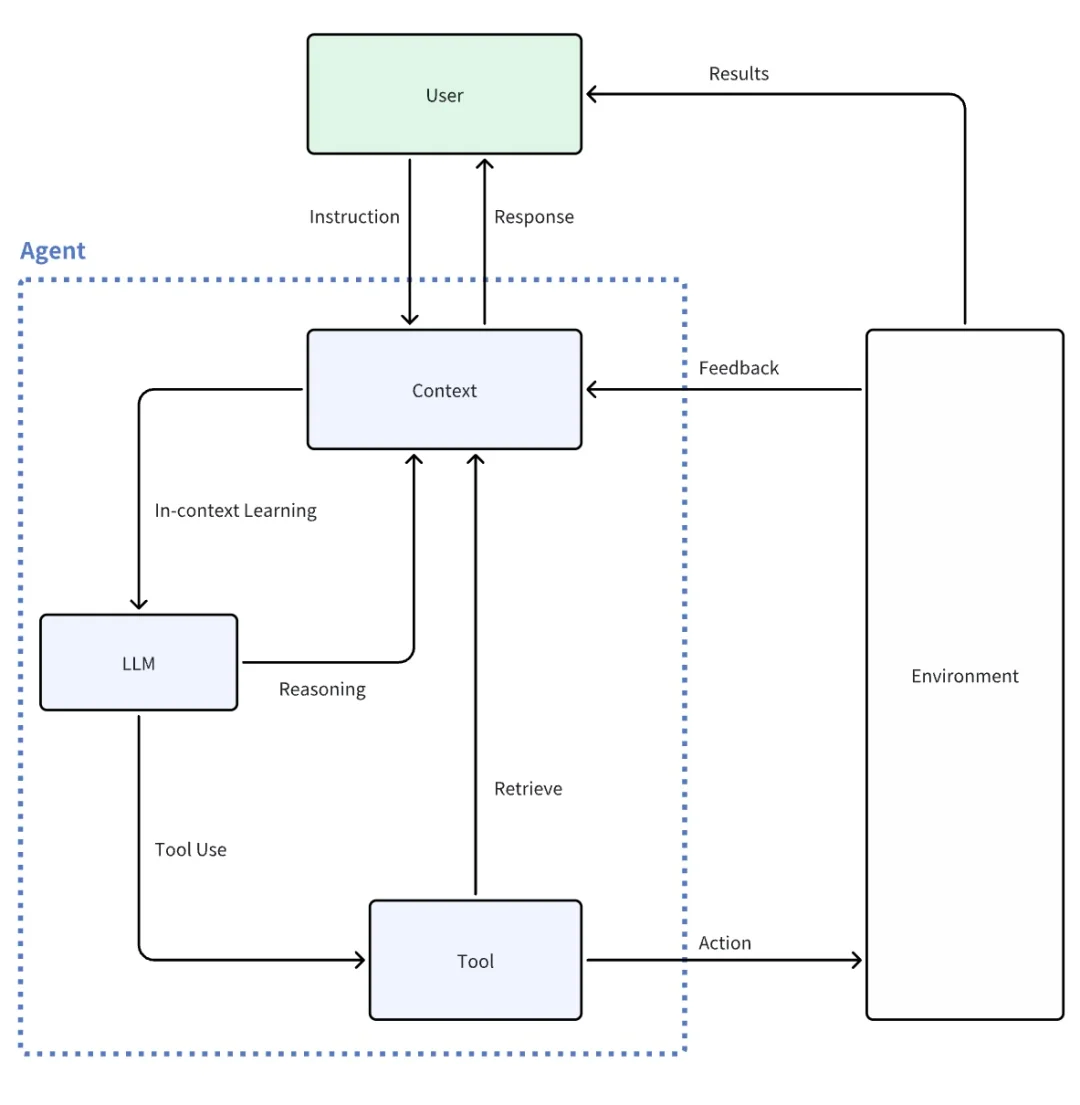
1分钟搞明白什么是Agent?Agent四大核心能力详解
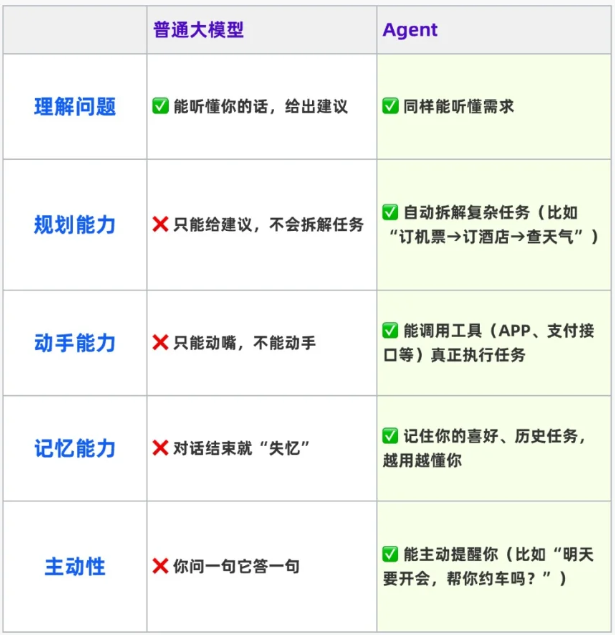
AI智能体(Agent)是结合大模型、工具调用和自主行动能力的AI系统,能像人类一样拆解并执行复杂任务。其四大核心模块包括:LLM大脑负责推理决策,记忆库存储短期/长期信息,规划引擎分解任务,工具箱连接现实工具。相比传统聊天机器人,智能体具备多模态感知、自主规划、工具调用和记忆增强能力,能完成旅游规划等实际任务。随着AI技术快速发展,2025年AI领域人才缺口预计达1000万,学习大模型技术成为把
Agent=Al大模型(大脑)+工具(手脚)+自主行动(执行力)
它不是类似于大模型的“只懂聊天的百科”,而是“能动手办事的AI助手”,它能像真人一样拆解任务,查资料,调用各种工具帮你搞定各种问题
比如说你告诉Agent你要去三亚旅游它会自动帮你查旅游攻略,安排行程,预订机票酒店,一条龙搞定。
Agent与普通大模型的区别?
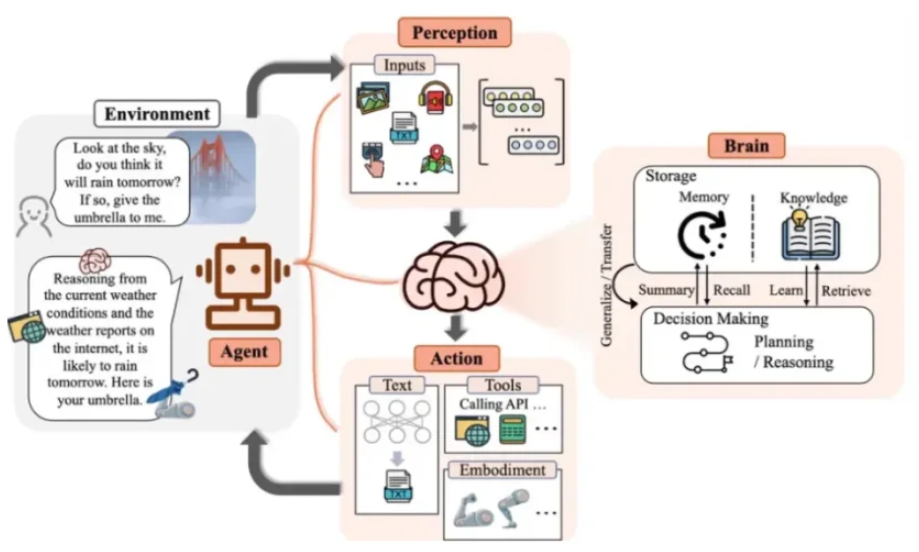
Agent的4大核心模块
大脑(LLM大模型)
负责思考、推理、做决策,比如拆解“旅行规划”成订票、查景点、排路线等步骤。
记忆库(短期+长期记忆)
短期记忆: 记住当前任务(比如正在订酒店)
长期记忆: 存你的偏好(比如你爱住五星级酒店)。
规划引擎(任务拆解专家)
把大目标切成小动作,比如“发朋友圈”’→截图→修图→配文案→发布
工具箱(连接现实世界)
能调用各种MCP工具:
软件类: 微信、淘宝、12306订票
硬件类: 控制智能家居、工厂机器人
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
Agent四大核心能力详解
一、智能体(Agent)的概念
Agent一词,直译过来为“代理”,在AI的专业语境中,常被译为“智能体”。回顾传统聊天机器人,其主要优势在于对文字的理解与处理,能够熟练回答各类问题,完成诸如修改邮件、轻松聊天等相对简单的任务。
然而,一旦面临复杂程度较高、需要多步骤协同执行且涉及与外界交互的任务时,传统聊天机器人便显得力不从心,难以有效应对。
而智能体的核心使命,便是赋予AI自主完成任务的强大能力。这意味着当AI接收任务指令后,不仅要深度思考并规划出执行路径,更要切实将计划付诸实践,确保任务得以顺利推进。
从专业定义来看,AI Agent是一种具备感知环境变化、独立自主做出决策,并能够主动执行相应行动的先进人工智能系统。
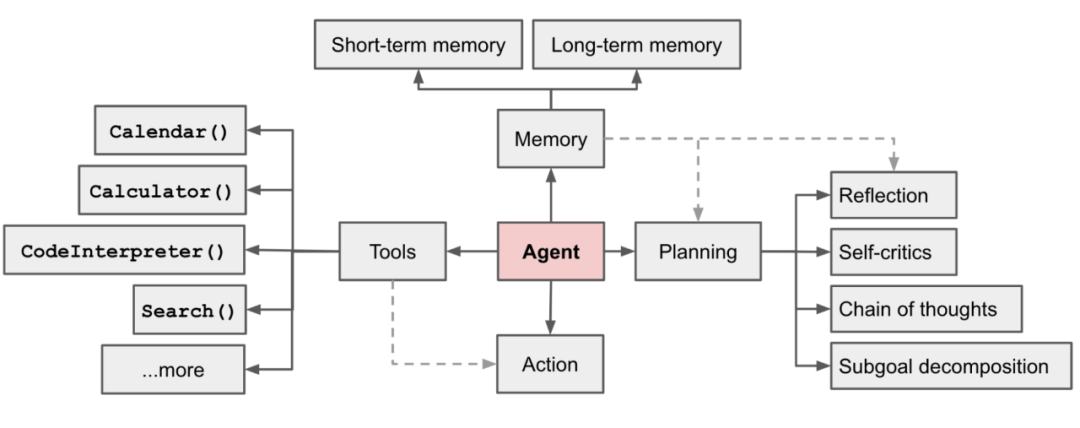
二、智能体的核心能力
Agent 的技术本质是构建能够自主完成复杂任务的人工智能实体其核心在于打通“认知-决策-执行”闭环。这一过程依赖于四大核心能力。
环境感知与多模态理解: 通过视觉、听觉、触觉等多模态输入,实现对物理与数字环境的动态解析(如GPT-40对图像语音、视频时序的识别)
自主规划与动态推理: 基于思维链(CoT)、树状思考(TOT)等框架实现任务拆解、路径优化与风险预判(如Otter模型端到端规划能力)
工具调用与跨域操作: 通过API接口、MCP协议、浏览器操控等技术,连接数字工具与物理设备(如Manus的网页自动化)
记忆增强与知识进化: 结合RAG检索与向量数据库,构建短期情境记忆与长期知识库(如MemGPT的分层记忆管理)。
1、感知能力: 从单一模态到多模态融合
1.1 文本时代局限
最初,单纯的大语言模型主要依赖海量文本数据进行训练,其基础感知途径仅仅局限于接收用户输入的文本信息。为了突破这一局限,研究人员引入OCR工具,尝试将图片、PDF等格式文件转化为文本后输入给大模型。
但这种方式存在明显弊端,在转换过程中会丢失大量关键信息,如图片中的丰色彩、独特布局,以及声音里的语气语调等重要元素。
DeepSeek R1: 仍专注于文本模型,体现技术路线分化。
1.2 多模态突破
直至2023年,GPT4推出vision版本,宛如一把钥匙,开启了多态型的大门,使得模型能够直接理解图片中的各类信息。
随后在去年,GPT发布40版本,更是实现重大突破,能够将图片、声音等多模态数据一并纳入训练范畴,从而精准理解和识别声音中的语气语调以及图片中的细微细节。
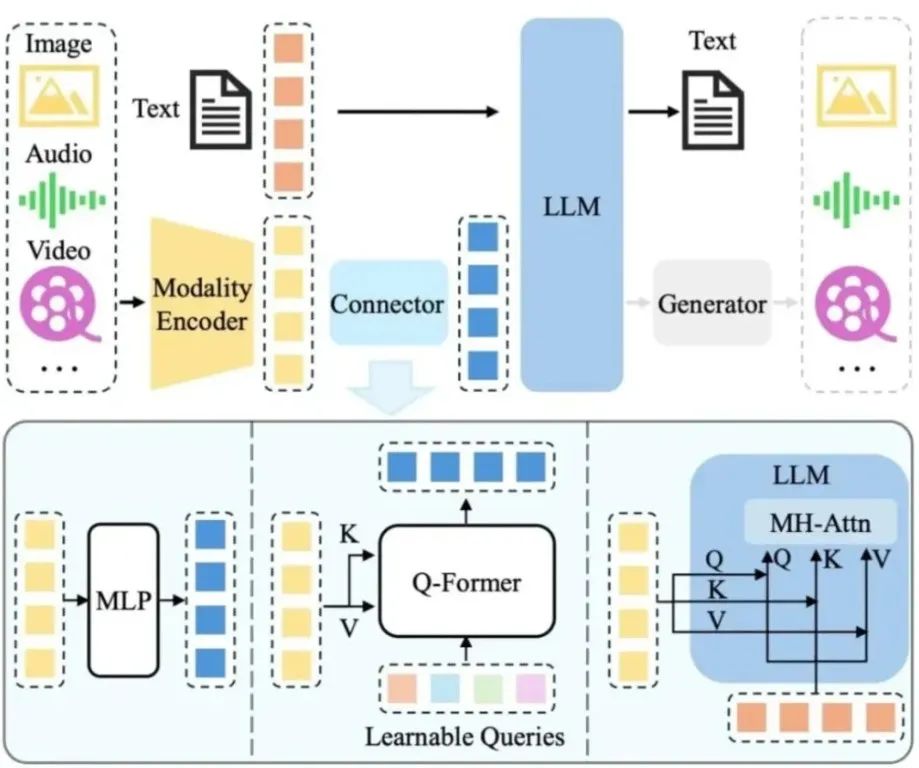
甚至部分能够识别视频时序的多模态模型也应运而生。
多模态感知使Agent能“看”世界、“听”声音,为复杂任务提供基础数据支持。
技术意义: 多模态感知使Agent能“看“世界、“听”声音,为复杂任务提供基础数据支持。
2、规划能力: 从线性推理到自主决策
2.1 早期困境
早期的大模型在回答问题时,常常表现得过于草率,缺乏深度思考与推理过程,一旦遭遇稍具复杂程度的推理问题,便极易出错。
2.2 规划方法演进
紧接着,Tree of Thoughts(ToT)方法也被提出,促使大模型能够预先构思多种不同思路,并从中筛选出最优方案。然而,由于早期大模型在规划能力方面缺乏系统性学习与训练,这些方法效果有限。
于是,多个型各司其职、协同合作完成任务的多智能体工作流诞生了。类似一站式,元器都是基于这一工作模式。但这种模式存在固有缺陷,其中间步骤完全依赖人为设定,一旦面对新任务,便需要重新设计流程。
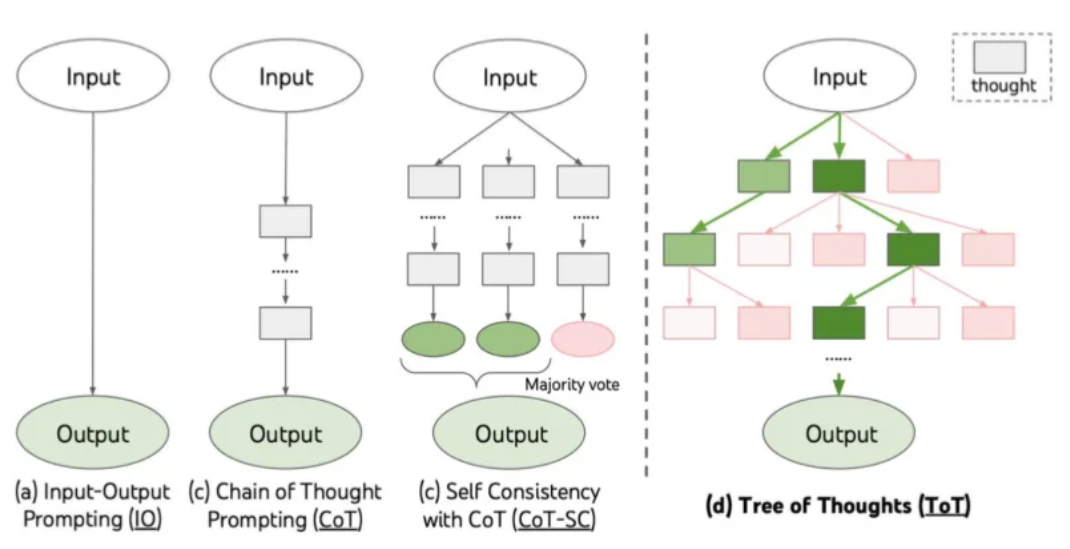
2.3 自彖径主规划突破
为实现大模型真正意义上的自主规划能力,OpenA发布的O系列模型,以及国产DeepSeek R1 等推理型大模型,成功让大模型掌握在回答问题前自主推理的技能。
今年2月,OpenAI又推出Deep Research,其背后依托端到端训练后的03型,能够自主决定何时进行信息搜索、何时整理现有信息、何时展开深度搜索以及何时进行分析总结,整个过程摆脱了对预先设计工作流或人为指定步骤的依赖,实现了高度自主。
技术意义: 规划能力是Agent从“执行者“升级为“决策者”的核心标志。
3、行动能力: 从API调用到环境交互
3.1 API调用阶段
大模型与外界沟通的最初方式,主要依赖API调用。在这一过程中,研究者通过监督微调手段,让模型学会在需要调用工具时生成特定的API调用文本。
这些文本经特定过滤机制筛选后,由外界系统识别并调用相应的功能函数,待函数运算完成,将结果反馈给大模型。
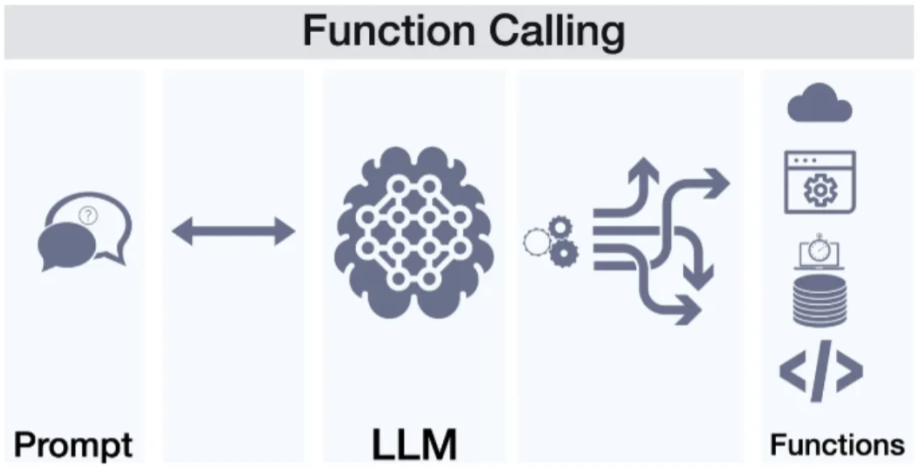
3.2 视觉交互创新
但API调用并非万能,现实世界中存在大量没有API接口的事物。为打破这一僵局,去年Anthropic发布Computer Use,致力于训练大模型从视觉层面看懂电脑屏幕并实现对电脑的操作。
尽管该尝试目前成功率较低,尚处于初阶实验阶段,但为后续研究指明了方向。
随后,开源社区顺势推出Browser Use,借助传统网页自动化工具,巧妙地间接实现了模型对浏览器的控制,这一技术正是Manus操作网页的核心技术来源。
3.3 标准化协议
此后,Anthropic进一步创新,推出MCP(ModelContext Protocol)模型上下文协议,通过统一接口规格,极大地方便了模型对各类工具的调用。
与此同时,OpenAI也不甘示弱,发布了AgentSDK和新的Response API,并内置一系列实用工具,从行业标准和基建层面为模型更好地使用工具、完成复杂任务提供了坚实保障。
4、记忆能力: 从短期缓存到长期知识库
4.1 短期记忆优化
在早期,大模型的上下文长度极为有限,短期记忆力表现不佳,与用户交流时,稍长的对话就会导致其遗忘之前的信息。为改善这一状况,业内掀起了提升上下文长度的热潮,以增强其短期记忆能力。
4.2 长期记忆增强
同时,RAG检索增强生成方案被引入,该方案将大模型需要长期记忆的知识预先存储至外部向量数据库,当需要时,模型可快速从中检索相关内容。
这一举措不仅有效弥补了大模型长期记忆的短板,还显著减少了其在回答问题时出现的幻觉问题。
此外,智能体在执行任务过程中产生的各类信息同样需要妥善保存。为此通过对任务执行过程中的关键信息进行总结、存储,并适时回顾,逐步构建起记忆模块。
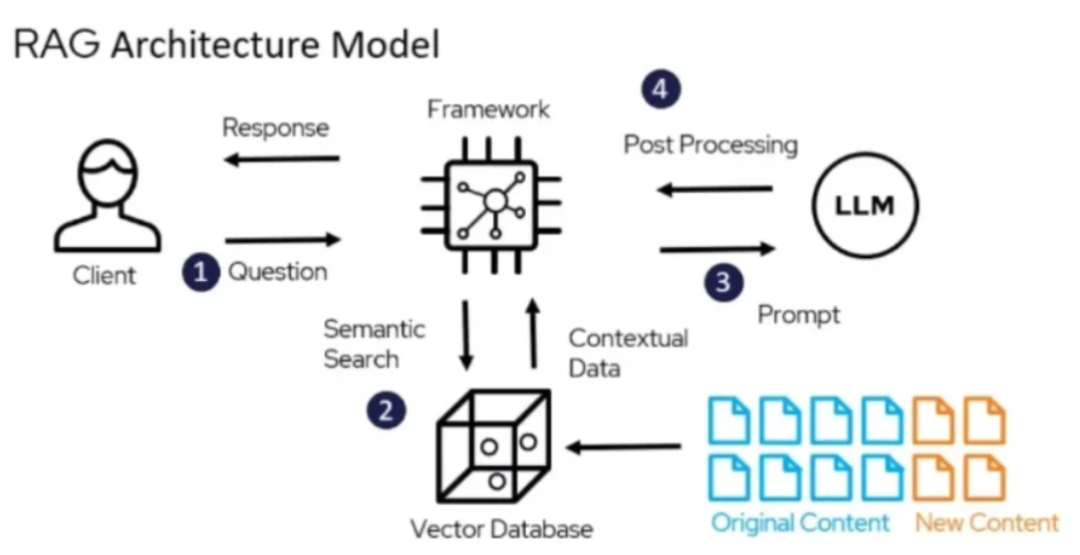
4.3 前沿探索
与人类复杂精妙的记忆系统相比,当前智能体的记忆能力仍存在较大差距为缩小这一差距,研究人员持续探索新方法个如DeepSeek开发的NSA(Native Sparse Attention)稀疏注意为机制,旨在进一步优化模型的记忆能力。
技术意义: 记忆能力是Agent实现个性化服务与持续学习的基础。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)