服务层AI架构设计
架构师应在服务层设计阶段充分考虑AI服务的动态性、资源消耗性与不确定性,通过标准化接口封装、灵活编排机制与资源感知能力,打造真正“AI就绪”的服务层体系。然而,随着AI服务在业务流程中的广泛融入,服务层不仅要具备基本的业务拓展能力,还需支持多种类型的AI能力模块接入,协调业务逻辑与智能推理之间的耦合度,并保障AI服务的可靠编排、灵活调用与资源适配能力。这些模块在逻辑上属于服务层,但其底层依赖AI模
2.3 服务层
本节系统介绍了AI架构下服务层的职责划分、模块化设计与扩展能力。重点讲解如何在服务层中集成推荐、对话等AI推理服务,并通过实际电商案例展示模型部署、接口调用与性能优化等全流程操作实践。
2.3.1 一张图看懂服务层架构
服务层是系统架构中的核心组成部分,主要职责是接收来自接入层的请求、执行业务逻辑、协调数据交互,并对外暴露清晰可控的服务接口。在AI架构背景下,服务层的功能不仅包括传统业务逻辑处理模块,也需要集成和承载AI推理服务,从而支持更加智能的业务功能。
为了便于理解,图2-展现了服务层在现代AI系统中的典型架构。
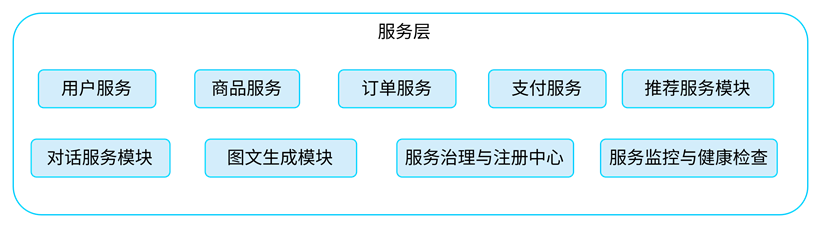
图2-包含以下关键组成模块。
(1)传统业务服务模块
- 用户服务:负责处理用户注册、登录、资料更新等功能;
- 商品服务:负责商品信息管理、浏览、分类等;
- 订单服务:负责订单生成、状态变更、查询等;
- 支付服务:对接支付渠道,管理支付流程与回调。
(2)AI推理增强模块
- 推荐服务模块:为用户提供个性化推荐内容,通常接入推荐模型;
- 对话服务模块:用于客服问答、语义理解等任务,封装大语言模型的推理调用;
- 图文生成模块:用于生成商品描述、营销文案、图片等内容,支持AIGC功能。
这些模块在逻辑上属于服务层,但其底层依赖AI模型推理,需设计为“可管理的服务单元”,具备接口规范、调用限流与性能监控能力,便于架构统一管理。
(3)服务治理与运行保障模块
- 服务治理与注册中心:管理所有服务的注册与发现,支持服务自动扩缩容、动态路由;
- 服务监控与健康检查:负责服务的运行状态监控、接口响应时长、调用成功率等指标采集,为运维提供实时可视化支持。
与传统架构相比,AI架构下的服务层呈现以下三个显著特征:
- 服务类型更加多样:不仅包括CRUD类业务服务,也包括AI推理服务、生成服务等智能功能模块;
- 资源依赖更加复杂:AI相关服务可能依赖GPU、模型文件、上下文缓存等资源,架构设计需明确资源接口边界;
- 服务性能要求更高:推理型服务可能响应时间较长,需要设计异步机制、并发控制与结果缓存等优化手段。
提示:
服务层架构是系统中连接前端请求与核心业务逻辑的中枢区域。在AI架构中,它不仅承载传统业务模块,还需支持部署模型推理服务和智能功能组件。架构师在设计服务层时,需遵循模块化、高内聚、低耦合的原则,并预留好对AI服务的可扩展支持接口,为系统的智能化演进奠定坚实基础。下一节将进一步探讨服务层如何通过模块化设计,实现稳定性与灵活性的统一。
2.3.2 服务层的模块化设计——高内聚低耦合
服务层是系统中承载业务逻辑的核心区域。在AI架构中,服务层不仅处理传统业务流程,还需集成推理类AI服务,因此其模块化设计必须具备更强的清晰性与可扩展性。
1. 高内聚:让服务聚焦核心职责
高内聚指的是每个服务模块内部功能应围绕单一职责展开,不混合其他不相关的逻辑。例如:
- 用户服务应仅处理用户注册、登录、资料更新等功能;
- 商品服务应负责商品的上架、分类、检索,不包含推荐排序逻辑;
- 推荐服务应聚焦于模型调用、候选生成与排序策略,而不是商品信息维护。
特别是在引入AI能力后,AI推理服务也应作为一个高内聚的模块存在,只负责接收业务参数并返回模型预测结果,而不处理业务场景中的数据校验、流程控制等逻辑。
2. 低耦合:让模块之间独立演进
低耦合要求服务之间通过清晰接口通信,避免直接调用彼此数据库或共享内部结构。在AI架构中,推荐服务、问答服务、AIGC模块等智能服务应通过标准化接口与业务模块对接,而非深度嵌入业务代码之中。
例如,商品服务调用推荐服务时,应通过接口如“/recommend?user_id=123”获取排序列表,而不应直接访问推荐模型或算法逻辑。这样,当推荐模型更换或服务迁移时,商品服务无需改动,保障系统弹性。
推荐服务应完全独立于商品服务模块,其交互路径如下:
商品服务
└─ 业务接口:获取商品列表、查询商品详情
└─ 调用:通过接口调用推荐服务获取排序权重
推荐服务(AI模块)
└─ 接口:/recommend?user_id=xxx
└─ 内部逻辑:根据用户ID检索行为特征 → 向量召回 → 模型排序 → 返回商品ID列表
推荐模型
└─ 独立部署在GPU节点,通过推理平台服务化
2.3.3 服务层的扩展性设计——支持AI服务的接入与编排
在传统系统架构中,服务层的扩展性主要体现为支持业务模块的横向拓展与系统接口的不断演化。然而,随着AI服务在业务流程中的广泛融入,服务层不仅要具备基本的业务拓展能力,还需支持多种类型的AI能力模块接入,协调业务逻辑与智能推理之间的耦合度,并保障AI服务的可靠编排、灵活调用与资源适配能力。
1. 服务层的横向可扩展性
传统的服务层通常通过微服务架构实现横向扩展,即将不同业务功能模块拆分为独立的服务单元,通过注册中心和网关进行统一管理。AI架构下,这种拆分模式依然适用,但在实现过程中需要注意以下两点:
- 所有新业务模块(如对话业务、生成业务、行为分析业务)应具备独立的服务边界,避免混入已有业务模块中;
- AI能力模块不应嵌套在业务服务中,而应作为服务层的增强单元并行部署,实现智能能力的“即插即用”。
例如,当在原有的订单服务中引入“智能定价”功能时,应通过调用独立部署的定价模型服务实现,而非直接将模型逻辑集成进订单服务内部。这样做既能保障模型的独立演化,也能降低业务服务的复杂性。
2. AI服务的接入机制
AI服务的接入,不应改变服务层的原有结构与职责,而应通过“能力注入”方式进行无侵入集成。这要求服务层具备如下能力:
(1)标准接口封装能力
AI模型应以标准API的形式提供推理能力,服务层通过REST/gRPC等协议调用。例如,推荐服务可暴露 /recommend?user_id=xxx 接口,商品服务调用该接口后获得排序结果进行商品展示。
(2)参数与上下文适配能力
由于AI模型通常对输入格式、上下文环境有特殊要求,服务层需要引入参数适配器,对业务请求参数进行转化、补全。例如,对话服务在调用模型前,需要合并当前用户问题与历史对话上下文,构建完整Prompt。
(3)响应结构抽象能力
AI模型返回的结构可能不固定,服务层需引入响应解析逻辑,对模型输出内容进行规范化处理,以便业务逻辑后续使用。例如,图文生成服务返回的内容需按字段区分文本、图片URL与生成状态码。
(4)接口容错与超时控制能力
AI推理具有一定不确定性,可能因模型负载、输入异常等导致响应延迟或失败。服务层需设置调用超时机制、失败回退策略,并提供默认应答或降级方案,保障系统整体可用性。
3. AI服务的编排机制
服务层需要将多个AI能力串联成流程,从而构建智能业务链路。
例如,在一个智能客服系统中,用户发起一次问题咨询,服务层需执行以下操作:
- 语音转文本(调用语音识别模型);
- 意图识别与问题分类(调用文本理解模型);
- 查询FAQ知识库或调用大模型生成答案;
- 内容安全审核与关键词过滤;
- 生成多模态回答(如文本+图像)并返回。
这种流程不是单一模型可完成的,而是多个AI服务的编排。为支持这种能力,服务层可引入以下机制。
- AI调用流程引擎:使用规则驱动或配置驱动方式编排模型调用路径;
- 调用链路追踪组件:记录每一步AI服务调用状态与耗时,便于调试与优化;
- 分支与条件判断模块:支持根据业务规则或模型输出,动态选择后续模型;
- 异步任务管理组件:对耗时模型调用进行异步处理,通过队列或回调完成通知。
服务层不再是简单的业务函数聚合器,而演化为“智能调用协调器”,其设计复杂性显著提升。
4. 服务层对AI资源的感知与适配
AI服务往往依赖GPU、TPU等异构硬件资源,而传统服务层通常运行在CPU上。为了保障AI模型服务的性能与稳定性,服务层需要具备一定的资源感知能力:
(1)GPU感知调用策略
服务层可通过模型管理中台获取各推理服务的当前GPU占用情况,动态选择负载较低的模型副本进行调用。
(2)并发控制与排队机制
当推理服务并发达到上限时,服务层应将新请求排队处理,或返回“稍后再试”提示,避免资源过载。
(3)缓存与预取机制
对于重复性高的模型调用结果,服务层可在调用前先查询缓存系统,命中后直接返回,未命中再进行推理,提升响应效率。
(4)结果预热与定时更新
对于高频使用的模型接口,服务层可设定固定时间段自动触发预热请求,确保推理容器提前加载模型、减少冷启动耗时。
提示:
AI架构下的服务层,不再仅仅是承载业务逻辑的容器,而是智能能力集成、推理调用编排、资源调度协调的重要枢纽。架构师应在服务层设计阶段充分考虑AI服务的动态性、资源消耗性与不确定性,通过标准化接口封装、灵活编排机制与资源感知能力,打造真正“AI就绪”的服务层体系。这样,才能为大规模智能能力在业务系统中的持续接入、运行与演进提供坚实架构基础。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐



 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)