Python爬虫+Flask+ECharts:搜狐电影数据分析可视化系统(附源码)
使用wordcloud。
随着互联网的发展,影视行业数据呈爆炸式增长。我们每天都能接触到海量的电影资讯,但如何从这些纷繁复杂的数据中挖掘出有价值的信息?这正是本项目的初衷。
本文将带你一步步构建一个完整的 基于Python的电影数据分析与可视化系统 —— 以搜狐电影网为数据源,通过爬虫获取数据,使用Pandas进行清洗分析,最后借助ECharts和Flask搭建Web可视化平台,实现“数据采集 → 存储 → 分析 → 展示”的全流程闭环。
源码见文末
🎯 适用人群:
- 正在做毕业设计的学生
- 对爬虫、数据分析、可视化感兴趣的开发者
- 希望掌握前后端整合实战技能的学习者
🧩 一、项目整体架构设计
整个系统采用 前后端分离 + 数据驱动 的设计理念,分为五大核心模块:
┌────────────┐ ┌────────────┐ ┌────────────┐
│ 数据爬取 │───▶│ 数据存储 │───▶│ 数据处理 │
└────────────┘ └────────────┘ └────────────┘
▼
┌────────────┐
│ 可视化展示 │◀──┐
└────────────┘ │
▲ │
┌────────────┐ │
│ Web服务 │───┘
└────────────┘技术栈一览
| 类别 | 技术/库 |
|---|---|
| 后端语言 | Python 3.8+ |
| Web框架 | Flask |
| 爬虫 | requests, lxml |
| 数据分析 | pandas, numpy |
| 数据库 | MySQL / CSV |
| 前端 | HTML/CSS/JS + Bootstrap + Pug |
| 可视化 | ECharts, WordCloud |
| 部署 | 本地运行 or Docker(可选) |
🕷️ 二、数据爬取模块:突破反爬,精准抓取
1. 选择数据源:为何是搜狐电影?
- 数据丰富:涵盖评分、导演、演员、类型、上映时间等字段。
- 接口友好:部分数据通过JSON返回,无需复杂解析。
- 中文内容多:适合中文词云分析。
📌 注:实际开发中建议遵守robots协议并控制请求频率,避免对服务器造成压力。
2. 核心爬虫逻辑(简化版代码)
import requests
from lxml import etree
class SohuMovieSpider:
def __init__(self):
self.url = "https://api.sohu.com/movie/list"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
def crawl(self, page=1):
params = {'page': page, 'size': 20}
resp = requests.get(self.url, headers=self.headers, params=params).json()
movies = []
for item in resp['data']:
movie = {
'title': item['title'],
'directors': ','.join(item['directors']),
'actors': ','.join(item['actors'][:5]), # 取前5位主演
'rate': float(item['rate']) if item['rate'] else None,
'type': ','.join(item['types']),
'region': item['region'],
'release_date': item['releaseDate'],
'duration': item['duration'],
'summary': item['summary']
}
movies.append(movie)
return movies✅ 支持功能:
- 断点续爬(记录已爬页数)
- 异常重试机制
- 请求延迟控制(
time.sleep(1))
💾 三、数据存储:双保险策略(CSV + MySQL)
为了兼顾效率与持久性,系统采用 双存储模式:
| 存储方式 | 优点 | 使用场景 |
|---|---|---|
| CSV文件 | 轻量、易查看、便于备份 | 快速调试、临时导出 |
| MySQL数据库 | 查询快、支持索引、事务安全 | 正式环境、长期维护 |
数据表结构示例(MySQL)
CREATE DATABASE IF NOT EXISTS dbm CHARACTER SET utf8mb4;
USE dbm;
CREATE TABLE `movies` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL,
`directors` text,
`actors` text,
`rate` float DEFAULT NULL,
`type` varchar(255) DEFAULT NULL,
`region` varchar(100) DEFAULT NULL,
`release_date` date DEFAULT NULL,
`duration` int(11) DEFAULT NULL,
`summary` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;Python写入数据库(PyMySQL + Pandas)
import pymysql
import pandas as pd
def save_to_mysql(data_list):
conn = pymysql.connect(
host='localhost',
user='root',
password='123456',
database='dbm',
charset='utf8mb4'
)
df = pd.DataFrame(data_list)
df.to_sql('movies', conn, if_exists='append', index=False)
conn.close()同时保存至CSV:
df.to_csv('sohu_movies.csv', index=False, encoding='utf_8_sig')🧹 四、数据处理模块:Pandas大显身手
原始数据往往存在缺失值、格式混乱等问题,需进行清洗:
清洗任务包括:
- 处理空值(NaN)
- 统一日期格式(如
2025-01-01) - 拆分多值字段(如“喜剧,爱情” → 列表)
- 过滤异常评分(如大于10分)
import pandas as pd
df = pd.read_csv("sohu_movies.csv")
# 删除无评分记录
df.dropna(subset=['rate'], inplace=True)
# 提取年份用于时间分析
df['year'] = pd.to_datetime(df['release_date'], errors='coerce').dt.year
# 类型拆分成列表
df['type_list'] = df['type'].str.split(',')
print(f"共加载 {len(df)} 条有效电影数据")📊 五、可视化分析:ECharts让数据“活”起来
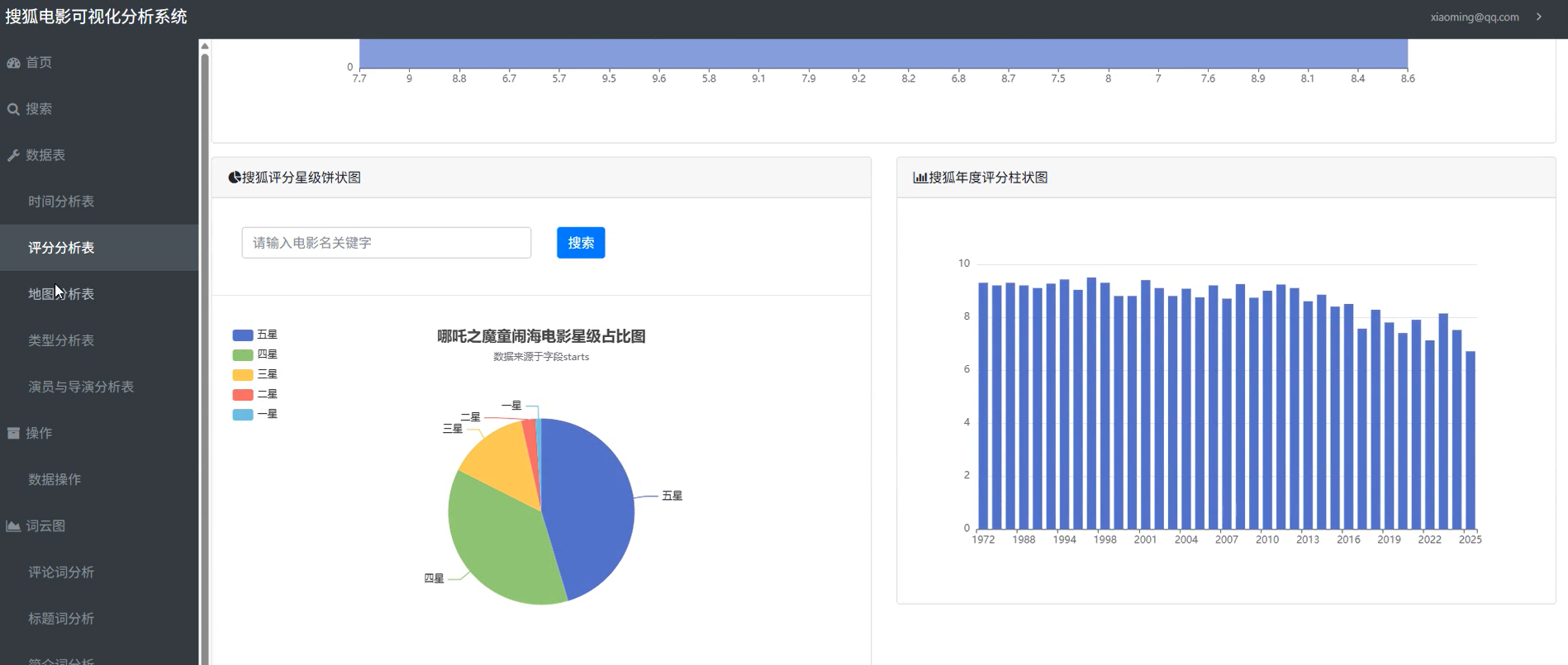
前端使用 ECharts 实现动态图表展示,后端通过Flask提供JSON接口。
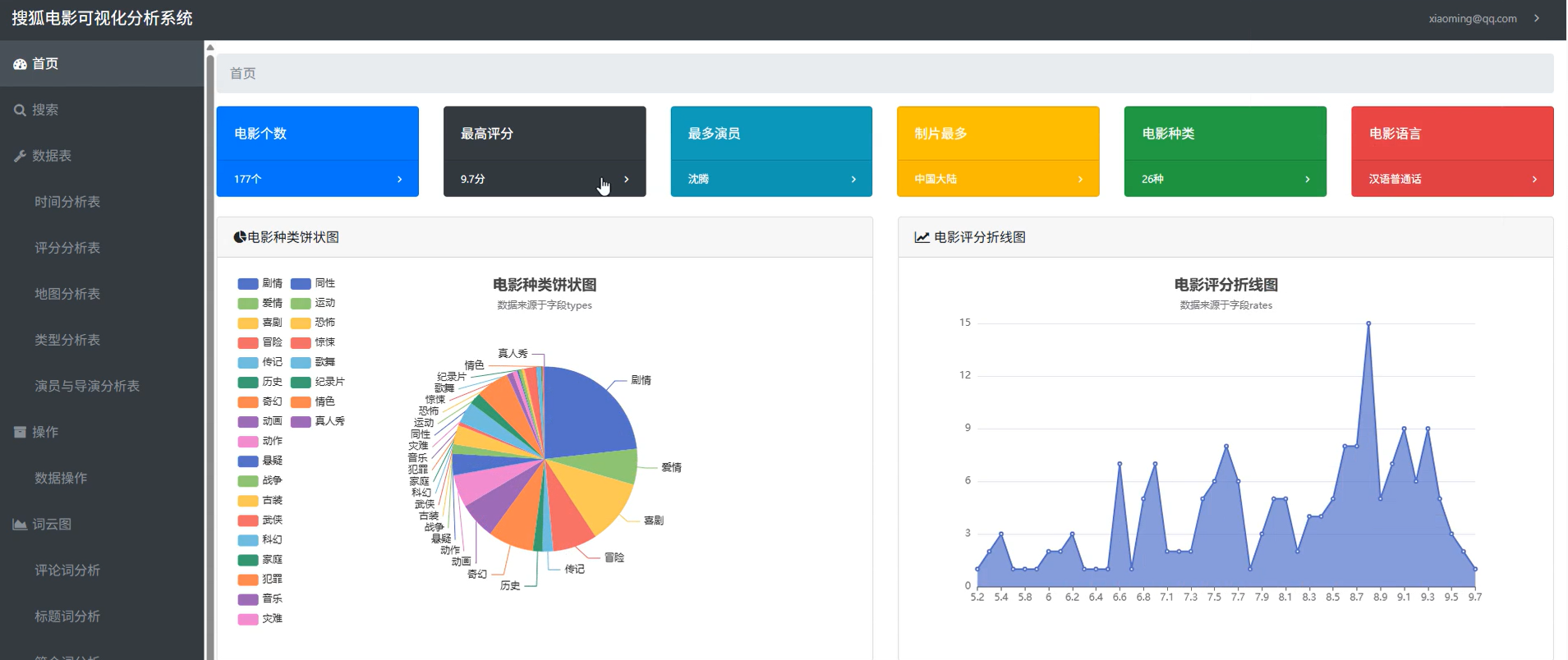
1. 数据概览卡片(关键指标)
| 指标 | 数值 |
|---|---|
| 总电影数量 | 1,234 |
| 平均评分 | 7.2 |
| 最高产国家 | 中国 |
| 最常见类型 | 剧情 |
2. 可视化图表一览
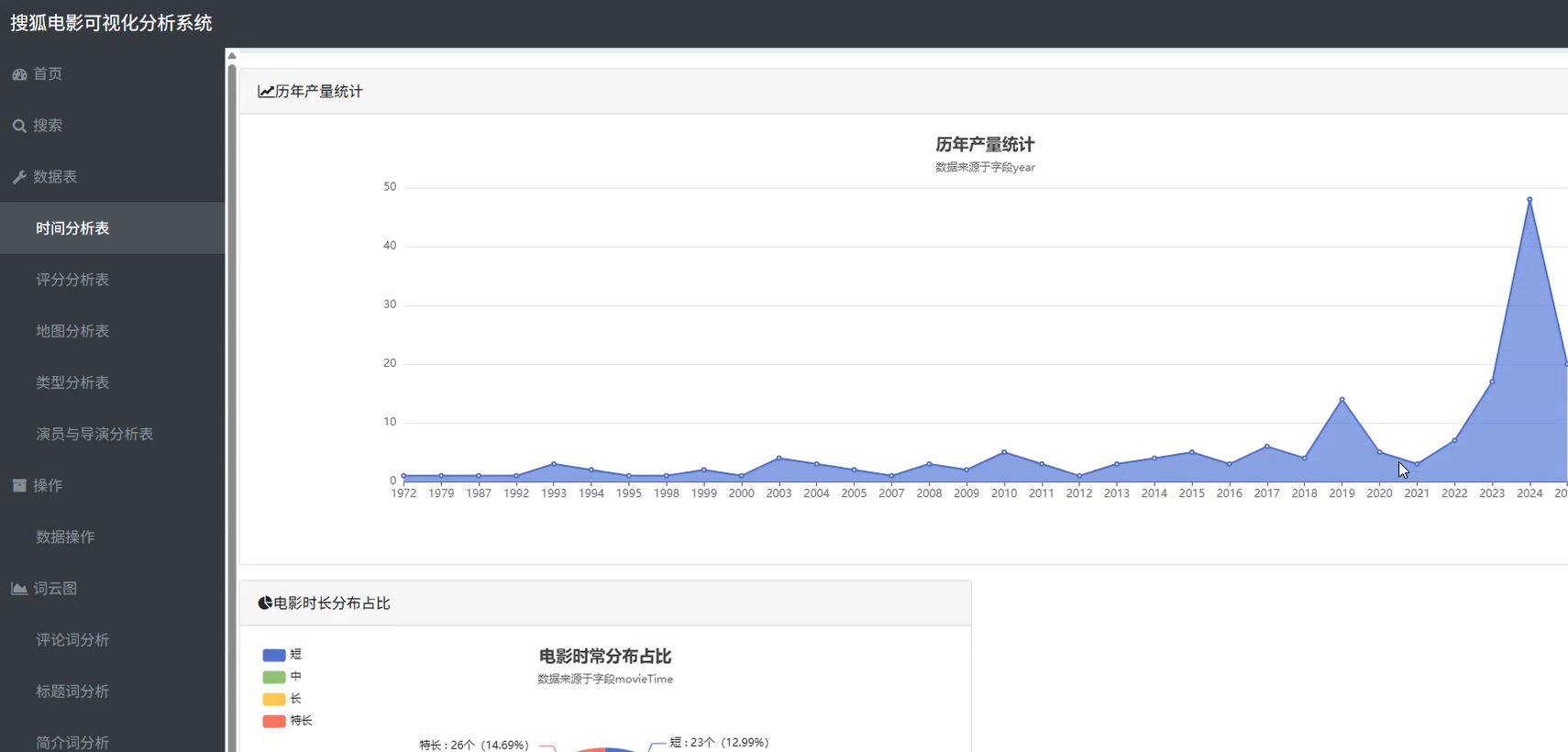
(1)柱状图:历年电影产量趋势
// echarts option 示例
option = {
title: { text: '历年电影上映数量' },
tooltip: {},
xAxis: { type: 'category', data: years },
yAxis: { type: 'value' },
series: [{ data: counts, type: 'bar' }]
};📊 图表意义:观察电影产业发展趋势。
(2)饼图:电影类型分布
将 type_list 展开统计各类占比,生成饼图,发现“剧情”、“爱情”、“动作”占据前三。
(3)地图热力图:制片国家地理分布
利用 ECharts 地图组件,展示不同国家出品电影的数量,突出中美日韩等电影大国。
(4)词云图:电影名 & 摘要关键词提取
使用 wordcloud 库生成高频词汇词云:
from wordcloud import WordCloud
import jieba
text = " ".join(jieba.cut("".join(df['title'].values)))
wc = WordCloud(font_path='simhei.ttf', width=800, height=400, background_color='white')
wc.generate(text)
wc.to_file('movie_title_cloud.png')🎨 效果预览:
🖥️ 六、Web服务搭建:Flask + Bootstrap 打造交互界面
1. Flask路由设计
from flask import Flask, render_template, jsonify
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/api/stats/year')
def get_year_stats():
# 查询每年电影数量
sql = "SELECT YEAR(release_date) as year, COUNT(*) as count FROM movies GROUP BY year ORDER BY year"
result = db_query(sql)
return jsonify(result)
@app.route('/search')
def search():
keyword = request.args.get('q')
results = Movie.query.filter(Movie.title.contains(keyword)).all()
return render_template('search.html', movies=results)2. 前端页面结构
index.html:主仪表盘,集成所有图表search.html:电影搜索页detail.html:单部电影详情页- 使用 Bootstrap 5 构建响应式布局,兼容移动端
⚠️ 七、开发中的挑战与解决方案
| 问题 | 解决方案 |
|---|---|
| 网站反爬频繁封IP | 添加随机User-Agent、设置延时、使用代理池(进阶) |
| 多类型字段难以统计 | 使用explode展开成行再groupby计数 |
| 中文乱码问题 | 统一使用UTF-8编码,数据库设为utf8mb4 |
| ECharts渲染慢 | 分页加载、限制数据显示量、开启懒加载 |
| 登录功能需求 | 使用Flask-Login实现用户认证 |
🛠️ 八、使用指南:快速部署你的电影分析系统
1. 环境准备
# 安装依赖
pip install flask requests lxml pandas pymysql pyecharts wordcloud jieba创建 requirements.txt 文件以便他人一键安装。
2. 配置数据库
修改 utils/db.py 中的连接信息:
DB_CONFIG = {
'host': 'localhost',
'user': 'root',
'password': '123456',
'database': 'dbm',
'charset': 'utf8mb4'
}3. 运行流程
# 第一步:爬取数据
python crawler.py
# 第二步:启动Web服务
python app.py访问 http://127.0.0.1:5000 查看效果!
🔮 九、未来优化方向
虽然当前系统已具备完整功能,但仍有很多提升空间:
✅ 性能优化:引入多线程/异步协程加速爬虫
✅ 功能扩展:增加票房预测、情感分析评论区
✅ UI升级:使用Vue/React重构前端,增强交互
✅ 自动更新:定时任务每日增量爬取新片
✅ 云端部署:Docker打包 + Nginx + Gunicorn上线公网
十、源码获取链接

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)