RAG全栈技术——文档加载器
摘要:本文介绍了LangChain框架中RAG模块的数据处理流程,重点解析了Source与dataloaders功能实现。LangChain通过文档加载器(Documentloaders)抽象不同数据源,支持多种格式如Wikipedia在线文档、txt和json文件。文章详细展示了三种文档加载示例:维基百科查询、txt文本读取以及使用jq解析json文件。每种加载器处理后都会生成标准Documen
前言:在LangChain框架中,RAG作为一个非常重要且关键的模块独立存在,LangChain提供了多种较为通用的实现方法,这包括如何将不同来源、不同形式的数据切分成一个个小块,如何使用Embedding模型做向量化,如何将向量存储进向量数据库中,以及提供了快速检索的优化算法。每一环节设计的基础技术,都作为一个独立的抽象模块存在,而将各个环节像Chains一样串流起来进行数据交换,形成一个完整的RAG系统,LangChain抽象了一个所谓的data connection数据处理流,如下图所示:
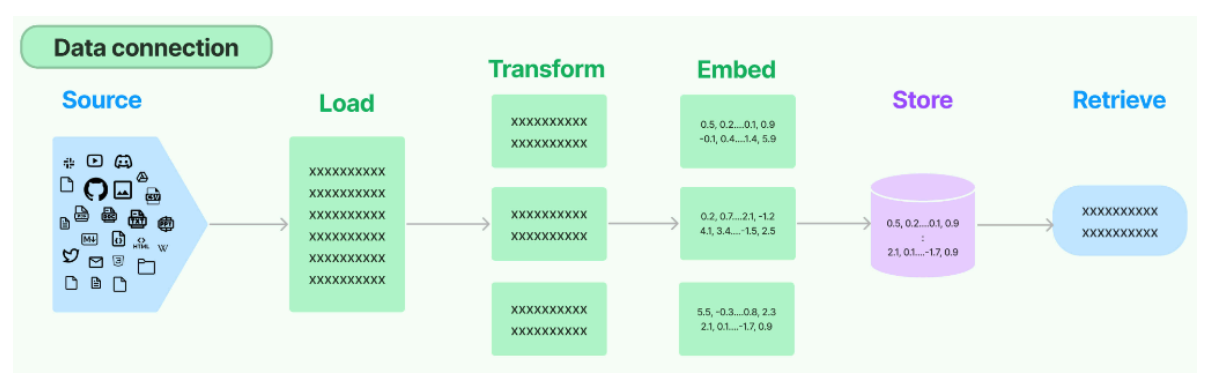
一. Source 与 data loaders功能实现
Source概念指的是RAG架构中所外挂的知识库。正如我们之前所讨论的,因为大模型的原生能力很强,所以它可以识别多种不同的类型的原始数据而不用做额外的处理,而且在实际场景中,私有数据通常也并不是单一的,可以来自多种不同的形式,可以是上百个.csv文件,可以是上千个.json文件,也可以是上万个.pdf文件,同时如果对接到具体的业务,可以是某一个业务流程外放的API,可以是某个网站的实时数据等多种情况。
所以LangChain首先做的就是:将常见的数据格式和数据来源使用LangChain的规范,抽象出一个一个的单独的集成模块,称为文档加载器(Document loaders),用于快速加载某种形式下的文本数据。如下图所示:
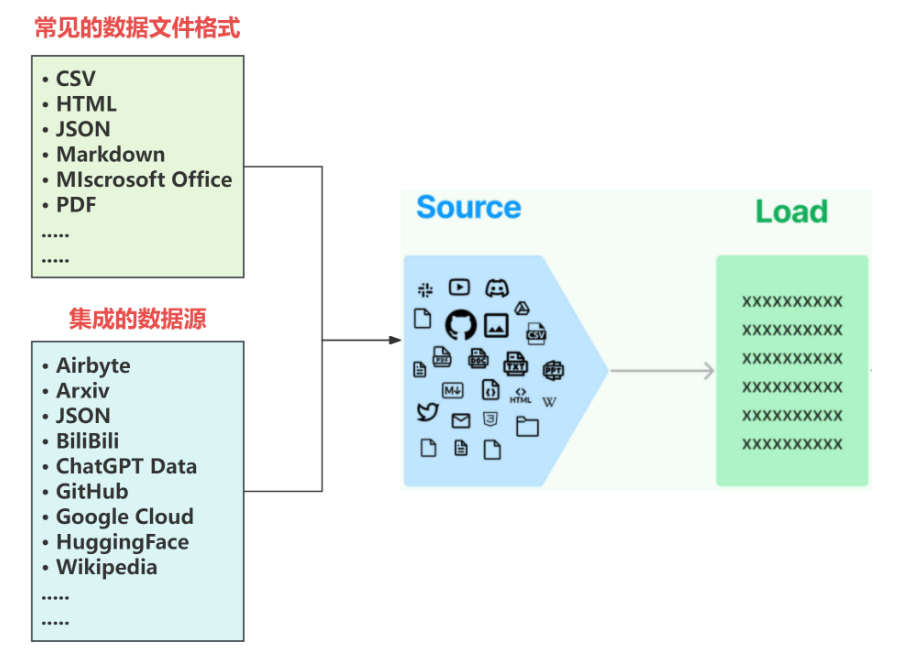
各个不同类型的文档加载器经过langChain的高度封装后使用起来并不会很复杂,可以直接调用load_documents方法,传入文件路径,就可以加载出对应的文档。这里我们进行几种不同类型的文档加载,并查看加载后的文档内容。
1.1 在线文档加载流程
我们以Wikipedia为示例,维基百科大家都比较熟悉,是一个多语言免费在线百科全书,当LangChain集成了以后,就可以按照文档说明直接调用。https://python.langchain.com/docs/integrations/document_loaders/wikipedia/
按要求安装项目依赖。
pip install -U langchain_community wikipedia
在构造方法中能非常明确的看到可以在调用时支持自定义的参数,再结合官方的说明文档,可整理出如下有效信息:
- query :用于在维基百科中查找文档的自由文本
- 可选 lang :默认=“en”。用它来搜索维基百科的特定语言部分
- 可选 load_max_docs :默认=100。用它来限制下载文档的数量。下载所有 100 个文档需要时间,因此请使用少量进行实验。目前硬性限制为 300。
- 可选 load_all_available_meta :默认=False。
默认情况下,仅下载最重要的字段: Published (文档发布/上次更新的日期)、 title 、 Summary 。如果为 True,则还会下载其他字段。
from langchain_community.document_loaders import WikipediaLoader
docs = WikipediaLoader(query="LangChain", lang = "zh", load_max_docs=2).load()
print(len(docs))
print(docs[0].metadata)2
{'title': 'LangChain', 'summary': 'LangChain 是一个应用框架,旨在简化使用大型语言模型的应用程序。作为一个语言模型集成框架,LangChain 的用例与一般语言模型的用例有很大的重叠。 重叠范围包括文档分析和总结摘要, 代码分析和聊天机器人。 \nLangChain提供了一个标准接口,用于将不同的语言模型(LLM)连接在一起,以及与其他工具和数据源的集成。LangChain还为常见应用程序提供端到端链,如聊天机器人、文档分析和代码生成。 LangChain是由Harrison Chase于2022年10月推出的开源软件项目。它已成为LLM开发中最受欢迎的框架之一。LangChain支持Python和JavaScript语言,并与各种LLM一起使用,如GPT-4、BERT和T5。', 'source': 'https://zh.wikipedia.org/wiki/LangChain'}
1.2 txt文档加载
将文件作为文本读入,并将其全部放入一个文档中,这是最简单的一个文档加载程序,使用方式如下:
from langchain.document_loaders import TextLoader
docs = TextLoader('LangChain.txt', encoding="utf-8").load() # 注意,要替换成实际的文件路径
print(docs)
[Document(metadata={'source': 'LangChain.txt'}, page_content='LangChain 是一个用于开发由大型语言模型 (LLMs) 驱动的应用程序的框架。\n\nLangChain简化了LLM应用程序生命周期的每个阶段:\n\n\t- 开发:使用LangChain的开源构建块和组件构建您的应用程序。使用第三方集成和模板开始运行。...... \n复杂的内存结构,可分析历史消息以返回最相关的结果。 \n回拨\n回调是开发人员在其应用程序中使用的代码,用于记录、监控和流式传输 LangChain 操作中的特定事件。例如,开发人员可以跟踪链首')]
从输出上,使用LangChain定义的加载器加载得到的数据类型是Document对象,这和使用WikipediaLoader加载器得到的对象类型是一致的
1.3 json文档加载
LangChain提供的JSON格式的文档加载器是JSONLoader,根据其说明,JSONLoader 使用指定的 jq 架构来解析 JSON 文件。所谓的jq,它是一个轻量级的命令行 JSON 处理器,可以通过特定的语法在命令行中对 JSON 格式的数据进行各种复杂的处理,包括数据过滤、映射、减少和转换。jq 的语法设计得非常灵活和强大,使其成为处理 JSON 数据的首选工具之一。它的主要特点包括:
- 灵活的过滤器:通过简单的过滤器表达式,可以轻松提取数据、修改数据结构或筛选出满足特定条件的数据项。
- 无需循环:与编写复杂的脚本或程序不同,jq 允许你直接应用表达式来处理数据,无需编写循环语句。
- 多样的函数:jq 提供了大量的内置函数,用于字符串处理、数值计算、数组/对象操作等,也支持自定义函数。
- 管道操作:jq 支持管道操作(类似于 UNIX/Linux 中的管道),可以将一个表达式的输出作为另一个表达式的输入,实现复杂的数据处理流程。
JsonLoader 的官方文档地址:https://python.langchain.com/docs/integrations/document_loaders/json/
比如jq 的一个基本示例是,我们可以使用它来提取 JSON 数据中的特定字段。假设有一个 JSON 文件 example.json,内容如下:
{
"employees": [
{"name": "John", "age": 30, "city": "New York"},
{"name": "Jane", "age": 25, "city": "Los Angeles"},
{"name": "Doe", "age": 28, "city": "Chicago"}
]
}可以使用 jq 的命令行工具来提取所有员工的名字,命令如下:
jq '.employees[].name' example.json这条命令会输出:
"John"
"Jane"
"Doe"既然JSONLoader是使用jq来解析JSON文件,所以在使用前,就必须进行jq库的安装。
pip install jq
import json
from pathlib import Path
from pprint import pprint
file_path='./example.json'
data = json.loads(Path(file_path).read_text(encoding="utf-8"))
pprint(data)
print(type(data)){'employees': [{'age': 30, 'city': 'New York', 'name': 'John'},
{'age': 25, 'city': 'Los Angeles', 'name': 'Jane'},
{'age': 28, 'city': 'Chicago', 'name': 'Doe'}]}
<class 'dict'>
使用JSONLoader文档加载器加载:
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(file_path=file_path, jq_schema='.employees[]', text_content=False)
docs = loader.load()
pprint(docs)[Document(metadata={'source': 'C:\\example.json', 'seq_num': 1}, page_content='{"name": "John", "age": 30, "city": "New York"}'),
Document(metadata={'source': 'C:\\example.json', 'seq_num': 2}, page_content='{"name": "Jane", "age": 25, "city": "Los Angeles"}'),
Document(metadata={'source': 'C:\\example.json', 'seq_num': 3}, page_content='{"name": "Doe", "age": 28, "city": "Chicago"}')]

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)