从部署到应用:本地大模型+RAG入门实战指南(含代码)
·
一、为什么要本地部署大模型?
| 维度 | 本地部署 | 云端 API |
|---|---|---|
| 数据隐私 | ✅ 完全本地 | ❌ 需上传 |
| 成本控制 | ✅ 一次性硬件 | ❌ Token 计费 |
| 可定制性 | ✅ 可微调、可裁剪 | ❌ 黑盒 |
| 离线运行 | ✅ 支持 | ❌ 必须联网 |
结论:如果你想私有数据、定制问答、零泄露,本地部署是唯一选择。
二、大模型基础速览(结合官方教案)
2.1 什么是大模型?
- 参数量:数十亿 → 上千亿
- 能力:文本生成、翻译、摘要、问答、多模态
- 缺陷:幻觉、知识截止、不可解释、资源消耗大
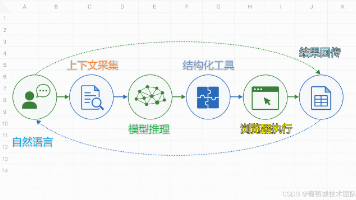
2.2 典型交互流程
三、RAG:给大模型装上「外部大脑」
3.1 为什么需要 RAG?
- 解决幻觉与知识过时
- 企业场景需要实时、可溯源的答案
3.2 RAG 经典架构
四、项目实战:30 分钟跑通聊天机器人
4.1 环境准备
# 创建虚拟环境
conda create -n llm python=3.10 -y
conda activate llm
# 核心依赖
pip install llama-index llama-index-llms-openai
pip freeze > requirements.txt
4.2 注册 DeepSeek 账号
- 官网 → deepseek.com
- 注册即送 500 万 tokens(限大陆)
- 创建 API Key:仅创建时可见,立即复制
4.3 配置 LLM(含踩坑修复)
# llms.py
from llama_index.llms.openai import OpenAI
def deepseek_llm(**kwargs):
return OpenAI(
api_key="sk-你的key",
model="deepseek-chat",
api_base="https://api.deepseek.com/v1",
temperature=0.7,
**kwargs
)
报错
Unknown model 'deepseek-chat'解决
在utils.py追加官方字典即可:
from llama_index.llms.openai.utils import ALL_AVAILABLE_MODELS, CHAT_MODELS
DEEPSEEK_MODELS = {"deepseek-chat": 64000}
ALL_AVAILABLE_MODELS.update(DEEPSEEK_MODELS)
CHAT_MODELS.update(DEEPSEEK_MODELS)
4.4 启动聊天引擎
# main.py
from llama_index.core import Settings
from llama_index.core.chat_engine import SimpleChatEngine
from llms import deepseek_llm
Settings.llm = deepseek_llm()
chat_engine = SimpleChatEngine.from_defaults()
chat_engine.streaming_chat_repl()
运行:
python main.py
出现 >>> Human: 即可开聊!
五、从聊天到 RAG:下一步怎么做?
| 阶段 | 目标 | 推荐工具 |
|---|---|---|
| ① 文档加载 | PDF/Word/网页 | llama-index-readers |
| ② 文本分块 | 合理 Chunk 大小 | SentenceSplitter |
| ③ 嵌入 | 语义向量 | text-embedding-3-small |
| ④ 向量存储 | 快速检索 | Chroma / FAISS |
| ⑤ 检索生成 | 精准回答 | llama-index QueryEngine |
后续文章将手把手实现 「本地知识库问答」,欢迎关注。
六、总结与展望
| 里程碑 | 状态 | 本篇覆盖 |
|---|---|---|
| 大模型基础 | ✅ | 概念、优缺点、交互图 |
| 本地部署 | ✅ | 30 分钟跑通 DeepSeek |
| RAG 架构 | ✅ | 原理 + 架构图 |
| 知识库实战 | 🚧 | 下一篇更新 |
路线图:
本地聊天 → RAG 知识库 → Agent 工具调用 → 多模态交互

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)