史上最全,性能TPS指标计算+接口慢排查,一篇上高速...
怎么计算得出tps指标?1)第一个通过运维那边给的生产数据,看一下生产进件有多少,计算得来的,如果没有生产数据,或者不过就看如下的方法2)第二个就是根据最近一个月的实际访问数据,比如每天调用了多少个接口,调用了哪些接口,把比例列出来==》这是通用的tps比如这100万次请求里面登录请求比例:40%那么登录接口的标准退出请求比例:20%那么退出接口的标准添加商品比例:20%那么添加商品接口的标准查询
目录:导读
前言
怎么计算得出tps指标?
1)第一个通过运维那边给的生产数据,看一下生产进件有多少,计算得来的,如果没有生产数据,或者不过就看如下的方法
2)第二个就是根据最近一个月的实际访问数据,比如每天调用了多少个接口,调用了哪些接口,把比例列出来
我举个例子,比如我们xxx系统,一个月时间,最高的一天调用接口数量最高为100万次,那么tps的计算公式如下:tps = 1000000/24*3600=11.57/sec ==》这是通用的tps
比如这100万次请求里面
登录请求比例:40% 那么登录接口的标准tps=11.57*40% = 4.63/sec
退出请求比例:20% 那么退出接口的标准tps=11.57*20% = 2.31/sec
添加商品比例:20% 那么添加商品接口的标准tps=11.57*20% = 2.31/sec
查询商品比例:10% 那么查询商品接口的标准tps=11.57*10% = 1.16/sec
修改商品比例:10% 那么修改商品接口的标准tps=11.57*10% = 1.16/sec
如上是通用的tps模型,除了上面的通用tps模型,还有添加商品和查询商品的业务模型,比如下午9点添加商品占比40%,下午16点查询商品占比20%,那么就需要重新计算了
添加商品业务模型:
首先拿到9点这一小时的数据为10万,那么tps = 100000/3600*40% = 11.1/sec
查询商品业务模型:
首先拿到16点这一小时的数据为8万,那么tps = 80000/3600*20% = 4.44/sec
性能问题1:如果500tps那并发线程数应该是多少?
首先搞清楚一个概念就是:服务器的tps是有一个阈值的 要达到500tps 用50个并发线程数和100并发线程数,或者200并发线程数 都可以达到500tps,还有一个概念并发线程数和并发用户数不是同一个概念,并发线程数是jmeter里面的线程数,而并发用户数是需要通过tps来进行承载的,这个里面的并发用户数就是500tps
再延伸一点:如果需要达到500tps并发用户数,如果并发度为1%,那么在线用户应该就是500tps/1% = 50000的在线用户,这个并发度又是怎么计算的呢?
并发度计算:50000的在线用户,在1秒内发出来了500个接口请求,那么并发度等于500/50000=1%,这个就是并发度的计算公式
注册用户计算:可以取在线用户的10-100倍,也就是50万*500万 = 50万-500万的注册用户
500tps = 50个并发线程数/0.1秒
500tps = 100个并发线程数/0.2秒
500tps = 200个并发线程数/0.4秒
…
500tps = 1000个并发线程数/2秒
总结:用更多的并发线程数来做压测或者负载,不会让服务器的tps继续往上增加,只会增加响应时间,因为每台服务器的tps是有一个上限阈值的,到了这个阈值就不会再增加了。
性能问题2:你们之前支持多少个并发?
所以经常有面试官问你,你们之前支持多少并发,其实这个并发是指的并发用户数,而不是并发线程数,并发用户数是通过tps来承载的。
你上面说的500tps,你就可以理解为并发用户数就是500tps,最高支持500个并发, 而jmeter里面的那个线程数指的是并发线程数,加大并发线程数只会让响应时间变大,而不会增加tps,并且jmeter里面线程数加到超过500,jmeter自身就会很卡。
MySQL出现慢SQL的案例分析 ==》导致数据库性能问题
TPS很低、响应时间比较长然后数据库服务器的CPU特别搞接近100%、但是应用服务器的负载比较低
索引:是MySQL数据库中一列或者多列的值进行排序的结构、使用索引可以快速访问数据库中的特定信息、有点像书的目录
分析:
数据库服务器CPU高一般都是SQL执行效率低导致的
1)数据库缺少一些索引
2)索引不生效
3)SQL语句写的不够优化
1、采用10个并发、持续300秒、在Linux服务器用jmeter -n -t test.jmx去压测
2、服务器的CPU空闲99%-100%、TPS达到300/sec左右、但是数据库服务器CPU差不多达到了100%、应用服务器的负载是比较低的
3、通过如下的方法排查MySQL数据库的可能存在的慢SQL==》性能测试中MySQL数据库慢查询使用方法
4、explain SQL语句发现 ==》rows达到20000多次说明需要找2万多次才能查询到结果、然后type也是all说明是使用了性能最差的全表扫描 ==》一般这种全表扫描是最不建议去使用的
5、然后开始给没有加索引的字段加上索引、把其中的一个字段name加上索引、索引的类型可以改为unique这个是唯一索引、字段里面的值是不能重复的、如果需要重复的可以选择索引类型为:normal、但是性能没有unique那么好
6、加完之后发现type从all变成了const、表中只有一个匹配行、从性能最差的类型变成了性能最好的type类型了
7、然后在去Linux服务器执行jmeter脚本进行压测、发现tps能达到20000了、CPU服务器空闲也剩了40%左右==》服务器的性能和能支持多少并发关系不大==》衡量服务器的性能只能是通过tps和响应时间来衡量==》性能好的服务器很少的并发也可以达到很高的tps
8、然后在把索引的类型unique改为normal、type从const变为了ref、tps瞬间变为了17000多、少了3000多的tps
通过Navicat连接上MySQL数据库然后在sql语句前加上explain,可以分析这条sql语句的执行情况
explain select * from student where name = xxx
Type列可能的值
Const:表中只有一个匹配行,用到primary key或unique key ==》性能最好
Eq_ref:唯一性索引扫描,key的所有部分被连接联接查询使用,且key是unique或primary key
ref:非唯一性索引扫描,或只使用了联合索引的最左前缀
Range:索引范围扫描,在索引列上进行给定范围内的检索,如between,in(1,100) Index:遍历索引…
All:全表扫描 ==》性能最差
Prossible key:使用哪个索引能找到行
Keys:sql语句使用的索引
rows:mysql 根据索引选择情况,估算查找数据所需读取的行数
接口响应过慢的原因排查
排查的顺序:
1、确定是哪个接口存在性能问题
2、确定这个接口的内部逻辑是怎样的,做了哪些事情
3、分析接口存在性能问题的根本原因
4、寻找确立优化方案
5、回归验证方案效果
接口慢排查:
一般会从以下几个方面入手:
1、是不是资源层面的瓶颈,硬件、配置环境之类的问题
2、针对查询类接口,是不是没有添加缓存,如果加了,是不是热点数据导致负载不均衡
3、是不是有依赖于第三方接口,导致因第三方请求拖慢了本地请求
4、是不是接口涉及业务太多,导致程序执行跑很久
5、是不是sql层面的问题导致的数据等待加长,进而拖慢接口
6、网络层面的原因?带宽不足?DNS解析慢
7、确实是代码质量差导致的,如出现内存泄漏,重复循环读取之类
完整版!企业级性能测试实战,速通Jmeter性能测试到分布式集群压测教程
| 下面是我整理的2025年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
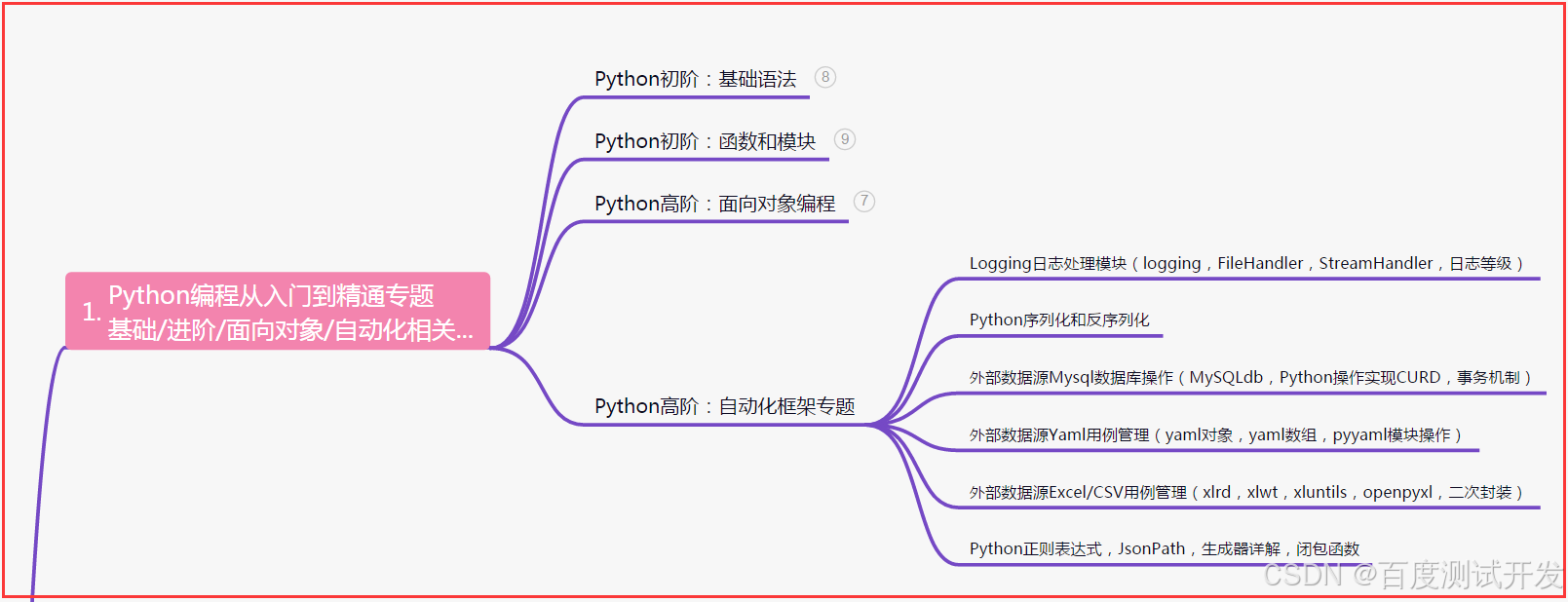
二、接口自动化项目实战
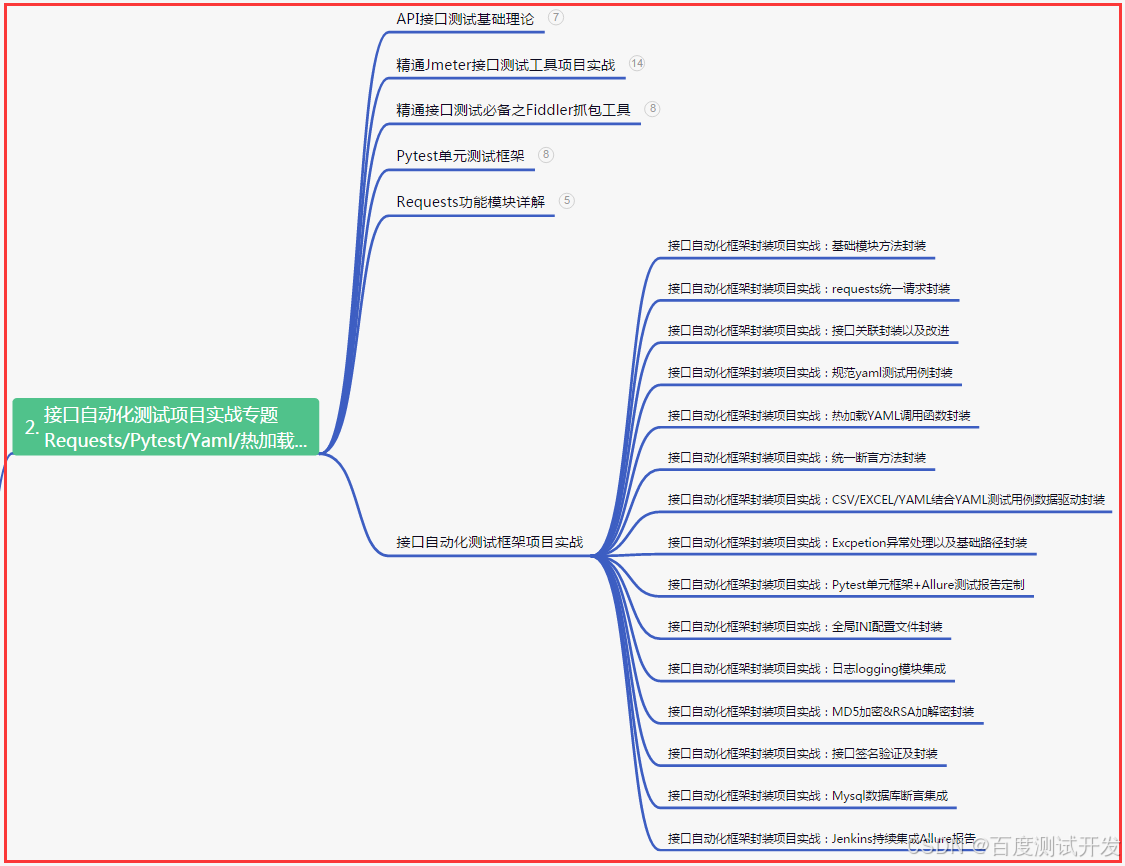
三、Web自动化项目实战
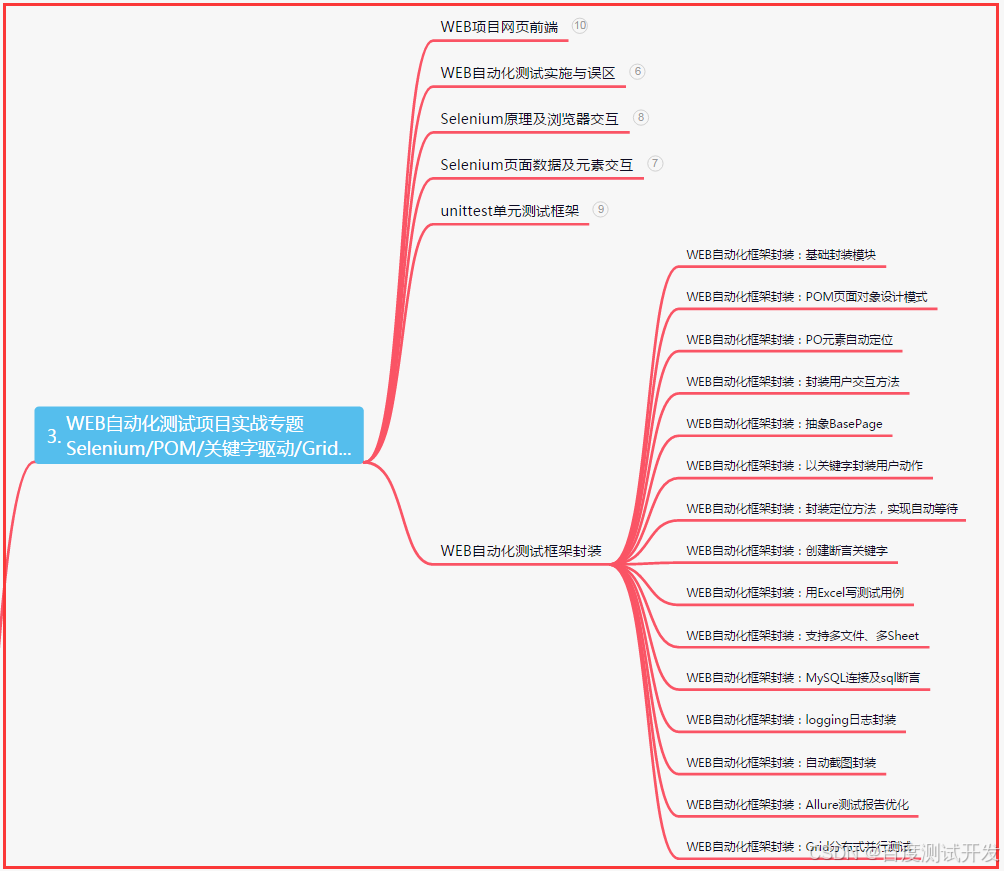
四、App自动化项目实战
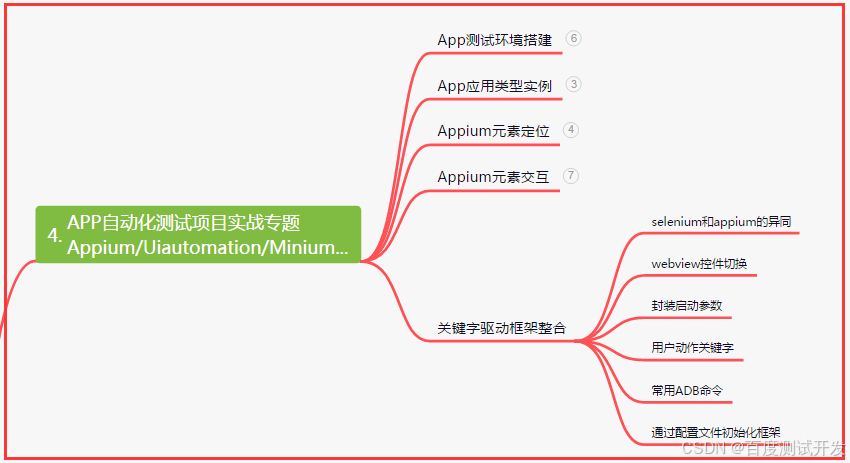
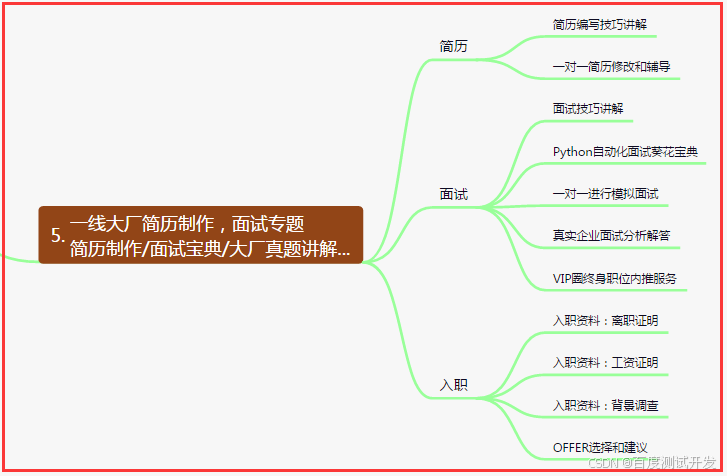
五、一线大厂简历
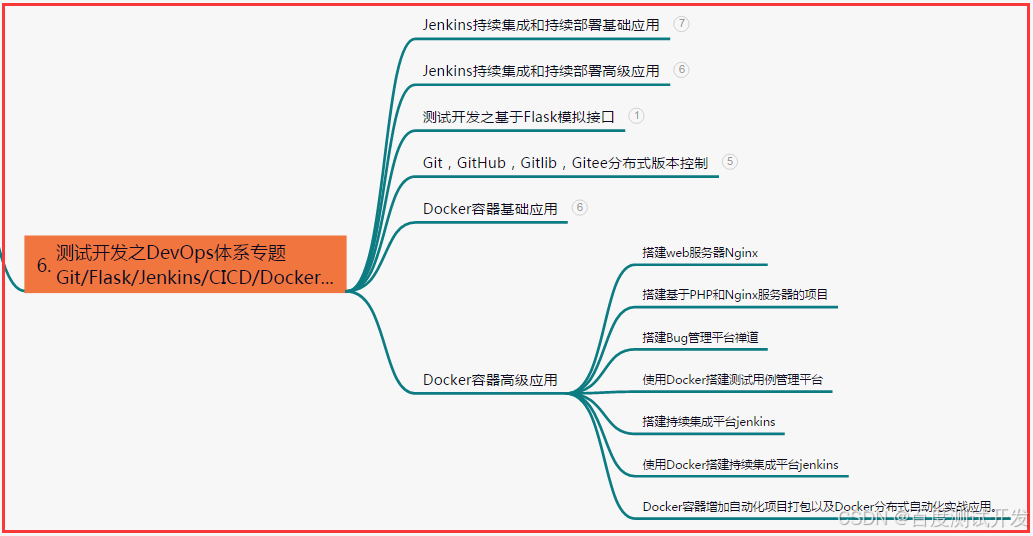
六、测试开发DevOps体系
七、常用自动化测试工具

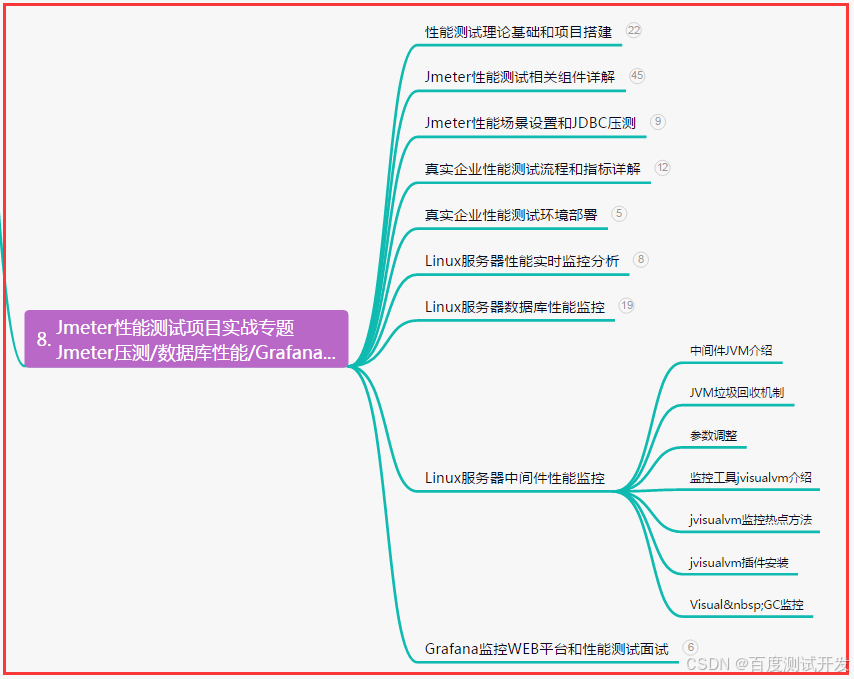
八、JMeter性能测试
九、总结(尾部小惊喜)
人生最珍贵的不是终点站的掌声,而是追梦路上的每一个脚印。当你觉得疲惫时,请记住:钻石经过打磨才能璀璨,雄鹰经历断羽才能高飞。你的坚持,正在书写属于自己的传奇篇章!
别让任何人定义你的极限!你拥有的不是天花板,而是等待突破的起点。那些看似不可能的梦想,终将在你日复一日的坚持中变得触手可及。你,就是自己人生的造梦者!

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)