别再只看准确率了!搞懂这4个评估指标,才算真正入门AI模型评估
评估AI模型性能需区分准确率、精确率、召回率和F1分数。准确率衡量整体正确率但易受样本不均衡影响;精确率关注预测正例的准确性,适用于FP代价高的场景;召回率关注真实正例的识别率,适用于FN代价高的场景;F1分数则平衡精确率和召回率,适用于两者都需兼顾的情况。根据业务需求选择合适的评估指标才能有效判断模型效果。
在AI模型落地前,“这个模型准不准”是绕不开的问题。但“准”的定义并非单一维度——有时要抓牢所有目标,有时要避免误判,这就需要精准区分准确率、精确率、召回率,再用F1分数平衡关键指标。下面用“垃圾分类模型”(识别“可回收物”为正例)举例,带大家从基础到公式彻底吃透:
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/RIg3YDA4OknbG6BGqrP5Vw
https://mp.weixin.qq.com/s/RIg3YDA4OknbG6BGqrP5Vw

一、先搞懂“评估的基石”:混淆矩阵
所有指标都源于“模型预测结果”与“真实情况”的4种组合,这就是混淆矩阵,以二分类任务(只有“正例P”和“负例N”)为例:
-
TP(True Positive,真正例):真实是正例,模型也预测为正例
例:真实是“可回收物”,模型正确识别为“可回收物” -
TN(True Negative,真负例):真实是负例,模型也预测为负例
例:真实是“厨余垃圾”,模型正确识别为“非可回收物” -
FP(False Positive,假正例):真实是负例,模型误判为正例(“冤枉好人”)
例:真实是“厨余垃圾”,模型错判为“可回收物” -
FN(False Negative,假负例):真实是正例,模型误判为负例(“放过坏人”)
例:真实是“可回收物”,模型错判为“非可回收物”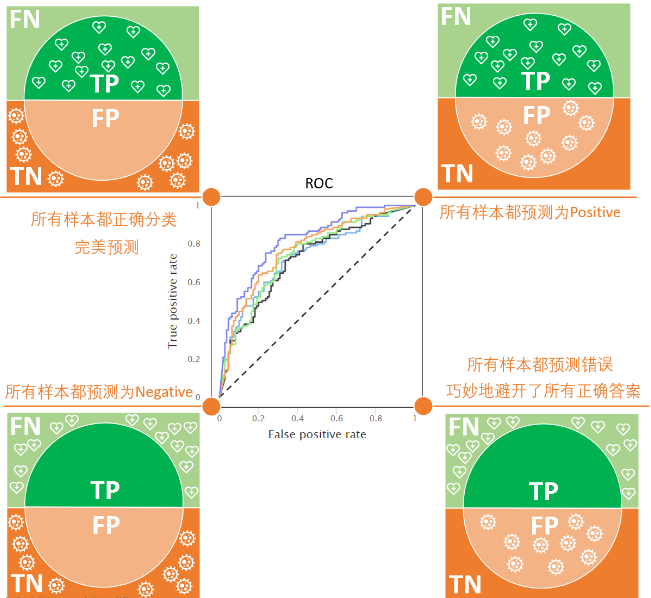
记住这4个值,后面所有指标都是它们的“组合计算”。
二、逐个拆解核心指标:定义+公式+适用场景
1. 准确率(Accuracy):“整体对不对”,最直观但易误导
定义
模型预测正确的样本数,占总样本数的比例——反映“整体预测准确率”,是最容易理解的指标。
公式
预测正确的样本数总样本数
适用场景
-
正负样本分布均衡的场景(如普通分类任务,正例、负例各占50%);
-
对“整体正确率”要求高,且误判正例、误判负例代价相近的场景(如学生考试分数预测“及格/不及格”)。
注意坑点
若样本极度不均衡(如“疾病诊断”,患病者仅占1%),模型全预测“未患病”(TN极高,TP=0),准确率仍能达到99%,但完全没用——因此不均衡场景下,准确率不能单独作为核心指标。
2. 精确率(Precision):“预测为正的,到底对不对”,防“误判”
定义
模型预测为“正例”的样本中,真正是正例的比例——核心是“控制假阳性(FP)”,避免“把负例错当正例”。
公式
真正是正例的预测正例数所有预测为正例的样本数
适用场景
-
误判正例(FP)代价高的场景:
▶ 垃圾邮件识别:把“正常邮件”错判为“垃圾邮件”(FP),会导致用户漏看重要信息,因此需要高精确率;
▶ 电商“推荐商品”:推荐的商品若用户不喜欢(FP),会降低用户体验,需保证“推荐的大多是用户想要的”。
例子
若模型预测100个“可回收物”(TP+FP=100),其中只有80个是真的可回收物(TP=80),则精确率=80/100=80%——意味着“模型说‘是可回收’的,80%是对的”。
3. 召回率(Recall,也叫查全率):“真实是正的,到底找没找全”,防“漏判”
定义
所有真实正例中,被模型成功预测为正例的比例——核心是“控制假阴性(FN)”,避免“把正例错当负例”。
公式
被正确预测的正例数所有真实正例数
适用场景
-
误判负例(FN)代价高的场景:
▶ 疾病诊断:把“患病者”错判为“健康人”(FN),会延误治疗,因此需要高召回率(尽可能把所有患者都找出来);
▶ 火灾报警:漏判“真实火灾”(FN)会导致重大事故,需保证“所有真实火灾都能被检测到”。
例子
若实际有100个“可回收物”(TP+FN=100),模型只识别出70个(TP=70),则召回率=70/100=70%——意味着“真实的可回收物,70%被模型找到了”。
4. F1分数(F1-Score):平衡精确率和召回率,解决“两难问题”
为什么需要F1?——精确率和召回率的“矛盾性”
精确率和召回率往往是“此消彼长”的:
-
想让“预测的正例更准”(提高精确率):会收紧判断标准(比如只把“100%像可回收物”的样本判为正例),但会漏掉部分模糊的正例(降低召回率);
-
想让“真实正例全找到”(提高召回率):会放宽判断标准(比如“80%像可回收物”就判为正例),但会引入更多负例(降低精确率)。
此时需要一个指标,综合两者表现——这就是F1分数。
定义
精确率(P)和召回率(R)的调和平均数,能同时反映两者水平,且更偏向“较低值”(避免某一指标极低、另一极高时,分数虚高)。
公式
首先计算调和平均(避免算术平均的缺陷):
代入P和R的原始公式,也可写成:
适用场景
-
精确率和召回率都需要兼顾,且两者重要性相近的场景:
▶ 人脸识别(门禁系统):既不能把“陌生人”错判为“用户”(FP,安全风险,需高P),也不能把“用户”错判为“陌生人”(FN,用户体验差,需高R),因此用F1平衡;
▶ 文本分类(如“新闻分类为体育/财经”):既不能把“财经新闻”错归为“体育”(FP),也不能漏掉“体育新闻”(FN),需F1评估整体效果。
例子
若模型精确率=80%,召回率=70%,则F1=2*(0.80.7)/(0.8+0.7)=20.56/1.5≈0.747,即74.7%——反映模型在“准”和“全”之间的综合表现。
三、一句话总结:什么时候用哪个指标?
-
看整体均衡场景 → 准确率;
-
怕“错把负当正”(FP代价高) → 精确率;
-
怕“错把正当负”(FN代价高) → 召回率;
-
既怕错判又怕漏判 → F1分数。
下次评估模型时,别再只看“准确率”啦!根据业务场景选对指标,才能真正判断模型“好不好用”~
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/RIg3YDA4OknbG6BGqrP5Vw
https://mp.weixin.qq.com/s/RIg3YDA4OknbG6BGqrP5Vw

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)