数据库死锁:高并发场景下的“幽灵”,常见场景解决办法
数据库死锁是高并发下的常见问题,指多个事务互相持有对方所需资源而无限等待。其发生需满足互斥、请求保持、不可剥夺和循环等待四个条件。诊断死锁需捕获死锁日志(如SQL Server的Trace Flag 1222、MySQL的SHOW ENGINE INNODB STATUS),分析锁竞争关系。解决方案包括:1)终止阻塞事务;2)优化事务设计(减小粒度、统一访问顺序);3)使用乐观锁;4)合理设置隔离
数据库死锁是高并发场景下的“幽灵问题”——它往往突然发生,导致业务中断,且排查起来需要结合数据库原理、日志分析和场景还原。以下内容从基础原理→诊断方法→应急解决→长效预防展开,覆盖主流数据库(SQL Server/MySQL/Oracle),帮你系统掌握死锁的应对之道。

一、先搞懂:死锁的本质与必要条件
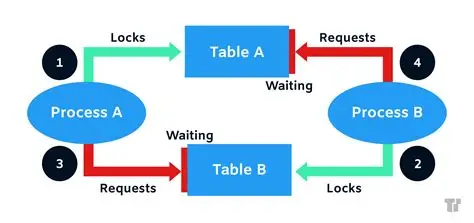
死锁是指两个或多个事务互相持有对方需要的锁,且都不愿释放,导致所有事务无限等待的状态。其发生的四个必要条件(缺一不可):
- 互斥:资源(如行、页、表)一次只能被一个事务占用;
- 请求与保持:事务已持有某个资源,又请求新的资源(且不释放已有资源);
- 不可剥夺:资源不能被强制从持有事务中夺走;
- 循环等待:事务间形成“事务A等事务B的资源,事务B等事务A的资源”的闭环。

二、死锁的诊断:如何快速定位问题?
诊断死锁的核心是还原“死锁环”——即找出哪些事务、访问了哪些资源、持有哪些锁、等待哪些锁。以下是各数据库的常用诊断工具和方法:
1. 通用诊断步骤
不管用什么数据库,诊断死锁的流程基本一致:
- Step 1:捕获死锁事件:开启数据库的死锁日志记录(如SQL Server的Trace Flag 1222、MySQL的
innodb_print_all_deadlocks); - Step 2:收集现场证据:获取死锁时的锁信息、事务历史、SQL语句;
- Step 3:分析死锁环:通过工具还原事务的锁请求顺序,找到循环等待的源头。
2. 主流数据库的具体诊断方法
(1)SQL Server
SQL Server提供了丰富的DMV(动态管理视图)和工具来诊断死锁:
- ① 查看死锁错误日志:
SQL Server的1205错误(死锁牺牲品)会记录死锁详情,可通过ERRORLOG或sys.dm_os_ring_buffers查询:-- 查询最近的死锁信息 SELECT * FROM sys.dm_os_ring_buffers WHERE ring_buffer_type = 'RING_BUFFER_DEADLOCK_CHAIN'; - ② 用DMV还原死锁环:
结合sys.dm_tran_locks(锁信息)、sys.dm_os_waiting_tasks(等待任务)、sys.dm_exec_requests(执行请求)分析:-- 查找当前死锁的事务和锁 SELECT tl.request_session_id AS spid, tl.resource_type, tl.resource_associated_entity_id, tl.request_mode, tl.request_status, er.blocking_session_id, er.command, sqltext.text AS sql_statement FROM sys.dm_tran_locks tl INNER JOIN sys.dm_os_waiting_tasks w ON tl.lock_owner_address = w.resource_address INNER JOIN sys.dm_exec_requests er ON w.session_id = er.session_id CROSS APPLY sys.dm_exec_sql_text(er.sql_handle) sqltext WHERE w.wait_type LIKE 'LCK%'; -- 锁等待类型 - ③ 工具辅助:
- Extended Events:捕获
xml_deadlock_report事件,生成死锁的XML报告(可视化死锁环); - SQL Profiler:跟踪死锁事件(需谨慎,性能开销大)。
- Extended Events:捕获
(2)MySQL(InnoDB)
MySQL的InnoDB引擎通过SHOW ENGINE INNODB STATUS命令查看死锁信息:
- ① 开启死锁日志:在
my.cnf中设置innodb_print_all_deadlocks = ON,死锁信息会写入错误日志; - ② 查看死锁详情:
执行SHOW ENGINE INNODB STATUS;,切换到LATEST DETECTED DEADLOCKsection,会显示:- 死锁的两个事务的SQL语句;
- 每个事务持有的锁(如行锁、间隙锁);
- 等待的锁资源。
(3)Oracle
Oracle通过AWR报告或ASH分析定位死锁:
- ① 查看死锁日志:查询
V$LOCK和V$SESSION视图:-- 查找死锁的会话 SELECT s.sid, s.serial#, s.username, l.type, l.id1, l.id2 FROM v$lock l INNER JOIN v$session s ON l.sid = s.sid WHERE l.block = 1; -- 阻塞其他会话的锁 - ② 生成死锁跟踪文件:设置
EVENT 10046 TRACE NAME CONTEXT FOREVER, LEVEL 12,生成包含死锁详情的跟踪文件(需用TKPROF解析)。
三、死锁的应急解决:先止损,再排查
一旦发生死锁,需快速恢复业务,再分析根源:
1. 紧急处理方法
- ① 终止牺牲品事务:数据库会自动选择一个事务作为“牺牲品”(返回1205/1213错误),但有时需手动终止阻塞事务:
- SQL Server:
KILL <SPID>; - MySQL:
KILL <CONNECTION_ID>; - Oracle:
ALTER SYSTEM KILL SESSION '<SID>,<SERIAL#>'。
- SQL Server:
- ② 回滚长事务:如果某个长事务持有大量锁,主动回滚它可以快速释放资源。
2. 避免“二次死锁”
- 不要盲目重启数据库:重启会清除锁信息,但可能丢失现场;
- 检查应用程序的重试逻辑:死锁后应用程序应指数退避重试(如等待1秒→2秒→4秒,最多3次),避免立即重试加重负载。

四、死锁的长效预防:从设计到运维的闭环
预防死锁的核心是破坏死锁的四个必要条件,以下是具体措施:
1. 设计阶段:从源头减少死锁可能
-
① 减少事务粒度:
将大事务拆分为小事务(如批量更新拆成逐条或分批次),缩短锁的持有时间。例如:
❌ 坏实践:UPDATE table SET col=1 WHERE id IN (1..10000);(持有大量锁);
✅ 好实践:循环更新100条/批,每批提交一次。 -
② 统一资源访问顺序:
所有事务都按相同的顺序访问表或行(如先访问表A再访问表B,不要有的事务先A后B,有的先B后A)。例如:
事务1:更新表X→更新表Y;
事务2:必须也更新表X→更新表Y(避免循环等待)。 -
③ 避免长事务:
不要在事务中做无关操作(如查询大量数据、调用外部API、等待用户输入),这些操作会延长锁的持有时间。

2. 技术手段:用数据库特性降低死锁概率
-
① 选择合适的隔离级别:
高隔离级别(如SQL Server的Serializable、MySQL的Repeatable Read)会增加锁的竞争,尽量使用读已提交快照隔离(RCSI)或乐观并发:- SQL Server:开启
READ_COMMITTED_SNAPSHOT,事务读取时用行版本控制,不持有共享锁; - MySQL:使用
READ COMMITTED隔离级别(减少间隙锁); - Oracle:默认的
READ COMMITTED+行版本控制(Undo表空间)。
- SQL Server:开启
-
② 使用乐观锁:
用版本号或时间戳代替悲观锁,避免长时间持有排他锁。例如:
表结构增加version字段,更新时检查版本:UPDATE table SET col=1, version=version+1 WHERE id=123 AND version=old_version;如果更新失败(版本号变了),说明数据已被修改,应用程序重试即可。
-
③ 优化索引:
缺少索引会导致全表扫描,获取更多锁(如更新一个无索引的列,会锁整行甚至整表)。确保:- WHERE条件中的列有索引;
- 连接条件中的列有索引;
- 避免索引失效(如函数转换、类型隐式转换)。
3. 运维层面:监控与预警
-
① 实时监控锁等待:
用Prometheus+Grafana或数据库自带工具监控锁指标:- SQL Server:
sys.dm_os_waiting_tasks(等待任务数)、sys.dm_tran_locks(锁持有数); - MySQL:
SHOW GLOBAL STATUS LIKE 'Innodb_row_lock%'(行锁等待数、超时数); - Oracle:
V$LOCK(锁数量)、V$SESSION_WAIT(等待事件)。
- SQL Server:
-
② 设置死锁告警:
当死锁次数超过阈值(如1分钟1次)时,触发邮件/钉钉告警,及时排查。
4. 测试阶段:模拟高并发场景
- 用JMeter/LoadRunner模拟高并发请求,提前暴露死锁问题;
- 对核心业务流程做压力测试,验证锁竞争情况。
五、常见死锁场景与解决方法
以下是高频死锁场景及针对性解决方案:

1. 交叉更新死锁
场景:事务1更新行A→更新行B;事务2更新行B→更新行A,形成循环等待。
解决:统一资源访问顺序(如都先更新A再更新B)。
2. 间隙锁死锁(MySQL特有)
场景:MySQL的RR隔离级别下,更新非唯一索引列会加间隙锁(锁定范围内的空闲行),多个事务的间隙锁重叠导致死锁。
解决:
- 升级到RC隔离级别(禁用间隙锁);
- 优化查询条件,使用唯一索引;
- 减少事务的持有时间。
3. 外键约束死锁
场景:主表删除行时,会锁子表的对应行;如果子表有未提交的事务,主表删除会被阻塞,进而导致死锁。
解决:
- 禁用外键约束(不推荐,破坏数据一致性);
- 先删除子表相关行,再删除主表行;
- 使用
ON DELETE CASCADE自动级联删除。

六、总结:吃一堑长一智的关键
死锁的本质是资源竞争的闭环,预防的核心是减少竞争、统一顺序、缩短锁持有时间。记住以下几点:
- 日志是关键:开启死锁日志记录,快速定位问题;
- 设计优先:从事务粒度、访问顺序、索引优化入手,减少死锁可能;
- 监控兜底:实时监控锁指标,提前预警;
- 重试机制:应用程序必须有死锁重试逻辑,避免业务中断。
通过以上体系化的方法,你可以从“被动救火”转向“主动预防”,大幅降低死锁的发生概率——毕竟,最好的解决是让死锁永远不会发生。


葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐

 58
58 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)