01|Langgraph | 从入门到实战 | 基础篇
深入解析了LangGraph构建AI Agent的核心技术要点。从基础架构开始,详细介绍了状态机定义、图构建流程和节点类型,从简单聊天Agent到复杂财务审批系统的完整演进过程
一、简介
本系列为Langgraph文章,最终以实现企业级项目。

该系列文章,以官方文档路径撰写,深入浅出并配以自己理解,配以GIF动图演示、适当扩展延伸官方案例以及源码讲解
当然如果你需要你也可以查看官方文档
最终实战项目目标:构建一个Agents Framework(智能代理框架) 多智能体协作企业系统
- 📊 Agent-Graph:每个业务 Agent 以状态图形式编排节点、条件边与循环边;
- 🔧 工具体系:自动发现与注册工具,支持函数调用(tool calling),可扩展MCP服务;
- 🗄️ 记忆/持久化:使用 Postgres 作为 LangGraph 的 checkpointer 与 store,Redis缓存prompt;
- 📋 统一注册中心:自动发现、注册并预编译 Agent 图与工具;
- 💪 滚动窗口摘要算法压缩上下文,用户画像,短期记忆,长期记忆混合
- 🌐 API 网关:FastAPI 路由聚合,提供通用 chat、agents、session 等接口;
- 🔄 可插拔 LLM:通过模型工厂与配置驱动,统一管理多厂商 LLM。
- 🌀 prompt缓存:redis加载prompt,prompt-web热更新管理
- 👁️🗨️ RAG 向量数据库,与工程结合,结构化,非结构化管理检索,召回
- 🥰 下一步引导功能,猜你想要功能

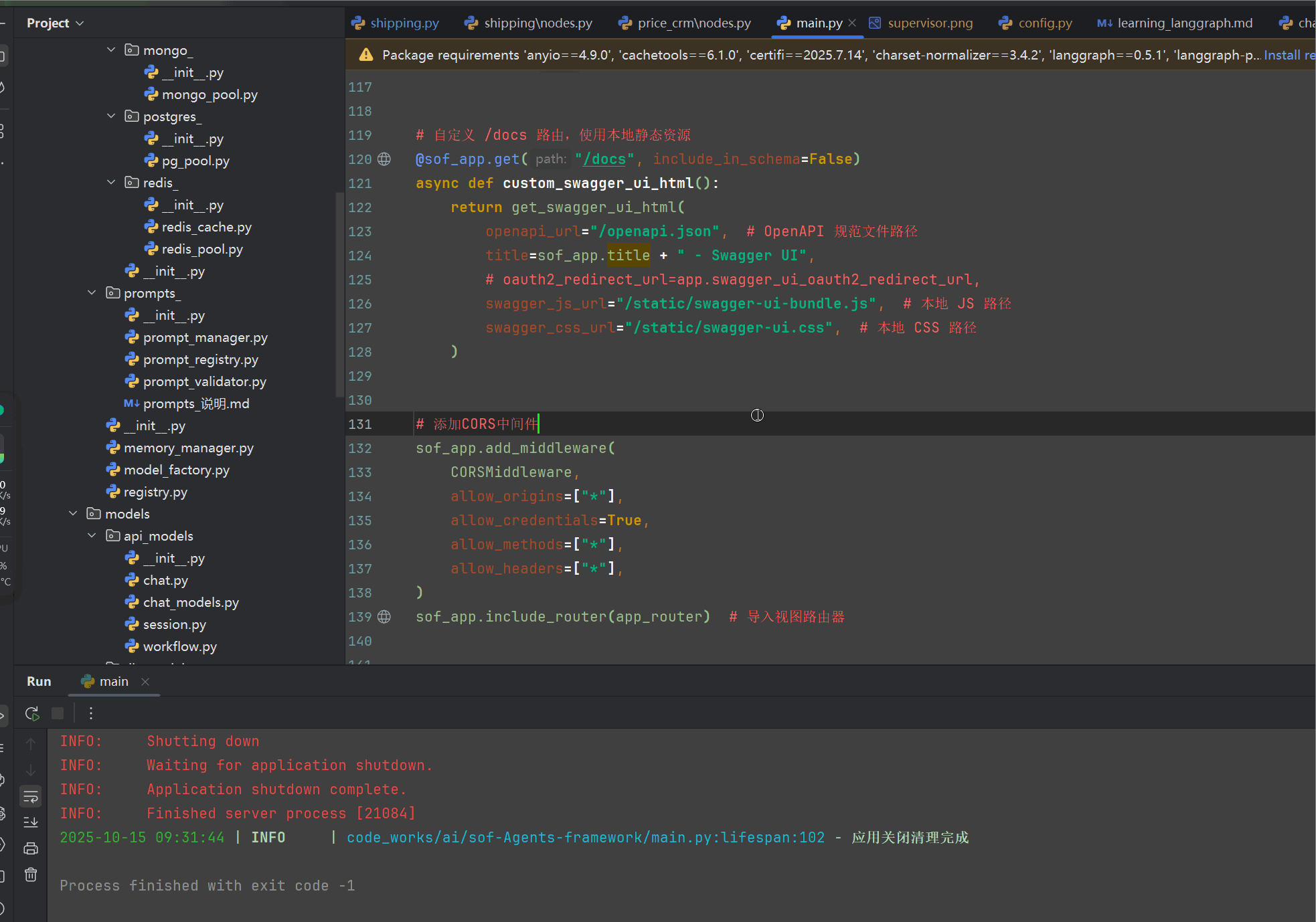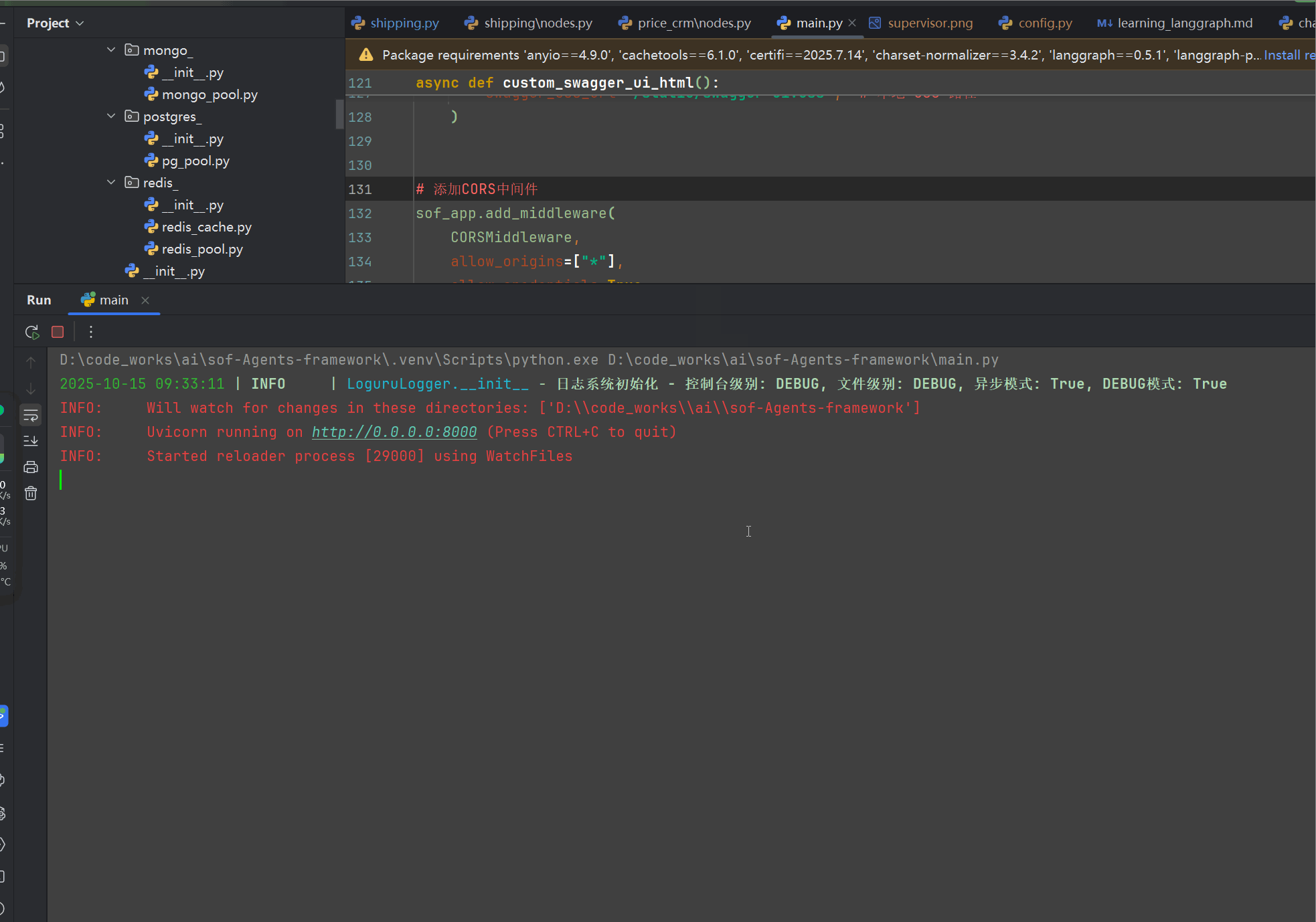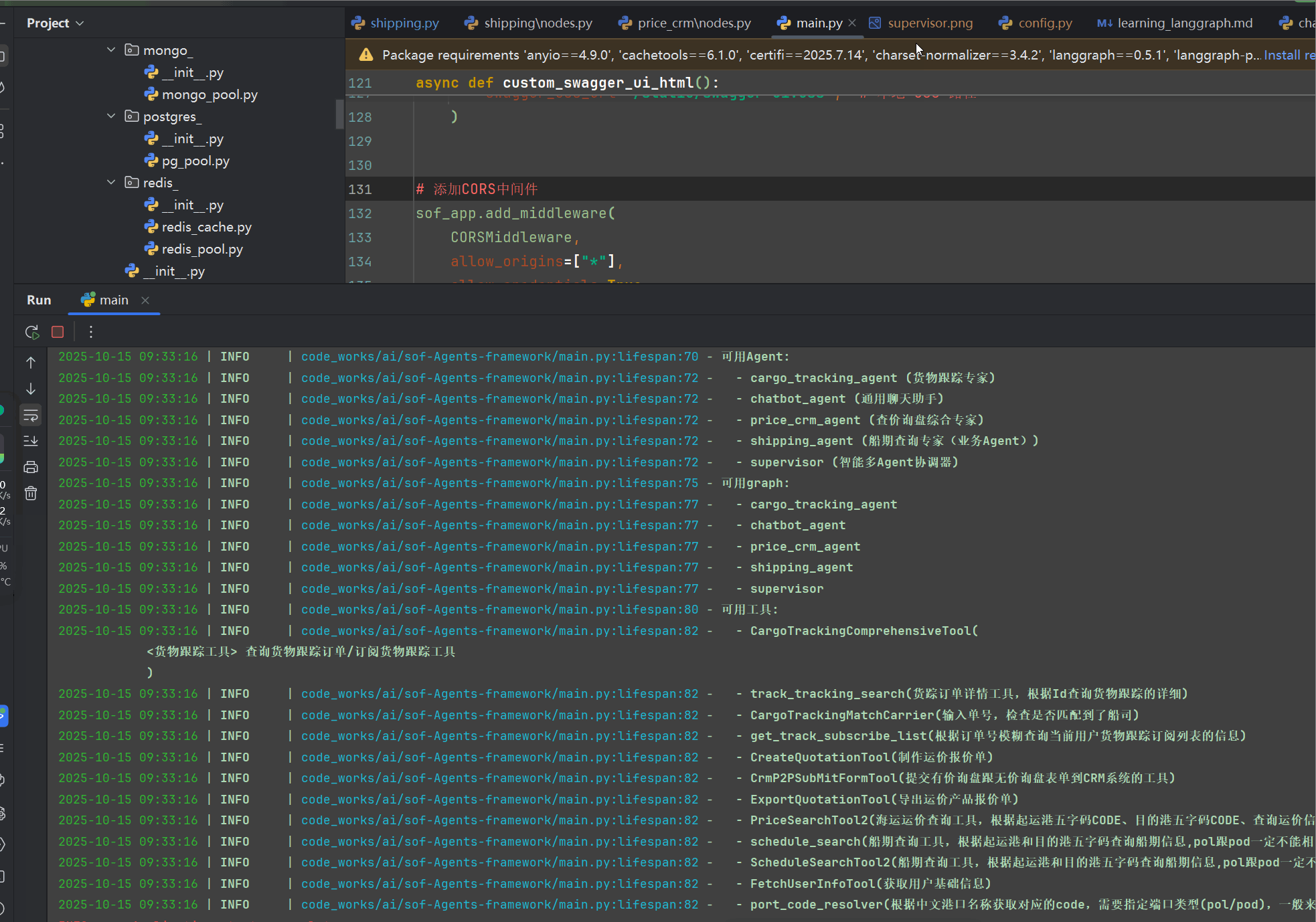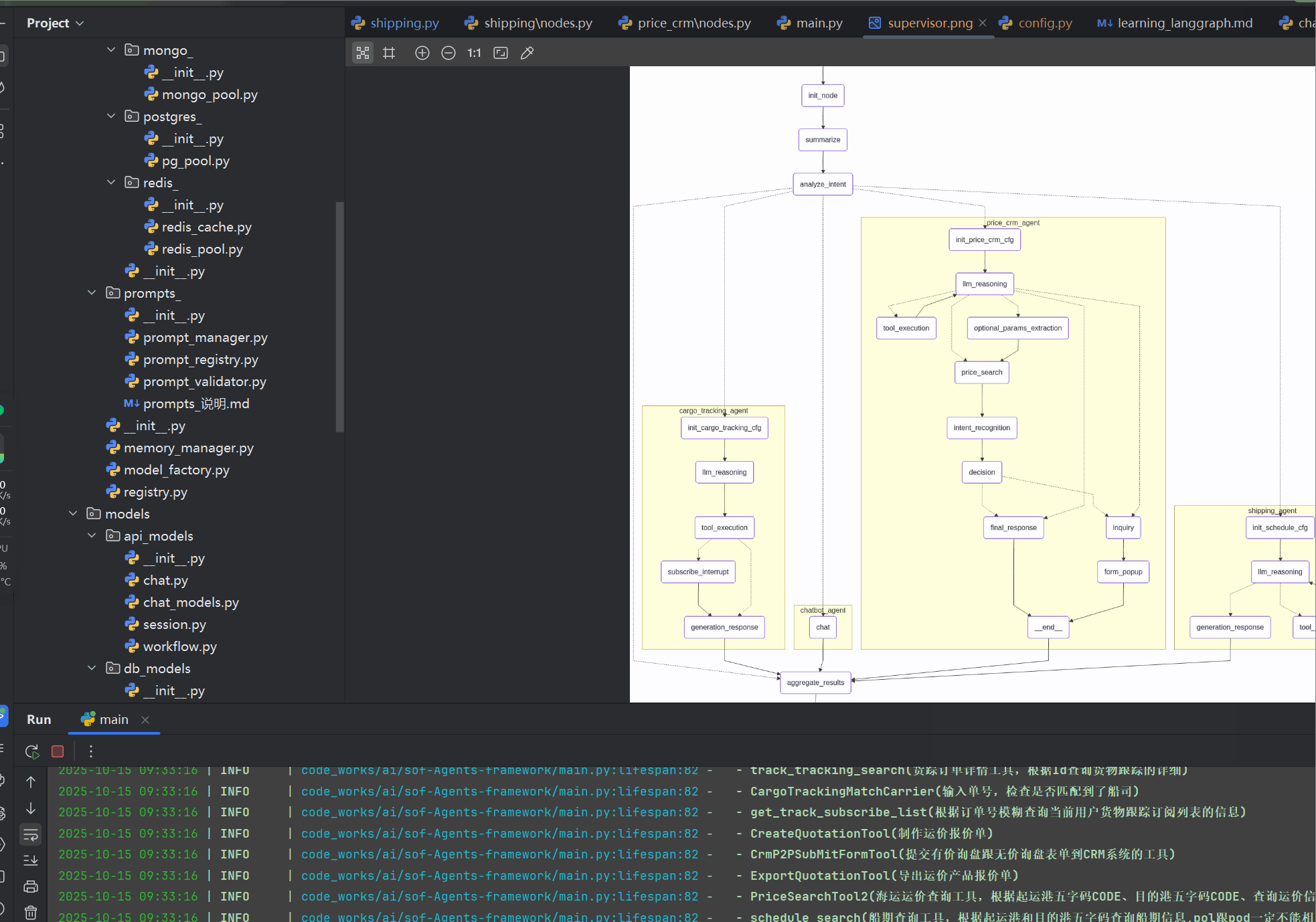
本系列文章,配套项目源码地址:
https://github.com/wenwenc9/langgraph-tutorial-wenwenc9
langchain的系列文章(相信我把Langchain全部学一遍,你能深入理解AI的开发)
01|LangChain | 从入门到实战-介绍
02|LangChain | 从入门到实战 -六大组件之Models IO
03|LangChain | 从入门到实战 -六大组件之Retrival
04|LangChain | 从入门到实战 -六大组件之Chain
05|LangChain | 从入门到实战 -六大组件之Memory
06|LangChain | 从入门到实战 -六大组件之Agent
二、LangGraph基础
1、什么是LangGraph?
LangGraph是一个基于图的高级编排框架,专门用于构建AI代理。它建立在LangChain之上,通过状态图来管理代理之间的交互,相比传统的线性工作流提供了更强大的功能。
官方地址:https://github.com/langchain-ai/langgraph
核心特点
- 图形化架构:使用有向图表示代理工作流,支持循环和条件分支
- 内置持久化:自动管理状态持久化和工作流进度保存
- 循环处理:支持代理与工具的重复交互,创建反馈循环
- 人机集成:内置人工介入操作支持,允许专家审查和干预
- 状态管理:跨所有组件维护共享状态,实现无缝通信
与LangChain的区别
- LangChain:提供基础功能,适合简单的线性工作流,需要手动设置内存、持久化等
- LangGraph:提供更复杂的能力,支持状态管理、循环工作流和人工监督的开箱即用功能
关键组件
- 节点(Nodes):执行特定任务的处理单元
- 边(Edges):节点之间的连接和关系,决定信息流向
- 状态管理(State Management):维护代理操作的当前上下文和进度
白话文:想象一下,给你一张白纸,你可以创建很多点Nodes(工具/agent…)都可以视作点,然后用边连线Edges(完成业务逻辑),其中点与点之间的交流是是通过State来沟通的
2、快速入门
2.1 创建一个Agent代理
- langgraph.prebuilt 公开了一个更高级别的 API,用于创建和执行代理和工具。
- 下面这个案例,使用的是豆包的模型
你也可以尝试使用这个方法也行:https://python.langchain.com/docs/integrations/chat/volcengine_maas/
from langgraph.prebuilt import create_react_agent
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"关于{city},的天气一直很好!"
agent = create_react_agent(
model=f"openai:{modelName}", # 目前没有豆包的,但是使用openai的格式是可以调通的
tools=[get_weather],
prompt="You are a helpful assistant",
)
res = agent.invoke(
{"messages": [{"role": "user", "content": "北京的天气如何?"}]}
)
rich.print(res)
输出如下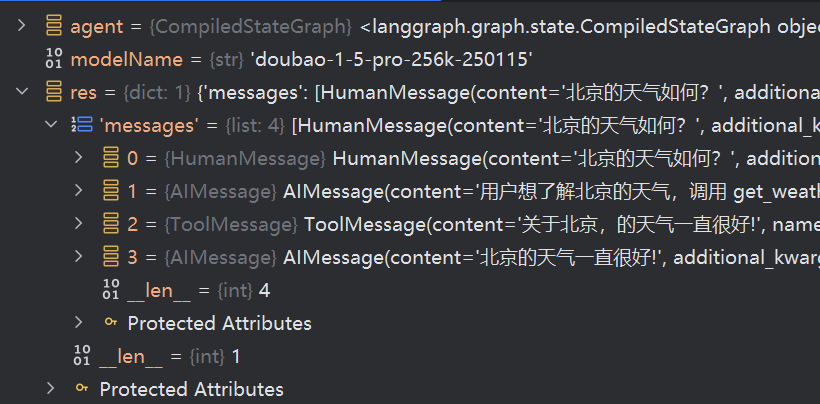
2.2 自定义Agent
有时候想要调整模型的温度,相对于前面传入字符串,这里也可以传入model实例,在构建实例的时候
就可以指定如temperature 模型温度进行操作
from langchain.chat_models import init_chat_model
from langgraph.prebuilt import create_react_agent
# 通过这个方法可以设置模型温度等操作
model = init_chat_model(
f"openai:{modelName}",
temperature=0
)
# create_react_agent 不仅可以传入字符串,现在也可以传入模型实例
agent = create_react_agent(
model=model,
tools=[get_weather],
)
2.3 为代理加上prompt
2.3.1 静态pormpt
prompt=strprompt不可变
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(
model=f"openai:{modelName}",
tools=[get_weather],
prompt="你是一个智能助手,拒绝回复用户天气相关的问题"
)
res = agent.invoke(
{"messages": [{"role": "user", "content": "深圳的天气如何?"}]}
)
rich.print(res)
输出
2.3.2 动态pormpt
这里prompt=func即可做到
动态prompt允许我们根据运行时的状态和配置动态生成系统提示词,而不是使用固定的静态文本。
主要优势:
- 个性化交互:可以根据用户信息(如用户名、偏好设置等)动态调整提示词
- 上下文感知:能够根据当前对话状态、历史消息等信息调整AI的行为
- 灵活配置:通过
RunnableConfig传递配置参数,无需修改代码就能改变行为 - 多租户支持:在同一个agent实例中为不同用户提供不同的服务体验
使用场景举例:
- 根据用户VIP等级调整服务态度和详细程度
- 根据用户所在地区调整语言和文化习惯
- 根据业务规则动态添加或移除某些限制
- 在多用户系统中为每个用户提供个性化的助手
from langchain_core.messages import AnyMessage
from langchain_core.runnables import RunnableConfig
from langgraph.prebuilt.chat_agent_executor import AgentState
from langgraph.prebuilt import create_react_agent
def prompt(state: AgentState, config: RunnableConfig) -> list[AnyMessage]:
user_name = config["configurable"].get("user_name")
system_msg = f"你是一个智能助手。请称呼用户为{user_name}。"
return [{"role": "system", "content": system_msg}] + state["messages"]
agent = create_react_agent(
model=f"openai:{modelName}",
tools=[get_weather],
prompt=prompt
)
res = agent.invoke(
{"messages": [{"role": "user", "content": "上海的天气怎么样"}]},
config={"configurable": {"user_name": "张先生","token":"wenwenc9"}}
)

实战案例:根据VIP等级提供不同服务
RunnableConfig 这个方法为透传方法,没有必要纠结,就是一个代理运行时候全局贯串,可以取很多内容
from langchain_core.messages import AnyMessage
from langchain_core.runnables import RunnableConfig
from langgraph.prebuilt.chat_agent_executor import AgentState
from langgraph.prebuilt import create_react_agent
def vip_prompt(state: AgentState, config: RunnableConfig) -> list[AnyMessage]:
"""根据用户VIP等级动态调整服务质量"""
user_name = config["configurable"].get("user_name", "用户")
vip_level = config["configurable"].get("vip_level", 0)
if vip_level >= 3:
system_msg = f"你是一位专业的高级顾问。请以最尊敬和详细的方式为尊贵的{user_name}提供服务,提供深度分析和建议。"
elif vip_level >= 1:
system_msg = f"你是一位友好的助手。请为{user_name}提供周到的服务和详细的信息。"
else:
system_msg = f"你是一个智能助手。请简洁地回答{user_name}的问题。"
return [{"role": "system", "content": system_msg}] + state["messages"]
# 创建使用动态prompt的agent
vip_agent = create_react_agent(
model=f"openai:{modelName}",
tools=[get_weather],
prompt=vip_prompt
)
# 测试不同VIP等级的服务体验
print("=== 普通用户 (VIP 0) ===")
result1 = vip_agent.invoke(
{"messages": [{"role": "user", "content": "广州的天气如何?"}]},
config={"configurable": {"user_name": "普通用户", "vip_level": 0}}
)
print(result1["messages"][-1].content)
print("\n=== VIP用户 (VIP 3) ===")
result2 = vip_agent.invoke(
{"messages": [{"role": "user", "content": "广州的天气如何?"}]},
config={"configurable": {"user_name": "李总", "vip_level": 3}}
)
print(result2["messages"][-1].content)
打印
2.4 为Agent添加记忆
为了实现长短期期记忆,langgraph提供了很多组件,这里使用内存作为存储聊天
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver() # 内存节点
agent = create_react_agent(
model=f"openai:{modelName}",
tools=[get_weather],
checkpointer=checkpointer # 指定为内存节点 ,创建图的时候就要声明
)
# Run the agent
config = {"configurable": {"thread_id": "1"}} # thread_id 可以理解为本轮对话的id
agent.invoke(
{"messages": [{"role": "user", "content": "深圳的天气怎么样?"}]},
config
)
agent.invoke(
{"messages": [{"role": "user", "content": "我前面问题是什么?"}]},
config
)
输出
2.5 结构化输出
通常来说,模型的输出内容是固定,但是有时候我们想要输出指定的json,以便于我们处理
这里要强调一下,部分模型不支持结构化输出,就用不了下面的代码
你可以浏览一下官方声明常见模型的清单
https://python.langchain.com/docs/integrations/chat/
也可以到对应的厂商说明文档查看,比如我用的是豆包,可以看到不支持
https://console.volcengine.com/ark/region:ark+cn-beijing/model/detail?Id=doubao-1-5-pro-256k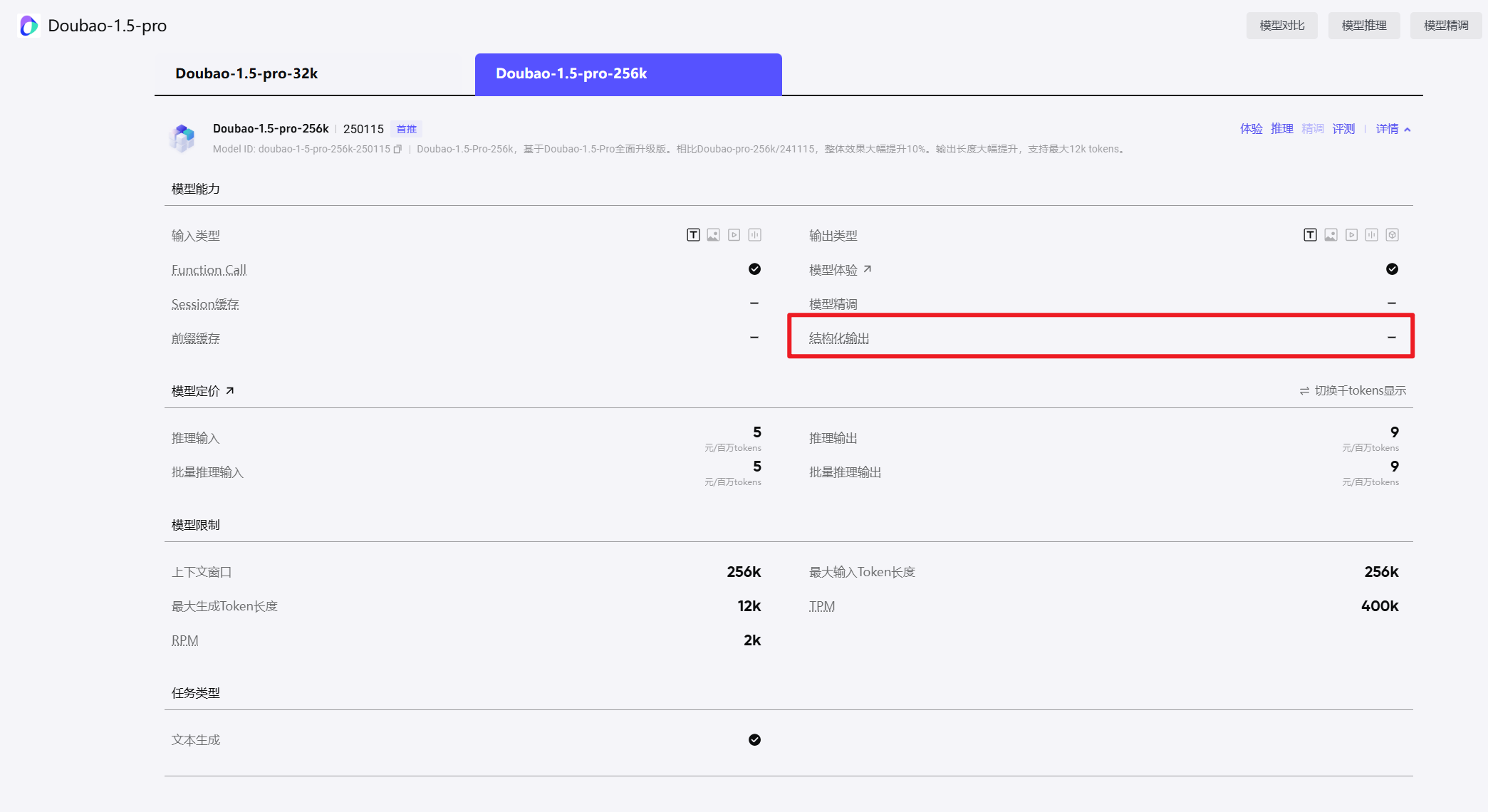
官方代码如下,是跑不通的
from pydantic import BaseModel
from langgraph.prebuilt import create_react_agent
class WeatherResponse(BaseModel):
conditions: str
agent = create_react_agent(
model=model, # 用的豆包的,这个代码会出错
tools=[get_weather],
response_format=WeatherResponse
)
response = agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)
response["structured_response"]

你可以这样做
实际上langchian_core 可以 作为链式调用时候,可以修正这个问题
from pydantic import BaseModel
import json
import re
class WeatherResponse(BaseModel):
conditions: str
def extract_structured_response(agent_response, target_model: BaseModel):
"""从agent回复中提取结构化数据"""
last_message = agent_response["messages"][-1].content
# 方法1: 尝试直接JSON解析
try:
json_match = re.search(r'\{.*\}', last_message, re.DOTALL)
if json_match:
json_data = json.loads(json_match.group())
return target_model(**json_data)
except:
pass
# 方法2: 基于关键词提取
if "conditions" in last_message.lower():
# 简单的文本解析逻辑
conditions = last_message.strip()
return target_model(conditions=conditions)
return None
# 使用普通的agent
agent = create_react_agent(
model=f"openai:{modelName}",
tools=[get_weather],
prompt="你是个乐于助人的助手。在提供天气信息时,请将您的最终回复格式化为 JSON with 'conditions' field."
)
response = agent.invoke(
{"messages": [{"role": "user", "content": "深圳今天天气如何?"}]}
)
# 后处理提取结构化数据
structured_response = extract_structured_response(response, WeatherResponse)
if structured_response:
print("结构化输出:", structured_response)
else:
print("提取失败,原始回复:", response["messages"][-1].content)
3、综合案例
我们将从一个 基本的聊天机器人 开始,并逐步添加更复杂的功能,在此过程中介绍关键的LangGraph概念。
- ✅ 通过搜索网络 来 回答常见问题
- ✅ 在调用之间保持对话状态
- ✅ 将复杂查询 转发给人工进行审核
- ✅ 使用自定义状态 来控制其行为
- ✅ 回溯并探索 替代对话路径
3.1 构建一个基础聊天Agent
你可以这么理解,State是点与点之间沟通的载体,现在就是定义状态机
graph_builder则是我们的白纸,准备在上面画画
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 创建图的时候,第一步就是定义状态机
class State(TypedDict):
# 消息的类型为 “list”。'add_messages' 函数
# 定义如何更新此状态键
# (在本例中,它将消息附加到列表中,而不是覆盖它们)就是每次人机聊天的请求响应都会在这个messages以add方式存储list
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
现在在这张白纸上面画一个点
from langchain.chat_models import init_chat_model
llm = init_chat_model(model=f"openai:{modelName}")
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
# 为这个图添加一个可用节点
# 第一个参数为节点的名称,第二个参数是将在每次调用时使用的函数或对象。
graph_builder.add_node("chatbot", chatbot)
接下来指定开始节点为chatbot,并且chatbot执行完成后,直接到结束,workflow的绘制,跟coze跟dify概念相似
graph_builder.add_edge(START, "chatbot") # 等同于graph_builder.set_entry_point("chatbot")
graph_builder.add_edge("chatbot", END)
编译图使其实例化对象,并且查看我们刚构建的workflow
graph = graph_builder.compile()
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png())) # 可能会超时,需要开启代理
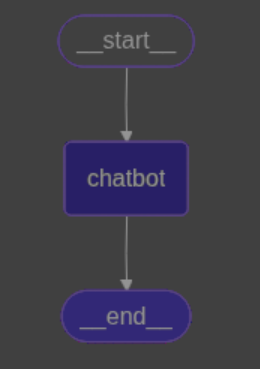
现在我们来运行一下
for event in graph.stream({"messages": [{"role": "user", "content": "你是谁"}]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
输出
Assistant: 我是豆包呀,能陪你畅快聊天,解答各种知识疑问,无论是生活琐事、科学难题还是文学艺术相关,都能和你探讨~
3.2 为Agent绑定工具
现在Agent没有使用任何,工具,我们为其创建一个工具
- 学习内置工具,跟自定义创建工具
- 学习内置条件路由,跟自定义条件路由
- PS:很重要的一点,模型需要绑定工具,图也需要绑定工具
from langchain_core.tools import tool
########### 定义工具
@tool
def get_personal_info(name: str) -> dict:
"""
通过名称获取个人信息
:param name:
:return:
"""
personal_info = {
"love": "打篮球",
"age": "18"
}
return personal_info
######### 创建图
from langchain.chat_models import init_chat_model
llm = init_chat_model(model=f"openai:{modelName}")
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 定义状态机
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
# 为模型创建工具
llm_with_tools = llm.bind_tools([get_personal_info])
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
这里使用@tool来讲一个函数作为工具,bind_tools为模型进行绑定工具
现在这张画布上面,仅有chabot节点,我们需要在画布上添加一个工具节点
3.2.1 自定义图工具与路由
在这段代码,我们自定义了一个BasicToolNode,作为工具执行节点
import copy
graph_builder_1 = copy.deepcopy(graph_builder)
import json
from langchain_core.messages import ToolMessage
class BasicToolNode:
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, sate: State):
if messages := sate.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
tool_node = BasicToolNode(tools=[get_personal_info])
graph_builder_1.add_node("tools", tool_node)
下面再自定义一个路由工具节点
def route_tools(
state: State,
):
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return END
# 创建条件路由
graph_builder_1.add_conditional_edges(
"chatbot",
route_tools,
{"tools": "tools", END: END},
)
graph_builder_1.add_edge("tools", "chatbot")
graph_builder_1.add_edge(START, "chatbot")
graph_1 = graph_builder_1.compile()
我们绘图看看现在的情况,可以看到chatbot与tools有循环条件边
用户问题->由chatbot先执行,然后交给route_tools 判断状态机State中的消息载体,是否有生成工具调用
- 有的话返回
tools这个字符串,代表要去工具节点 - 没有则返回
END结束回复 add_conditional_edges中第三个参数{"tools": "tools", END: END},作为路由,根据返回内容跳转到指定节点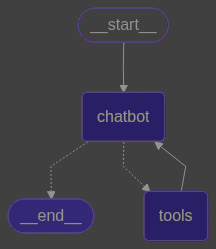
打开你的jupyter,进行debug,参考我的gif,打上3处debug,然后继续看我下文
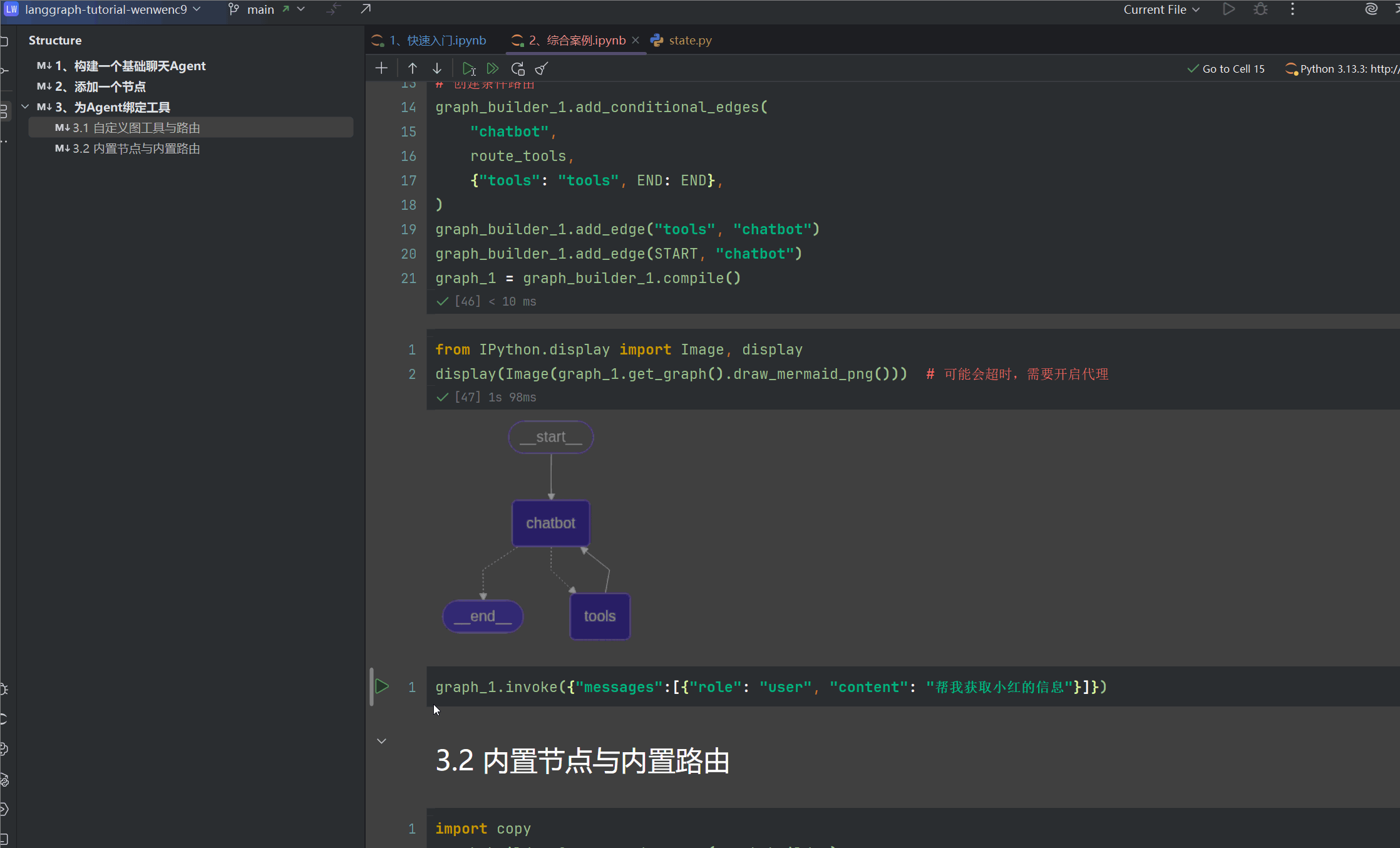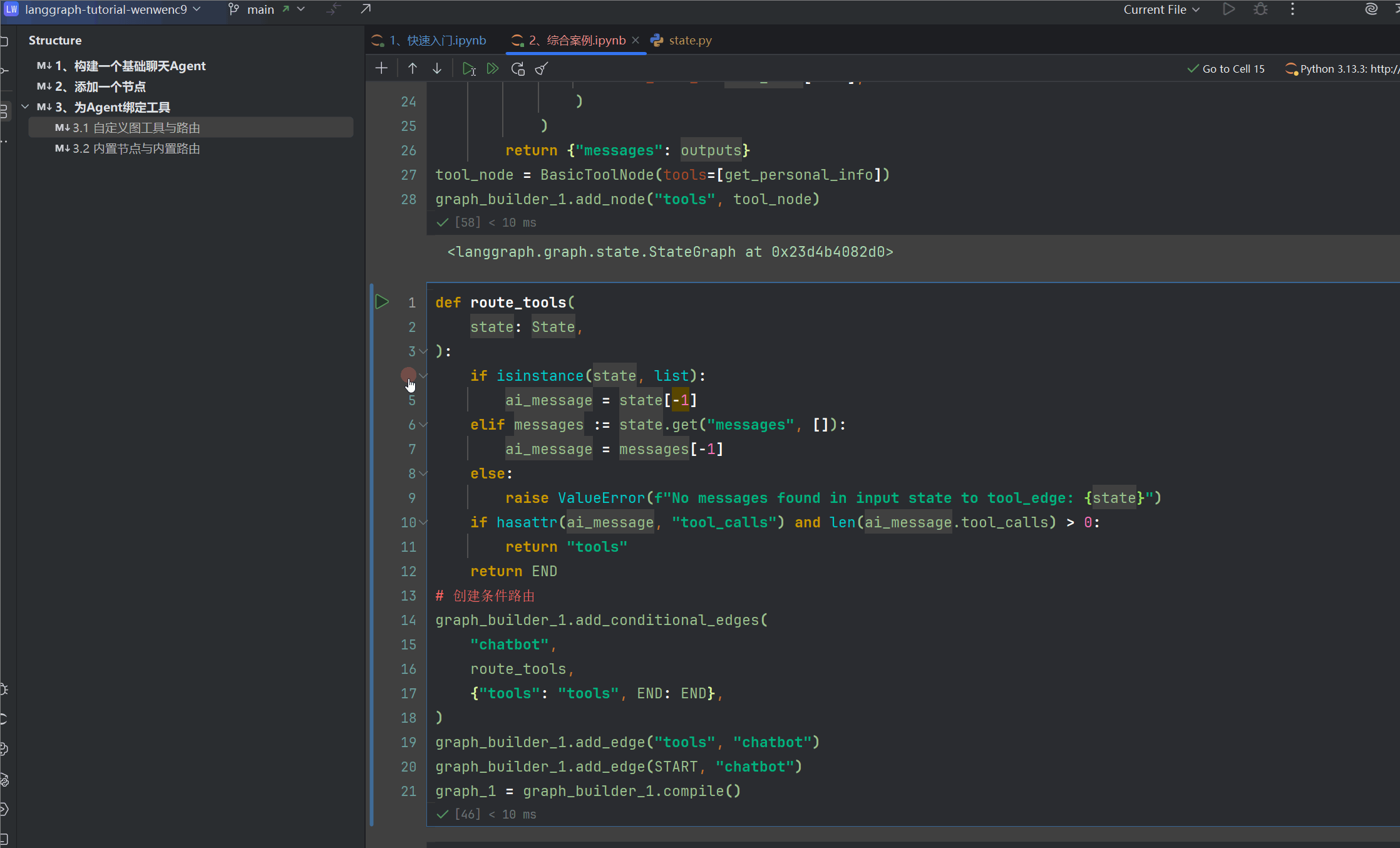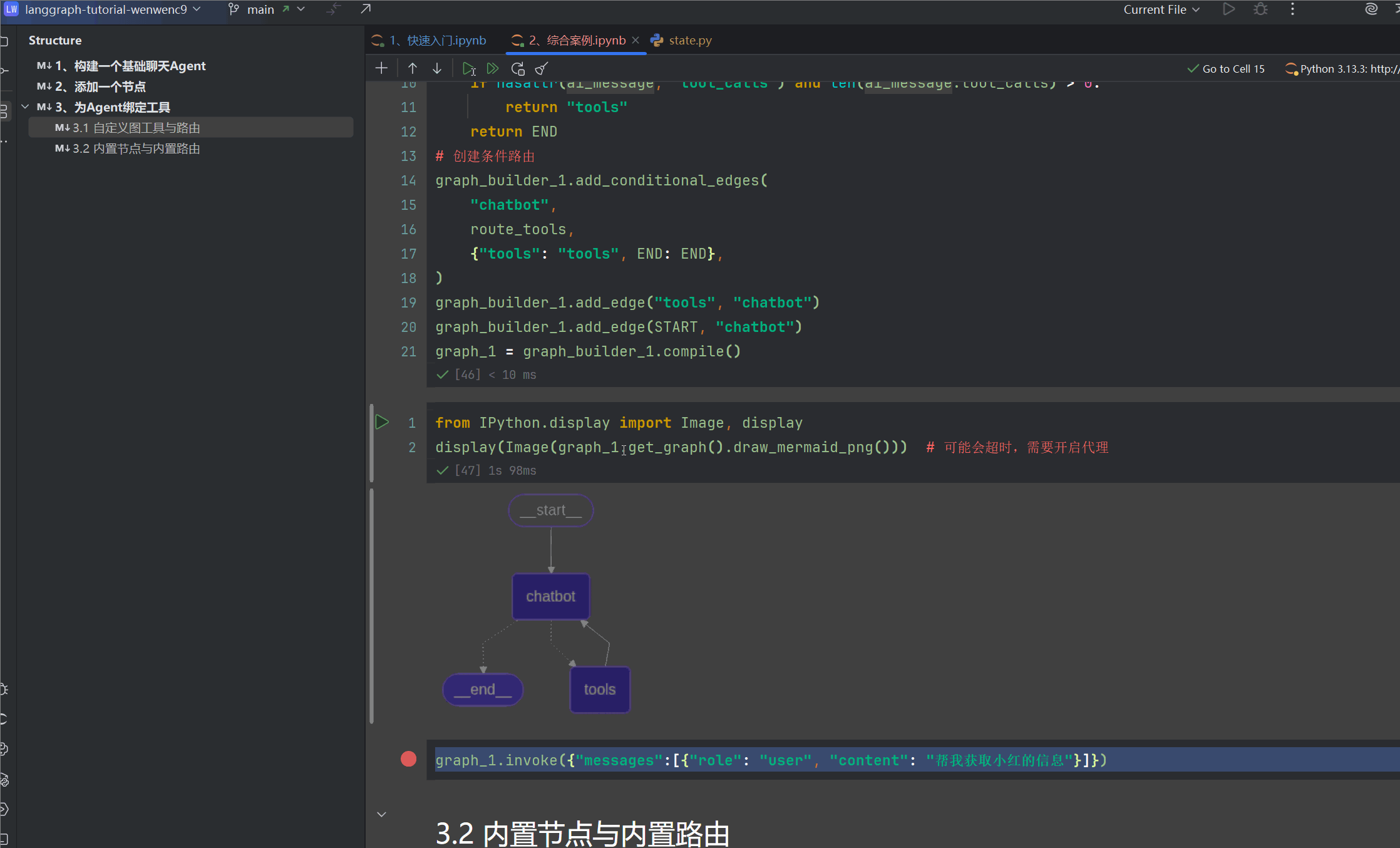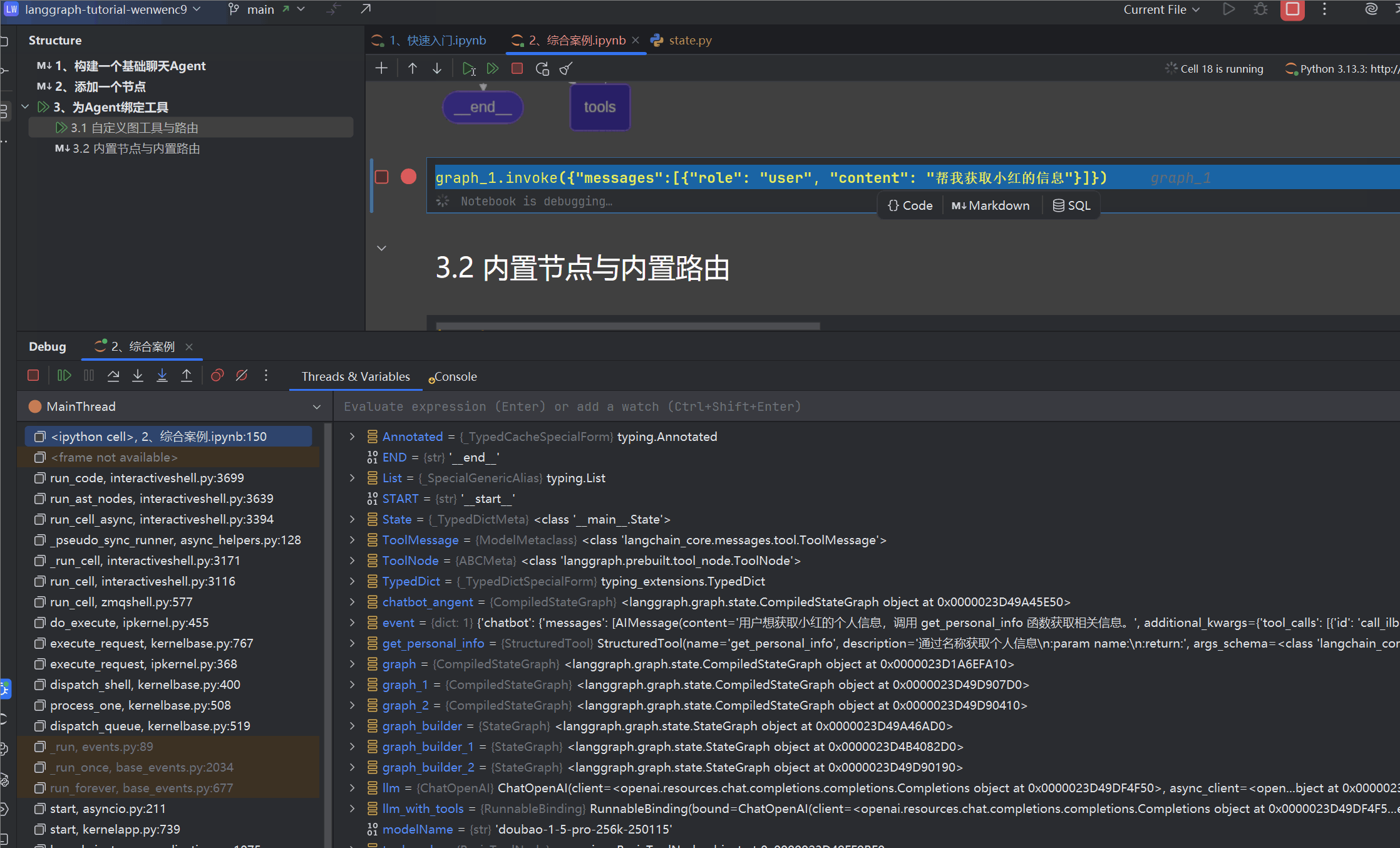
我们可以切实体验一下从用户问题发起到结束,第一个进入断点,调试堆栈
我们发现是进入到了路由工具 route_tools,进入的时候,堆栈State为状态机其中有消息载体,一个是咱们输入的,一个是chatbot回复的,可以ai回复的内容有个tool_calls,并且content声明了需要调用何种工具
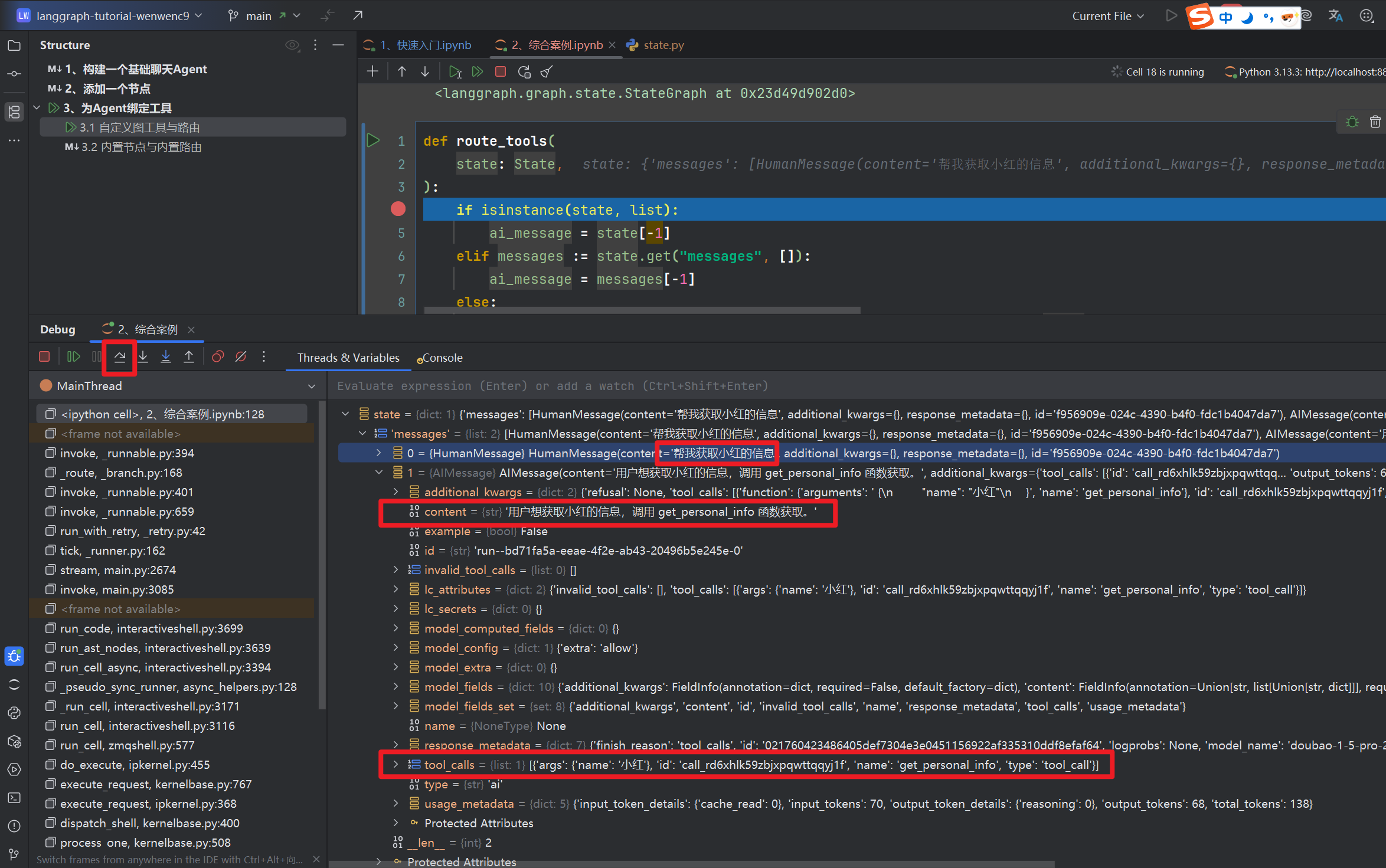
现在进入我们的第二个断点,直接F9,进入到BasicToolNode,这个时候我们来理解代码,前面chatbot生成要调用工具,路由工具指向了我们定义的工具节点BasicToolNode,通过状态机State来获取工具需要执行的参数传参tool_call["args"],使用invoke运行工具,最后返回ToolMessages,retrun的时候更新状态State中的messages,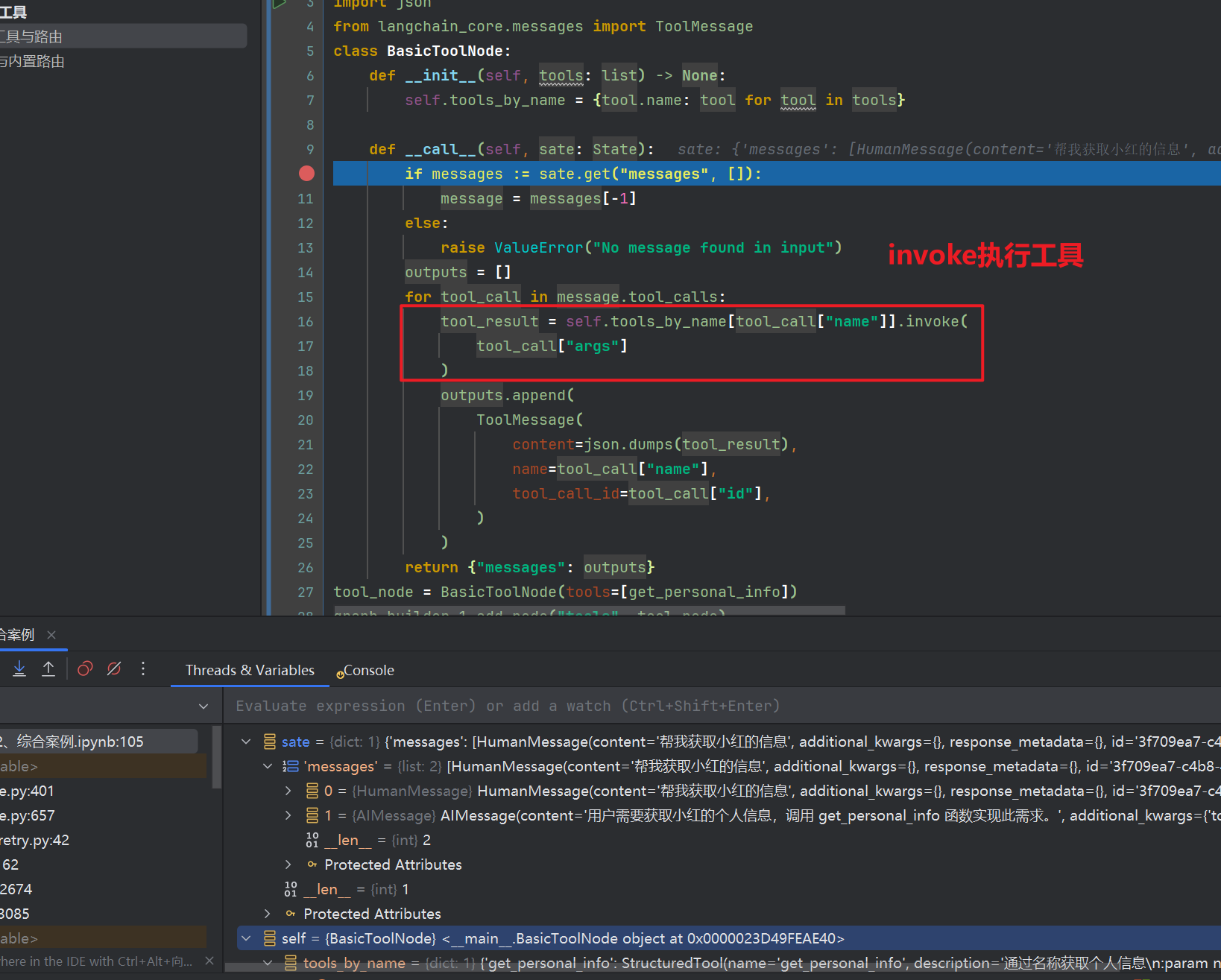
在按F9,又回到了路由工具route_tools,此时我们来看看堆栈(其实可以在chatbot多加一个断点,方便最后一条载体理解)
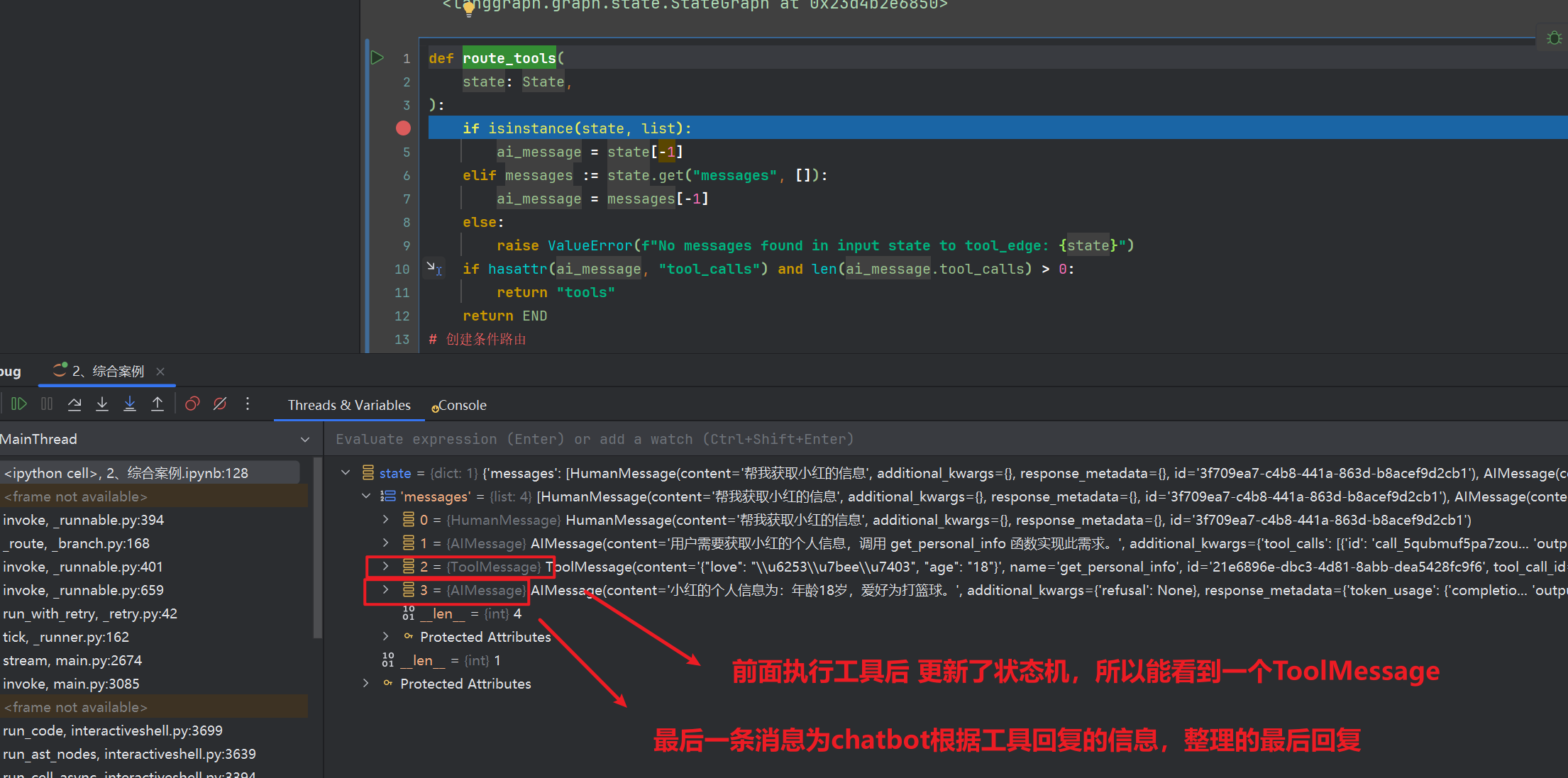
3.2.2 内置节点与内置路由
langgraph官方提供了很多优秀的封装方法from langgraph.prebuilt import ToolNode方便我们快速操作,你可以查看这个链接
https://langchain-ai.github.io/langgraph/agents/overview/?h=prebuilt#package-ecosystem
使用内置方法为图创建工具节点
import copy
graph_builder_2 = copy.deepcopy(graph_builder)
from langgraph.prebuilt import ToolNode
tools = ToolNode([get_personal_info])
graph_builder_2.add_node("tools", tools)
使用内置路由方法
from langgraph.prebuilt import tools_condition
# 创建条件路由
graph_builder2.add_conditional_edges(
"chatbot",
tools_condition,
{"tools": "tools", END: END},
)
graph_builder2.add_edge(START, "chatbot")
graph_builder2.add_edge("tools", "chatbot")
graph_2 = graph_builder2.compile()
3.2.3 两者区别
内置方法固然好,但适合简单操作,高度复杂自定义的话建议还是自定义,比如我们可以在自定义方法中添加日志系统
加上更多个性化化操作等等,send_writher流式回复的时候,发送我正在思考.....,该系列后面会讲到
3.3 添加记忆
先创建一个基础聊天机器人
from typing import Annotated
from langchain.chat_models import init_chat_model
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
llm = init_chat_model(model=f"openai:{modelName}")
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
使用checkpointer短期记忆作为Agent的记忆,并且使用内存记忆,当然也可以使用数据库,记忆分为
- 长期记忆:跨线程,比如用户画像
- 短期记忆:该线程会话上才文,新建聊天窗口
现在我们可以使用内存操作,执行需要在编译的时候compile(checkpointer=memory) 指定一下即可
pretty_print是内置的方法,当为消息载体的时候可以美化打印stream为流式回复的方法,invoke为同步回复的方法- 我们可以发现进行stream的时候传入了一个config,
{"configurable": {"thread_id": "1"}}这个就是线程,用于记住该窗口上下文
#### 添加内存操作
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
graph_by_in = graph_builder.compile(checkpointer=memory)
# 第一次发起询问
config = {"configurable": {"thread_id": "1"}}
events = graph_by_in.stream(
{"messages": [{"role": "user", "content": "你好!我的名字叫稳稳"}]},
config,
stream_mode="values",
)
for event in events:
event["messages"][-1].pretty_print()
# 第二次发起询问
events = graph_by_in.stream(
{"messages": [{"role": "user", "content": "你还记得我的名字吗?"}]},
config,
stream_mode="values",
)
for event in events:
event["messages"][-1].pretty_print()
我们看看效果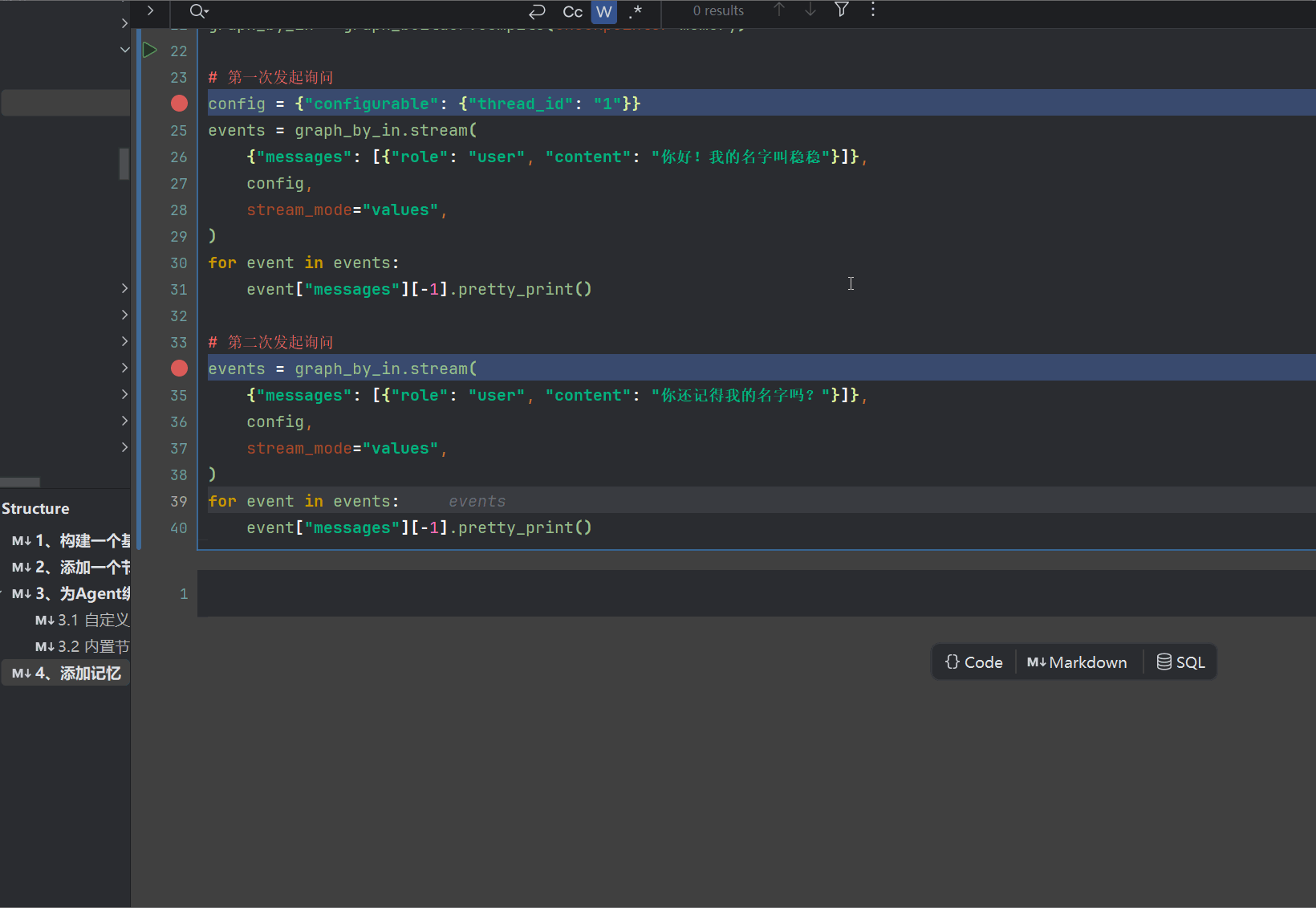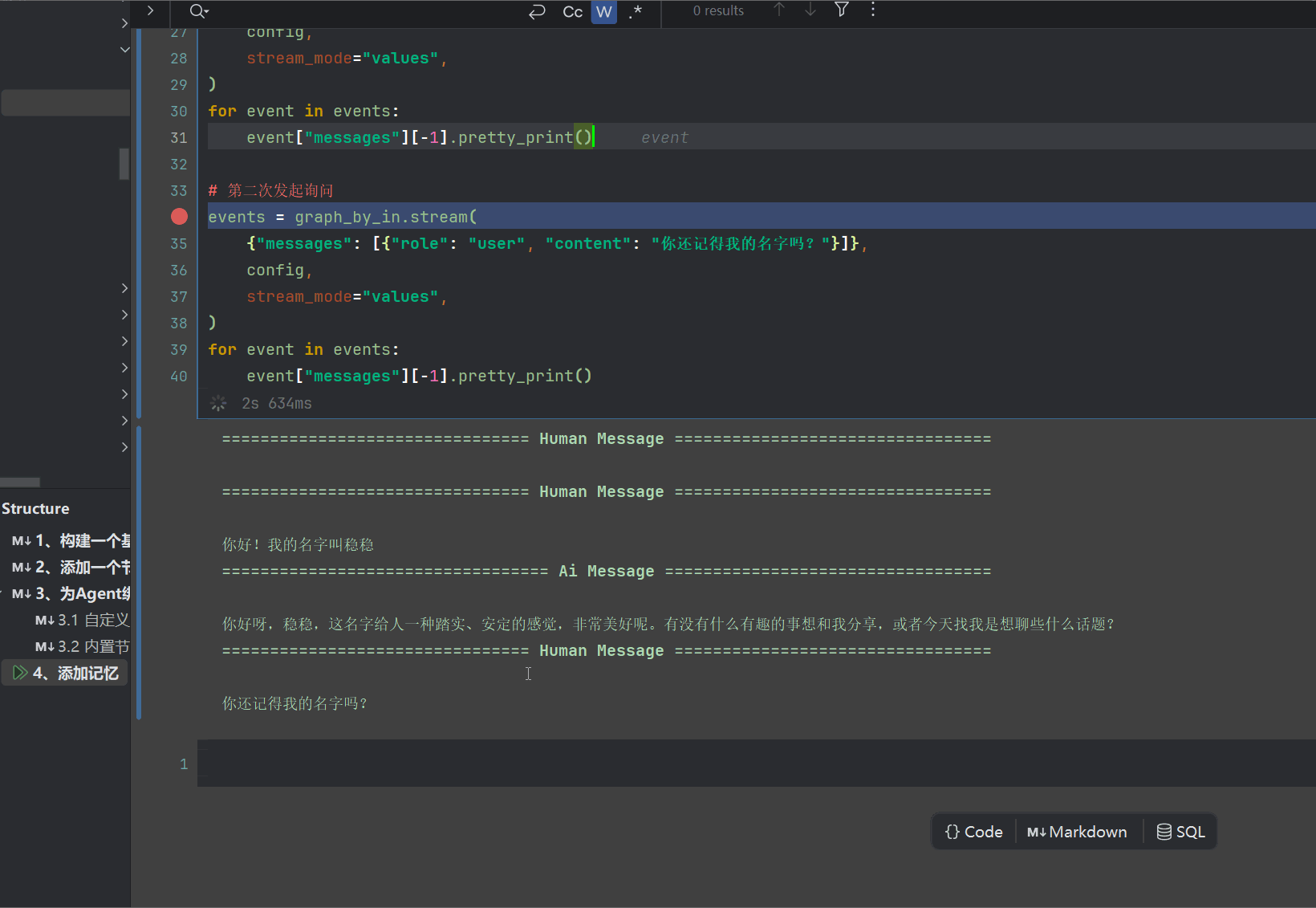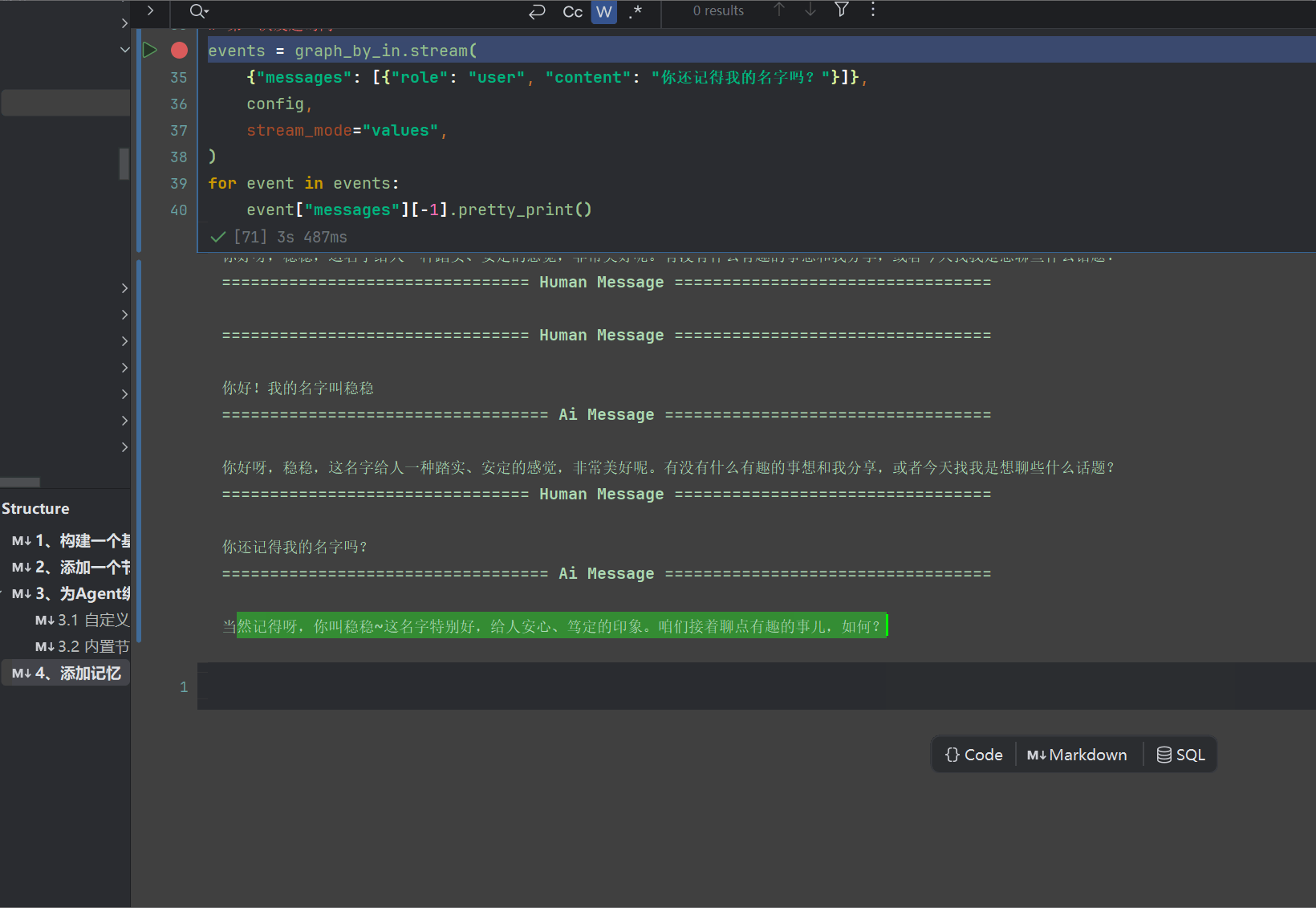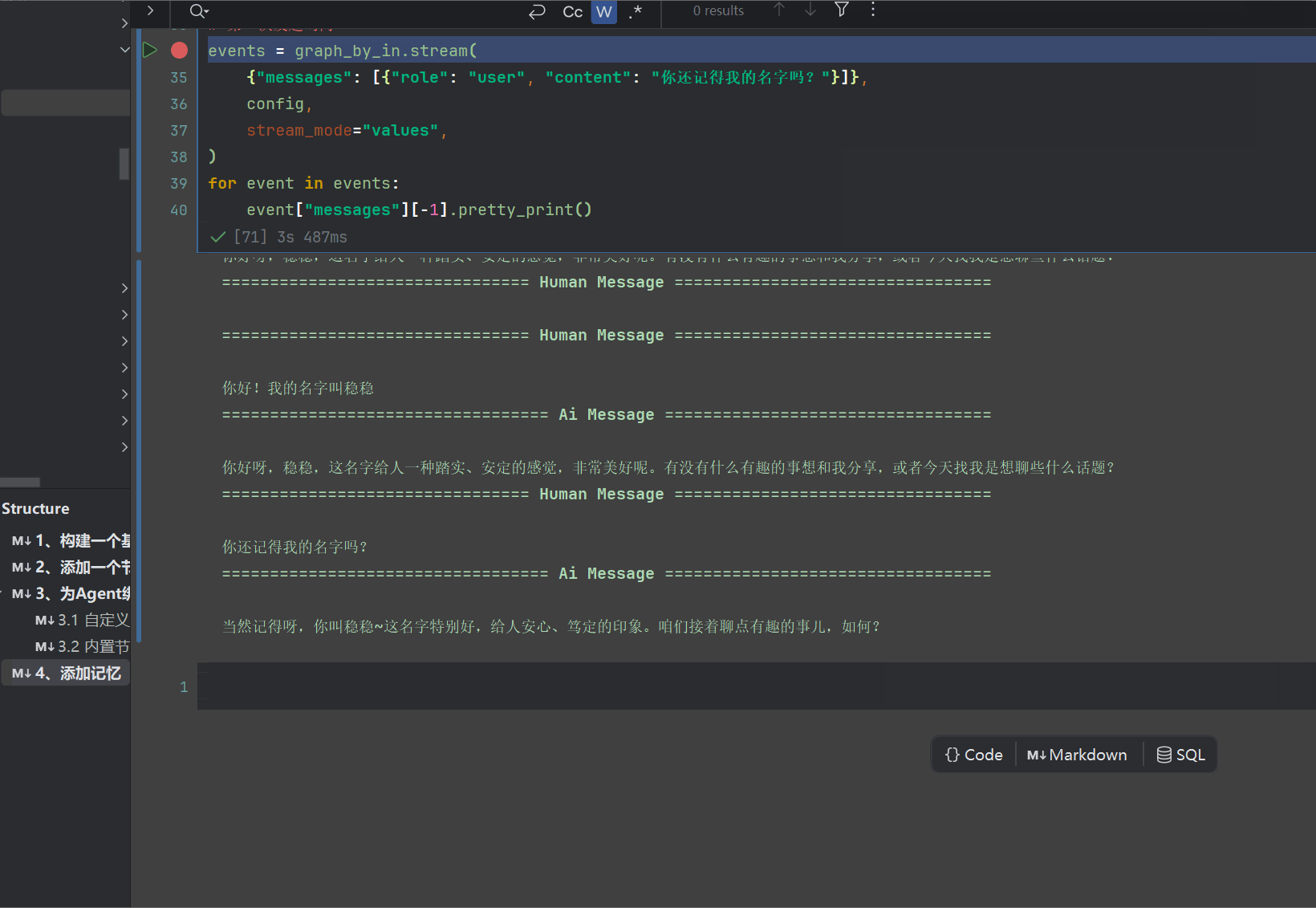
3.4 添加人机交互
代理可能不可靠,在某些情况下需要人工输入才能成功完成任务。
对于一些关键操作,可能希望在执行前获得人工批准以确保一切按预期运行,比如付款。
- interrupt函数:在节点内暂停执行的关键函数
- Command对象:用于恢复执行并传递人工输入的命令
- 持久化状态:使用检查点支持无限期暂停和恢复
- 人工监督:在关键决策点引入人工审查和控制
人工介入的设计模式:
- 批准或拒绝:在关键步骤前暂停以审查和批准操作
- 编辑图状态:暂停以审查和编辑图状态,纠正错误或添加信息
- 审查工具调用:在工具执行前审查和编辑LLM请求的工具调用
- 验证人工输入:在进行下一步之前验证人工输入
创建一个酒店机器人,当用户发起“酒店订阅”,进行人工交互,让用户输入信息后,从当前节点继续运行
interrupt在节点中,其本质就是抛出异常,中断command具有跳转节点的作用
from langchain_core.tools import tool
from typing_extensions import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
# ps 非常重要的点,导入这2个参数
from langgraph.types import interrupt, Command
from langchain.chat_models import init_chat_model
llm = init_chat_model(model=f"openai:{modelName}")
@tool("用户订阅酒店工具")
def book_hotel(*args,query: str,**kwargs) -> str:
"""
用于处理酒店预订相关的请求。
"""
print("*"*10,"进入")
human_response = interrupt({"message": "好的请你填写酒店表单信息", "form_data": {"name": "", "age": ""}})
print("*"*10,"离开")
if human_response:
return f"尊敬的{human_response['form_data']['name']},已经为您订阅酒店!"
else:
return "用户取消了预订"
tools = [book_hotel]
llm = llm.bind_tools(tools)
tools_node = ToolNode(tools) # 适用于图的节点
### 创建图
class State(TypedDict):
messages: Annotated[list, add_messages]
def chatbot(state: State):
# 添加系统提示
system_prompt = """你是一个智能助手。你有以下工具可用:
工具使用规则:
1. "用户订阅酒店工具" - 仅在用户明确想要预订酒店、查询酒店或讨论住宿相关问题时使用
2. 对于一般性问题(如科学知识、天气、计算等),请直接回答,不要调用工具
3. 如果用户的问题与可用工具无关,请礼貌地直接回答
请仔细判断是否需要使用工具。"""
messages = [{"role": "system", "content": system_prompt}] + state["messages"]
message = llm.invoke(messages)
return {"messages": [message]}
graph_builder = StateGraph(State)
graph_builder.set_entry_point("chatbot")
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_node("tools", tools_node)
graph_builder.add_conditional_edges("chatbot", tools_condition)
graph_builder.add_edge("tools", "chatbot")
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
graph_by_in = graph_builder.compile(checkpointer=memory)
from IPython.display import Image, display
display(Image(graph_by_in.get_graph().draw_mermaid_png())) # 可能会超时,需要开启代理
让我们询问非酒店订阅的功能
user_input = "太阳的体积"
config = {"configurable": {"thread_id": "1"}}
# 使用stream模式以便检测中断
events = graph_by_in.stream(
{"messages": [{"role": "user", "content": user_input}]},
config,
stream_mode="values"
)
# 遍历事件
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
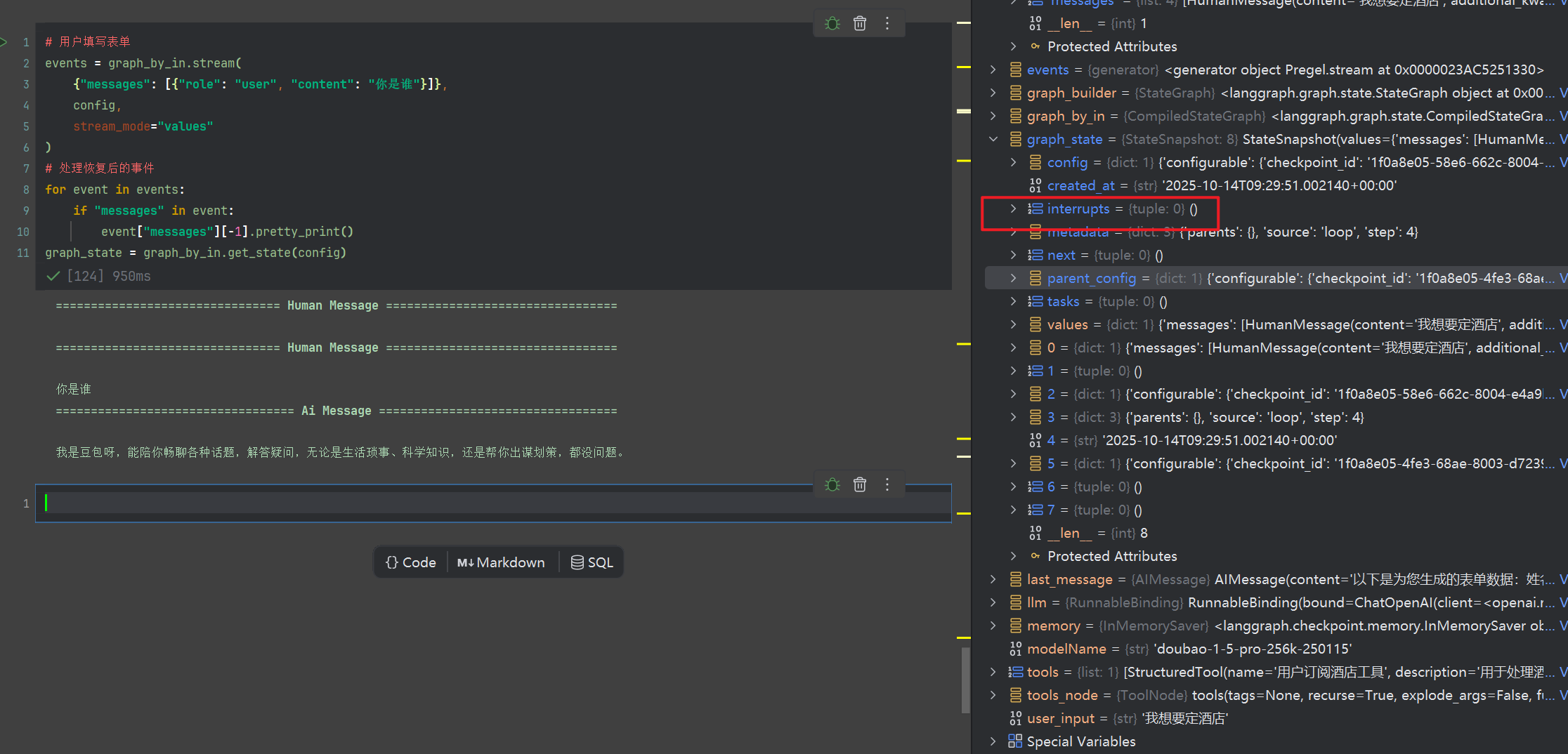
graph_state = graph_by_in.get_state(config)
输出如下graph_by_in.get_state(config) 可以获取图的运行状态,我们可以看到其中有个interrupts为空,并且并没有中断

3.4.1 触发中断
现在,让我们询问酒店相关的问题,出现了中断
3.4.2 恢复中断
假定,我们有前端,完全可以使用该功能,AI识别用户需求,弹出表单,然后用户填写表单后提交,恢复继续流程,这里我们继续模拟
用户填写表单信息
# 用户填写表单
events = graph_by_in.stream(
Command(resume={"form_data": {"name": "稳稳C9", "age": "18"}}), # 传入用户填写的表单数据
config,
stream_mode="values"
)
# 处理恢复后的事件
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
graph_state = graph_by_in.get_state(config)
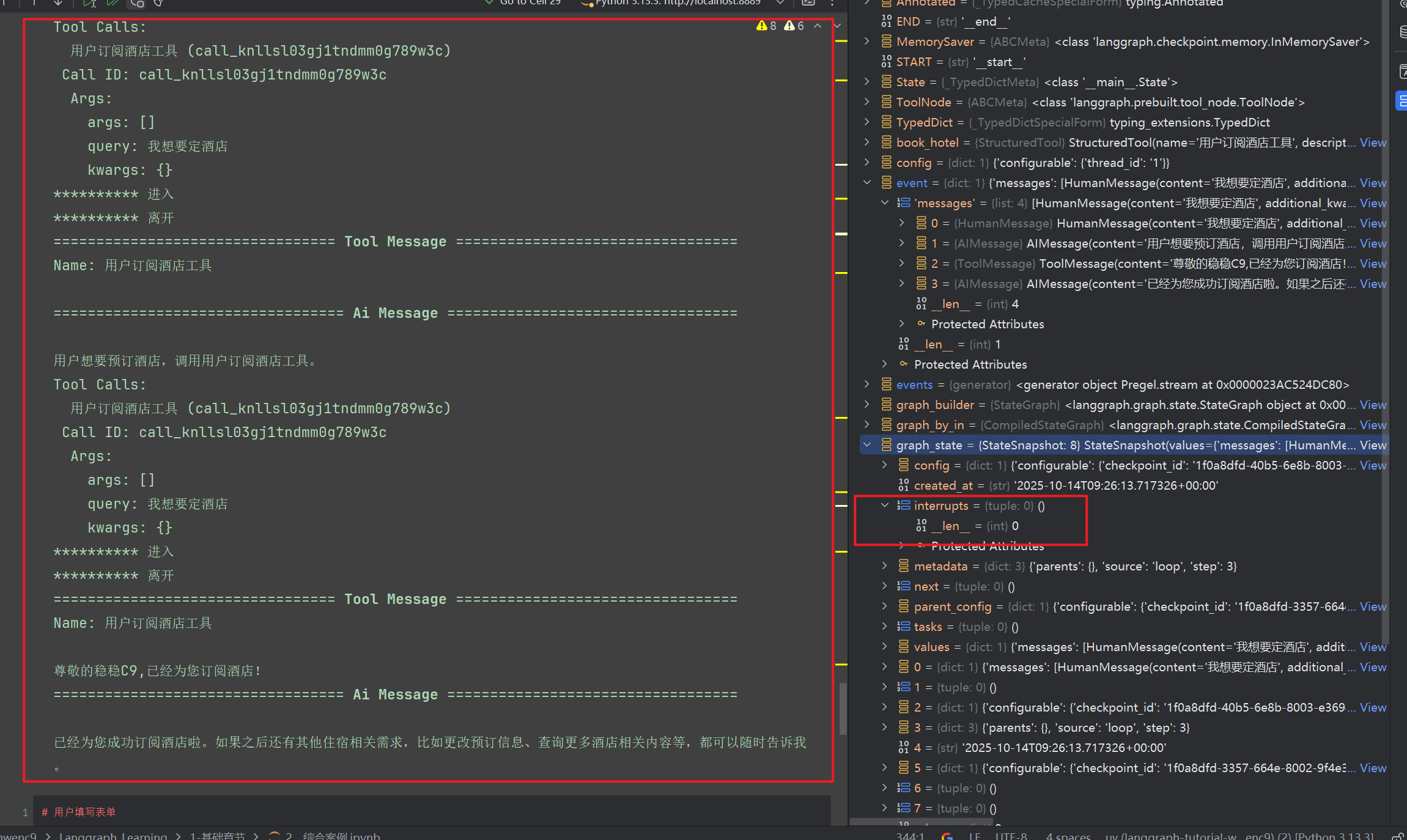
3.4.1 中断抹除
运行这个代码的时候,请重新运行图编译,然后触发酒店中断,然后再执行下面代码
# 用户填写表单
events = graph_by_in.stream(
{"messages": [{"role": "user", "content": "你是谁"}]},
config,
stream_mode="values"
)
# 处理恢复后的事件
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
graph_state = graph_by_in.get_state(config)
注意,如果下一轮对话,没有使用command,恢复中断,此时图状态的interrupt会抹除
3.5 自定义状态机
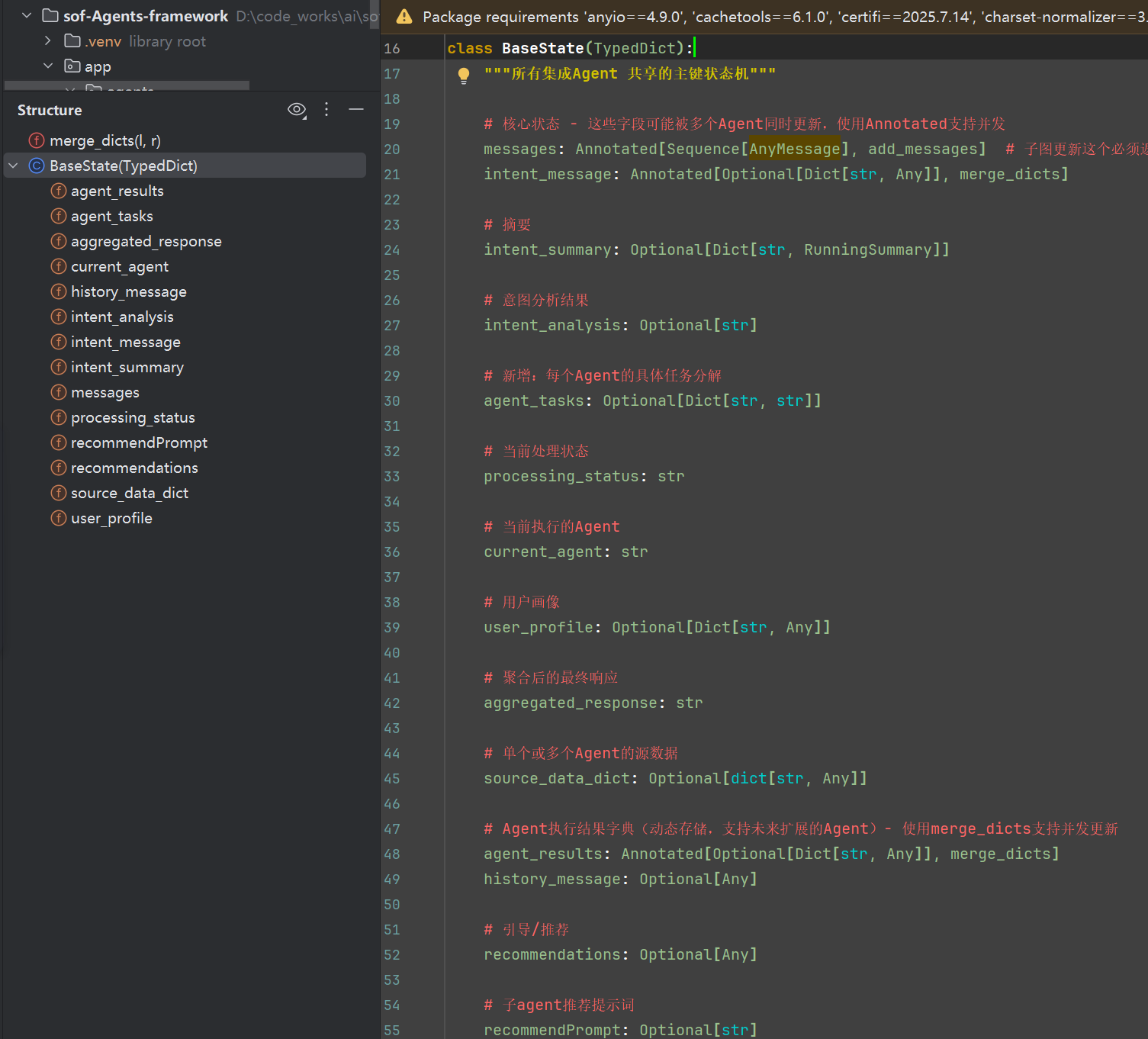
在前面的代码中,我们的状态机State仅有一个messages
# 创建图的时候,第一步就是定义状态机
class State(TypedDict):
# 消息的类型为 “list”。'add_messages' 函数
# 定义如何更新此状态键
# (在本例中,它将消息附加到列表中,而不是覆盖它们)就是每次人机聊天的请求响应都会在这个messages以add方式存储list
messages: Annotated[list, add_messages]
状态机,为信息载体的主体对象,我们上面小节都是只有一个messages,实际上我们可以新增很多字段,系列最后企业级项目会以复杂的内容作为展现,现在我们开始了解掌握自定义状态机
现在我们构建一个案例:
在企业财务管理中,资金拨款需要严格的审批流程。本案例模拟一个智能财务审批系统,当用户申请拨款时,系统会暂停执行等待人工审批,确保资金安全。
- 如何在 LangGraph 中实现财务审批机制
- 理解 interrupt() 和 Command 的使用方法
- 掌握状态管理和工具调用的最佳实践
- 学会处理财务敏感操作的安全控制
整体流程:
用户申请 → 系统评估 → 暂停等待审批 → 人工审核/拒绝 → 执行拨款/拒绝
3.5.1 第一步创建自定义状态机
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
from typing import Annotated, Optional
class State(TypedDict):
messages: Annotated[list, add_messages] # 对话消息列表
applicant_name: Optional[str] # 申请人姓名
amount: Optional[float] # 申请金额
purpose: Optional[str] # 申请用途
approval_status: Optional[str] # 审批状态:pending/approved/rejected
approver_name: Optional[str]
包含核心的财务申请信息字段
approval_status 跟踪审批状态
简化的状态结构便于理解
3.5.2 第二步创建,评估财务拨款申请的合理性,工具
from langchain_core.tools import tool
@tool
def evaluate_funding_request(applicant_name: str,amount: float,purpose: str) -> str:
"""
评估财务拨款申请的合理性
Args:
applicant_name: 申请人姓名
amount: 申请金额
purpose: 申请用途
Returns:
评估结果
"""
# 简单的风险评估
if amount > 100000:
risk_level = "高风险"
suggestion = "需要详细说明资金用途"
elif amount > 50000:
risk_level = "中风险"
suggestion = "建议提供项目计划"
else:
risk_level = "低风险"
suggestion = "申请材料完整"
evaluation = f"""
📋 申请评估报告
申请人: {applicant_name}
申请金额: ¥{amount:,.2f}
申请用途: {purpose}
🔍 风险评估: {risk_level}
💡 建议: {suggestion}
"""
return evaluation
实现简单的业务规则
提供结构化的评估报告
根据金额进行风险分级
3.5.3 第三步,创建审批工具
关键概念解释:
interrupt()函数- 作用:暂停图执行,等待人工输入
- 参数:结构化的审批数据
- 返回值:人工提供的审批决策
Command(update=...)- 作用:在工具中直接更新图状态
- 包含:ToolMessage 记录审批结果
from langchain_core.tools import InjectedToolCallId
from langgraph.types import interrupt, Command
from langchain_core.messages import ToolMessage
@tool
def financial_approval(applicant_name: str,amount: float,purpose: str,tool_call_id: Annotated[str, InjectedToolCallId]) -> str:
"""
财务拨款审批工具
Args:
applicant_name: 申请人姓名
amount: 申请金额,纯数字
purpose: 申请用途
tool_call_id: 工具调用ID(自动注入)
Returns:
审批结果
"""
# 暂停执行,等待人工审批
human_response = interrupt({
"type": "financial_approval",
"message": "财务拨款申请需要审批",
"data": {
"applicant_name": applicant_name,
"amount": amount,
"purpose": purpose
},
"options": ["批准申请", "拒绝申请"]
})
# 处理审批结果
action = human_response.get("action", "拒绝申请")
approver_name = human_response.get("approver_name", "未知审批人")
comment = human_response.get("comment", "")
if action == "批准申请":
status = "approved"
response = f"✅ 申请已批准\n审批人: {approver_name}\n批准金额: ¥{amount:,.2f}\n审批意见: {comment}"
else:
status = "rejected"
response = f"❌ 申请已拒绝\n审批人: {approver_name}\n拒绝原因: {comment}"
# 更新状态
state_update = {
"approval_status": status,
"approver_name": approver_name,
"messages": [ToolMessage(response, tool_call_id=tool_call_id)],
}
return Command(update=state_update)
3.5.4 创建工作流
from langchain.chat_models import init_chat_model
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
# 初始化模型
llm = init_chat_model(f"openai:{modelName}")
# 绑定工具
tools = [evaluate_funding_request, financial_approval]
llm_with_tools = llm.bind_tools(tools)
# 定义聊天节点
def chatbot(state: State):
"""智能财务助手节点"""
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 构建图
tool_node = ToolNode(tools=tools)
graph_builder = StateGraph(State)
# 添加节点和边
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_node("tools", tool_node)
graph_builder.add_conditional_edges("chatbot", tools_condition)
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge(START, "chatbot")
# 编译图
graph = graph_builder.compile(checkpointer=MemorySaver())
3.5.5 运行图
config = {"configurable": {"thread_id": "rejection_demo_3"}}
user_request = "我是稳稳,申请拨款10万元用于购买豪华办公家具"
events = graph.stream(
{"messages": [{"role": "user", "content": user_request}]},
config,
stream_mode="values"
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
输出如下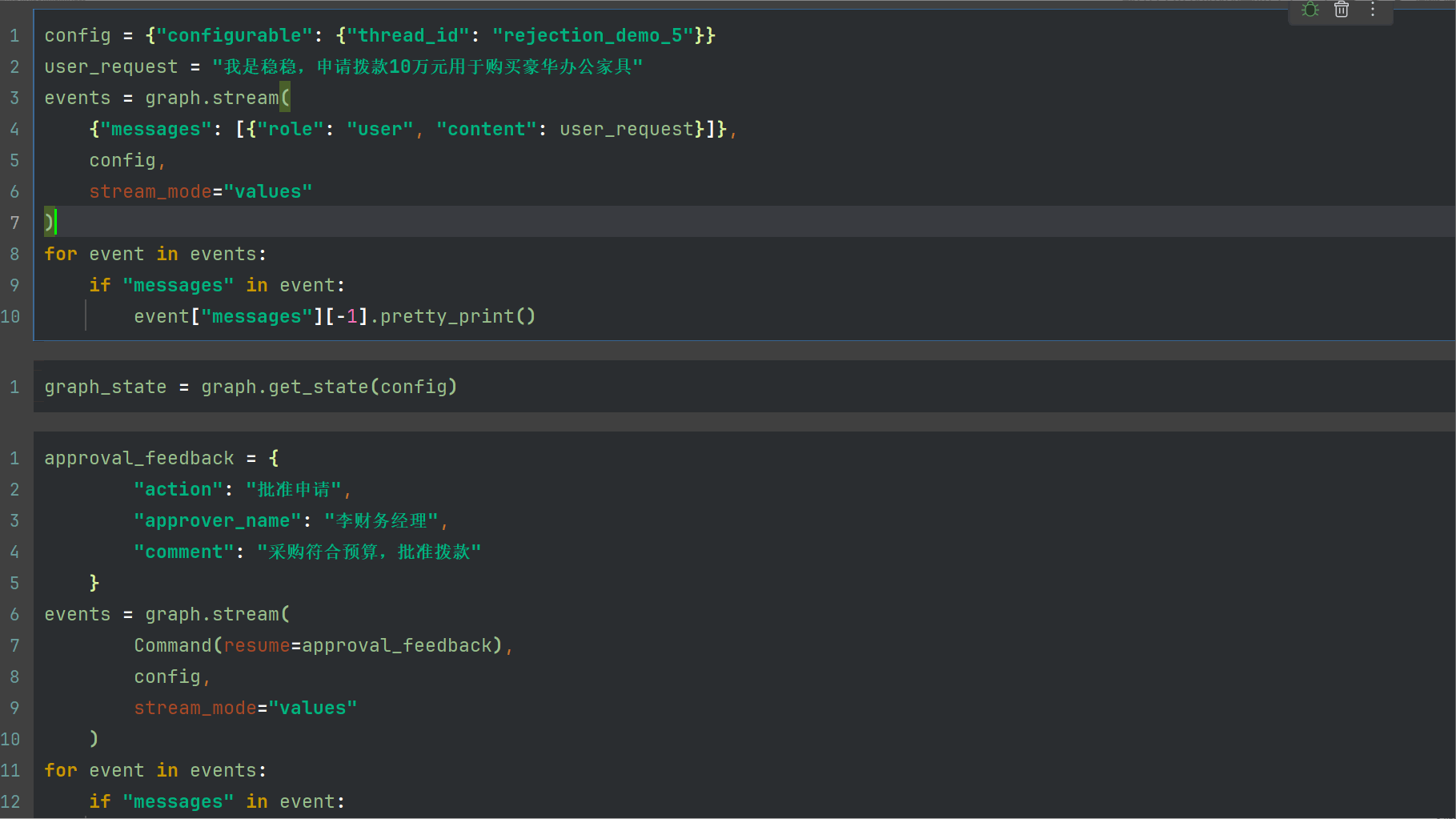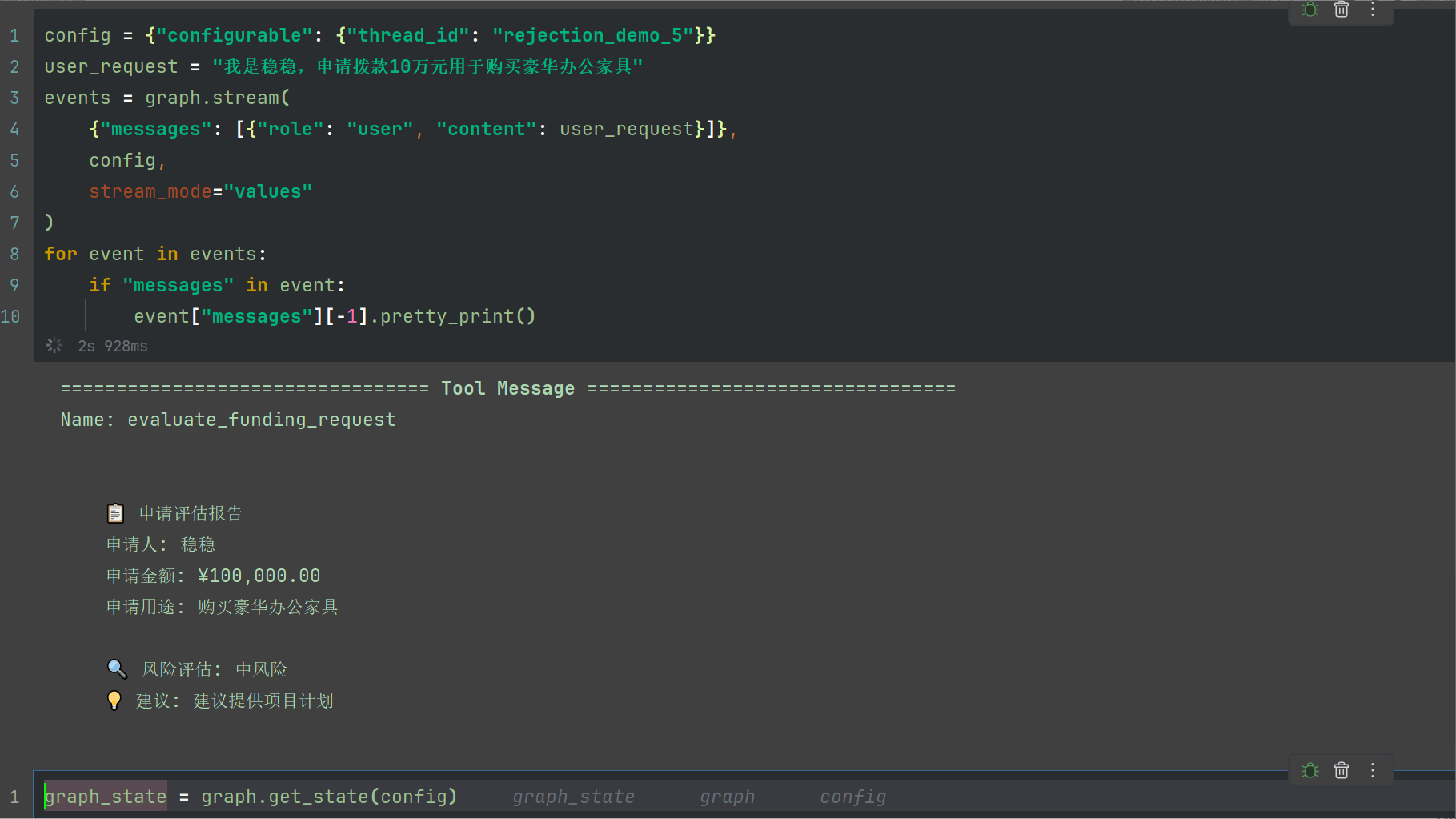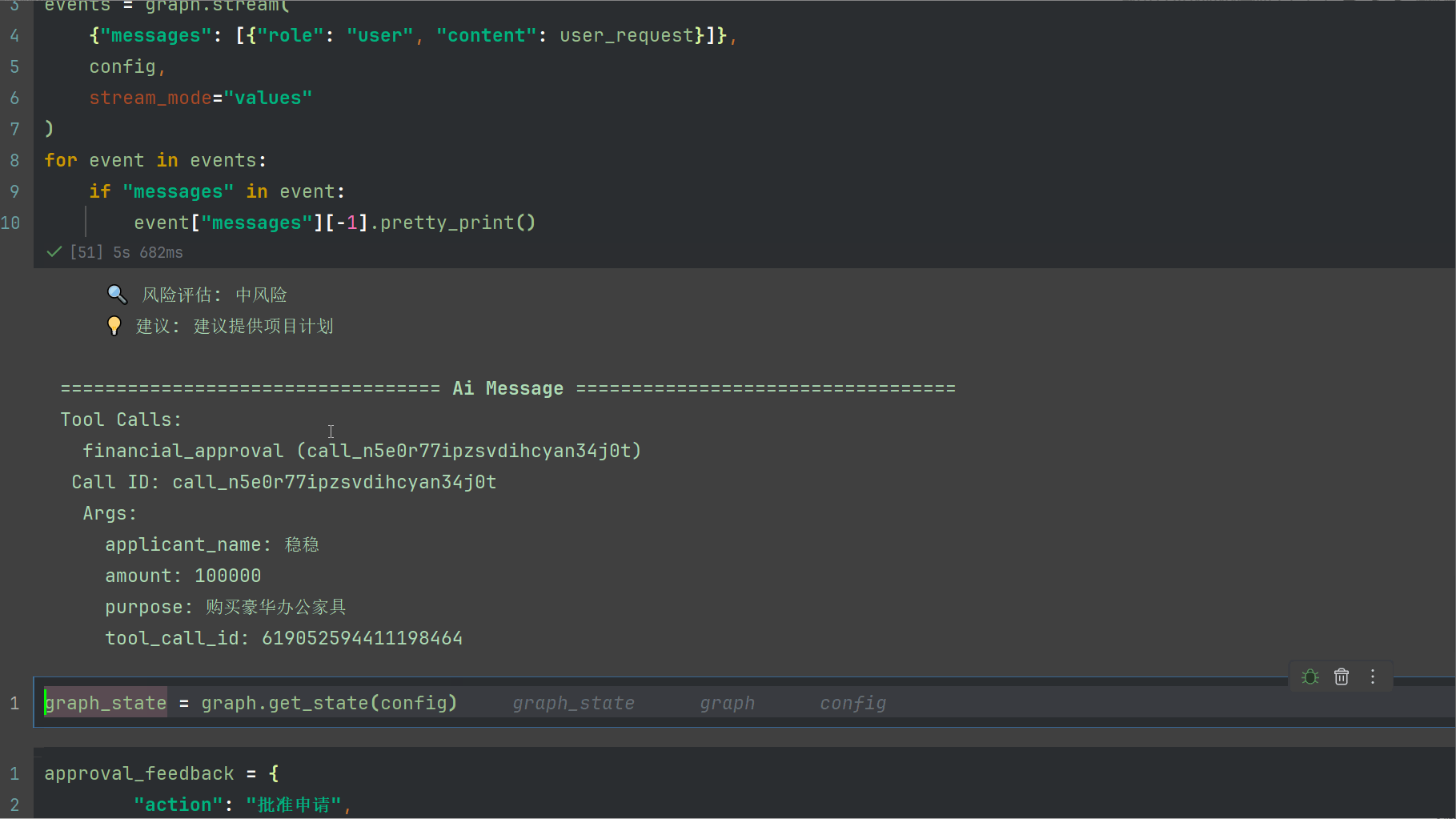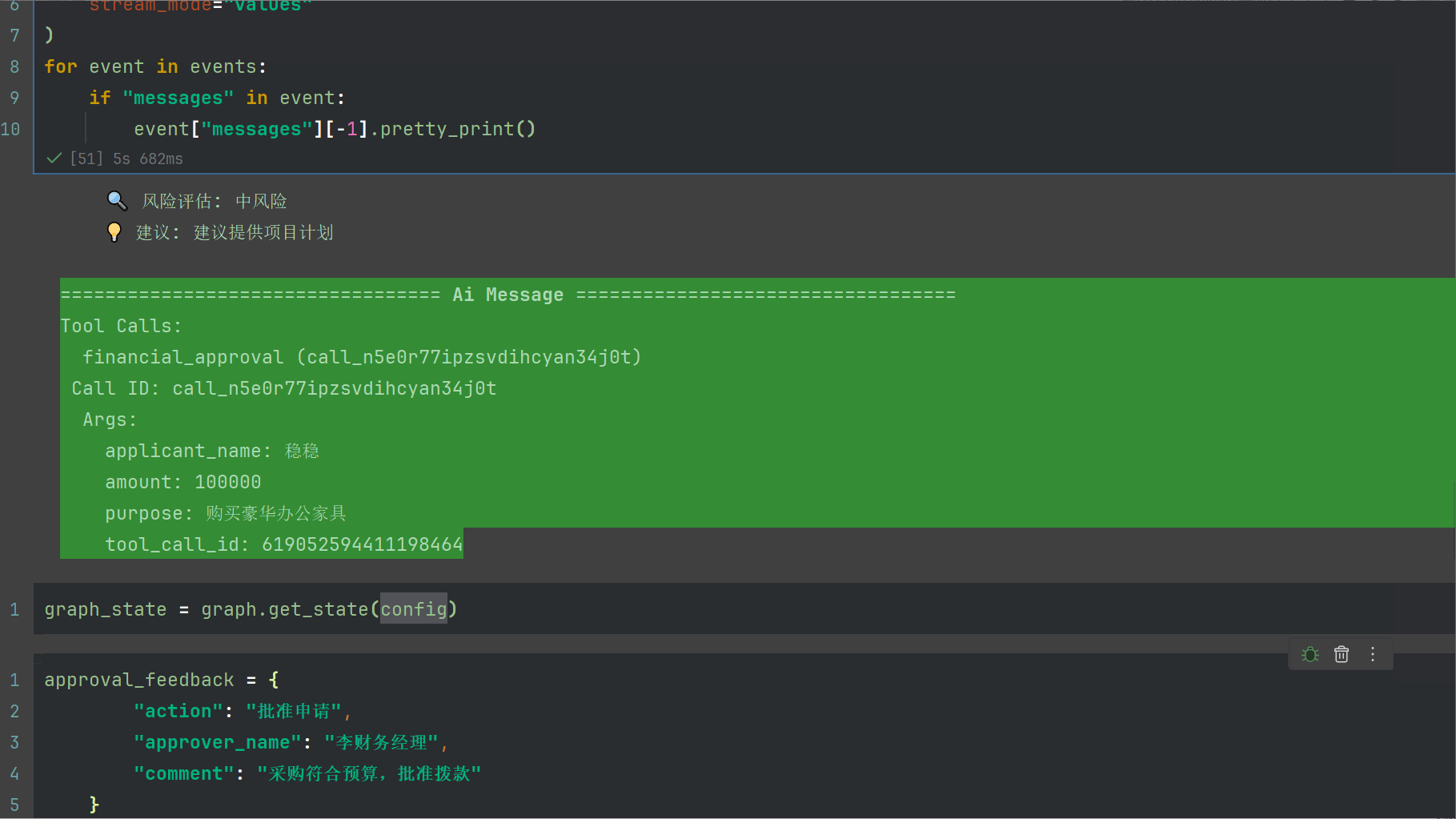
我们可以看到下面的堆栈,出现了中断,并且消息载体有4个,从human到tool到AI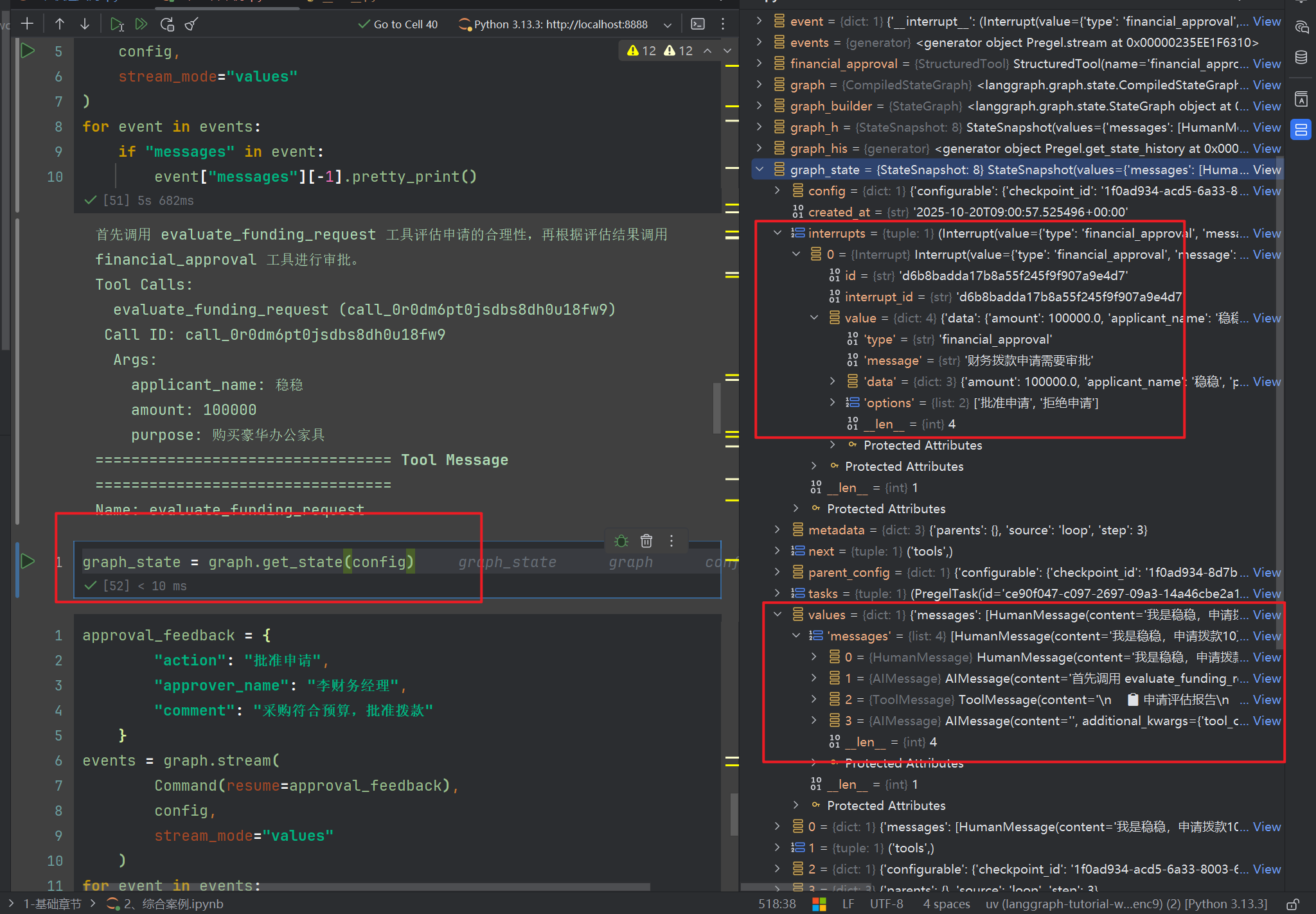
在生产环境中,可以利用系统,比如做消息通知相关财务,进行协作。这里我就直接模拟财务审核,并且中断的回复需要使用Command
approval_feedback = {
"action": "批准申请",
"approver_name": "李财务经理",
"comment": "采购符合预算,批准拨款"
}
events = graph.stream(
Command(resume=approval_feedback),
config,
stream_mode="values"
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
输出如下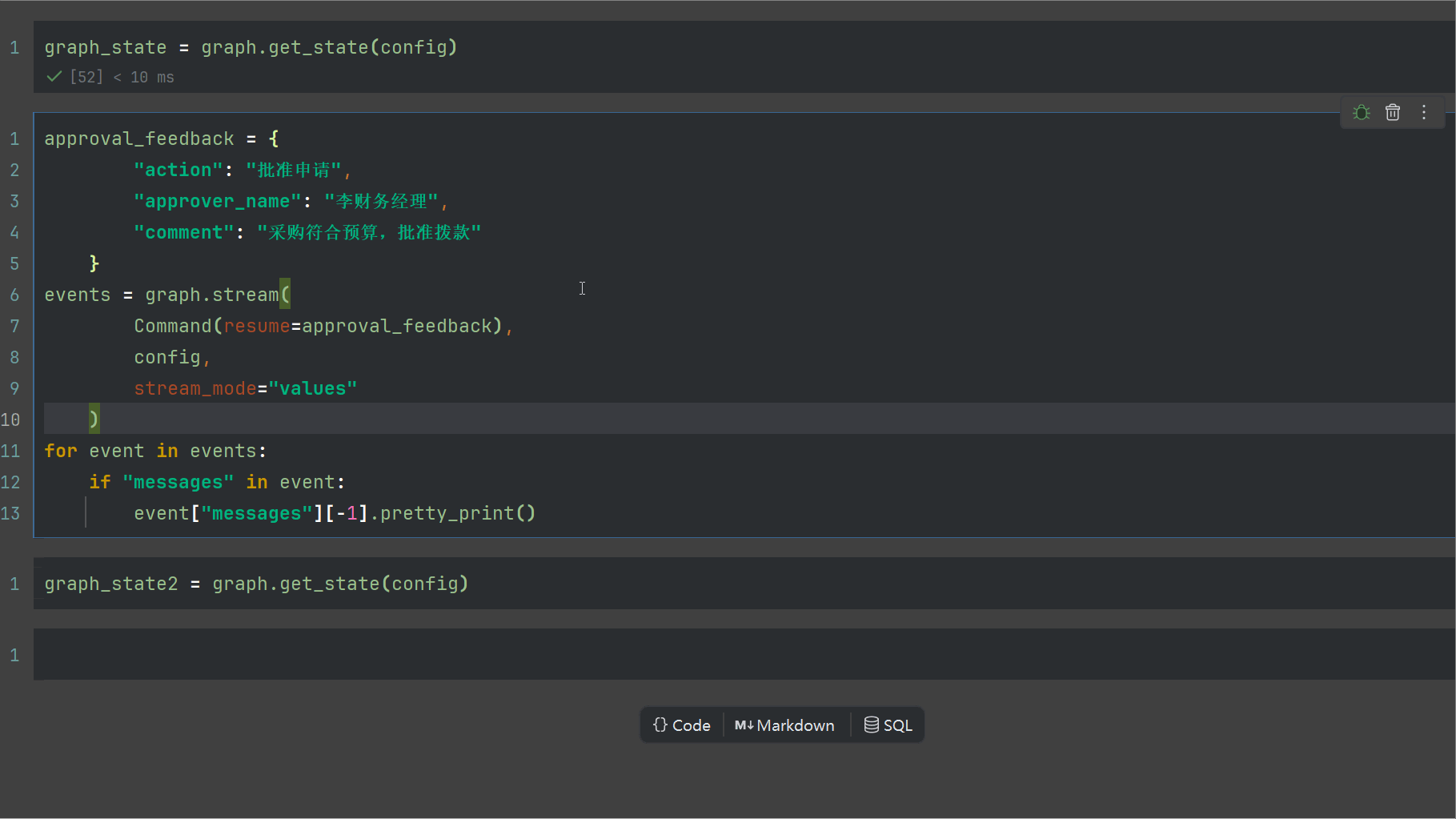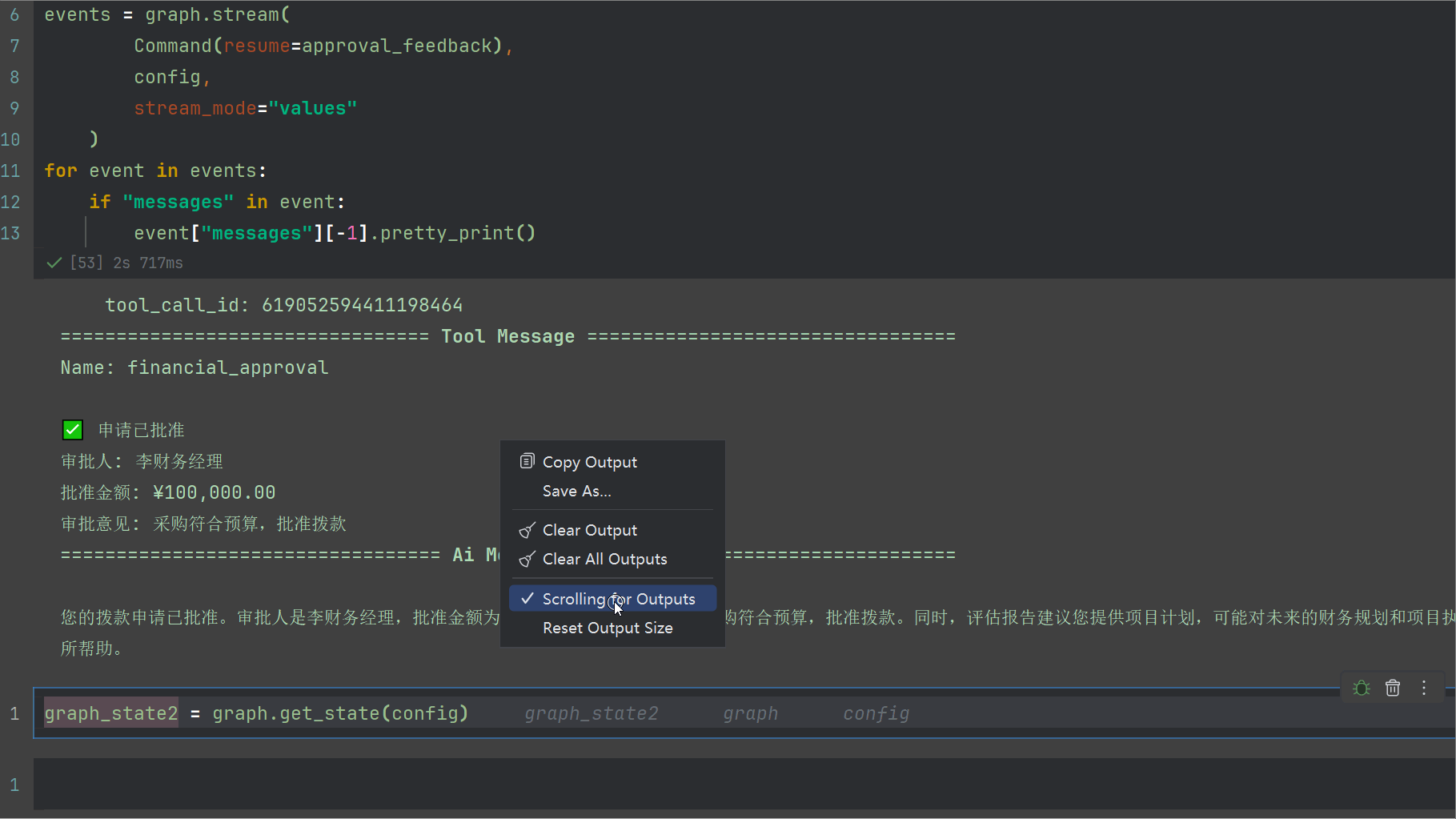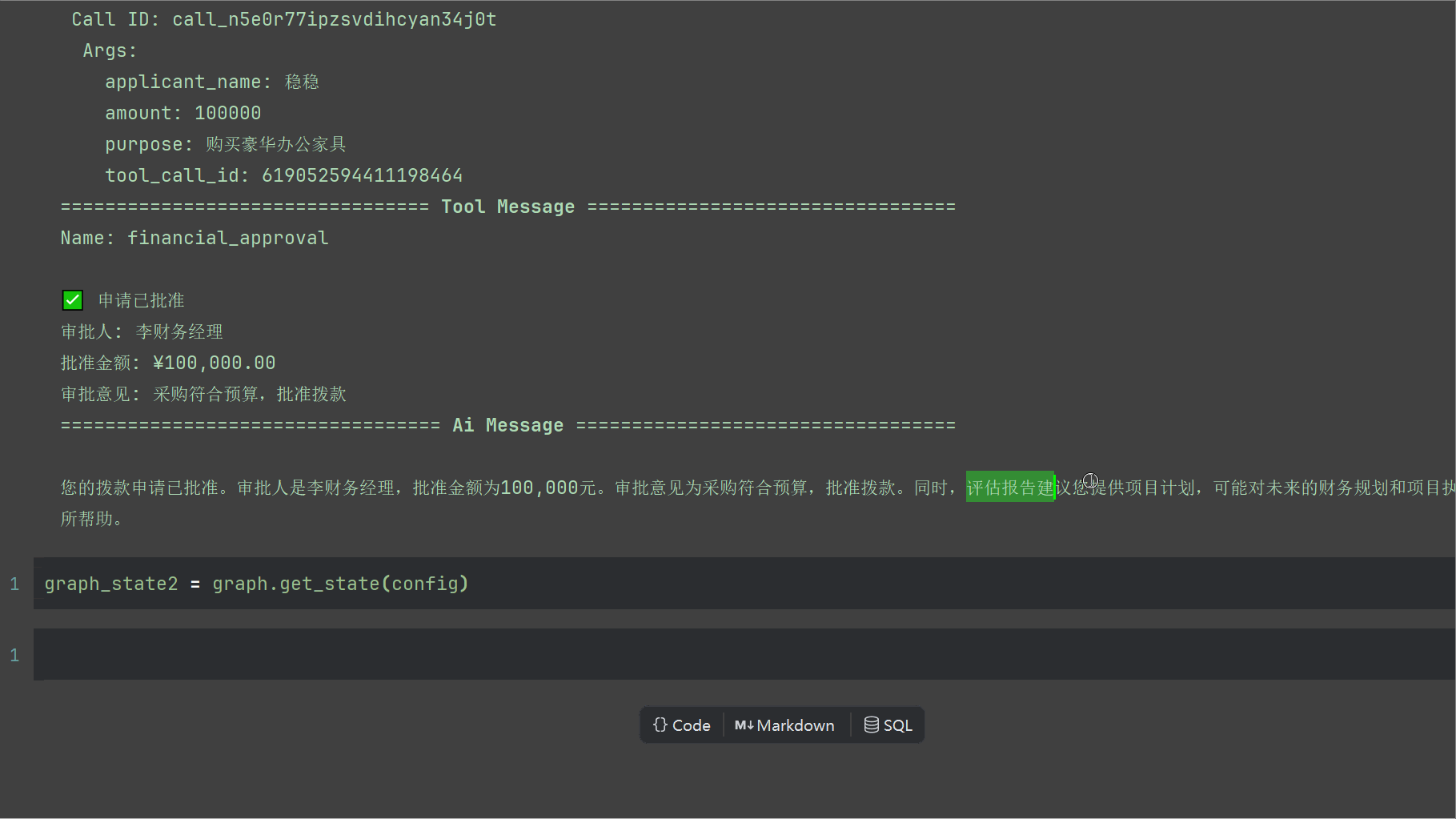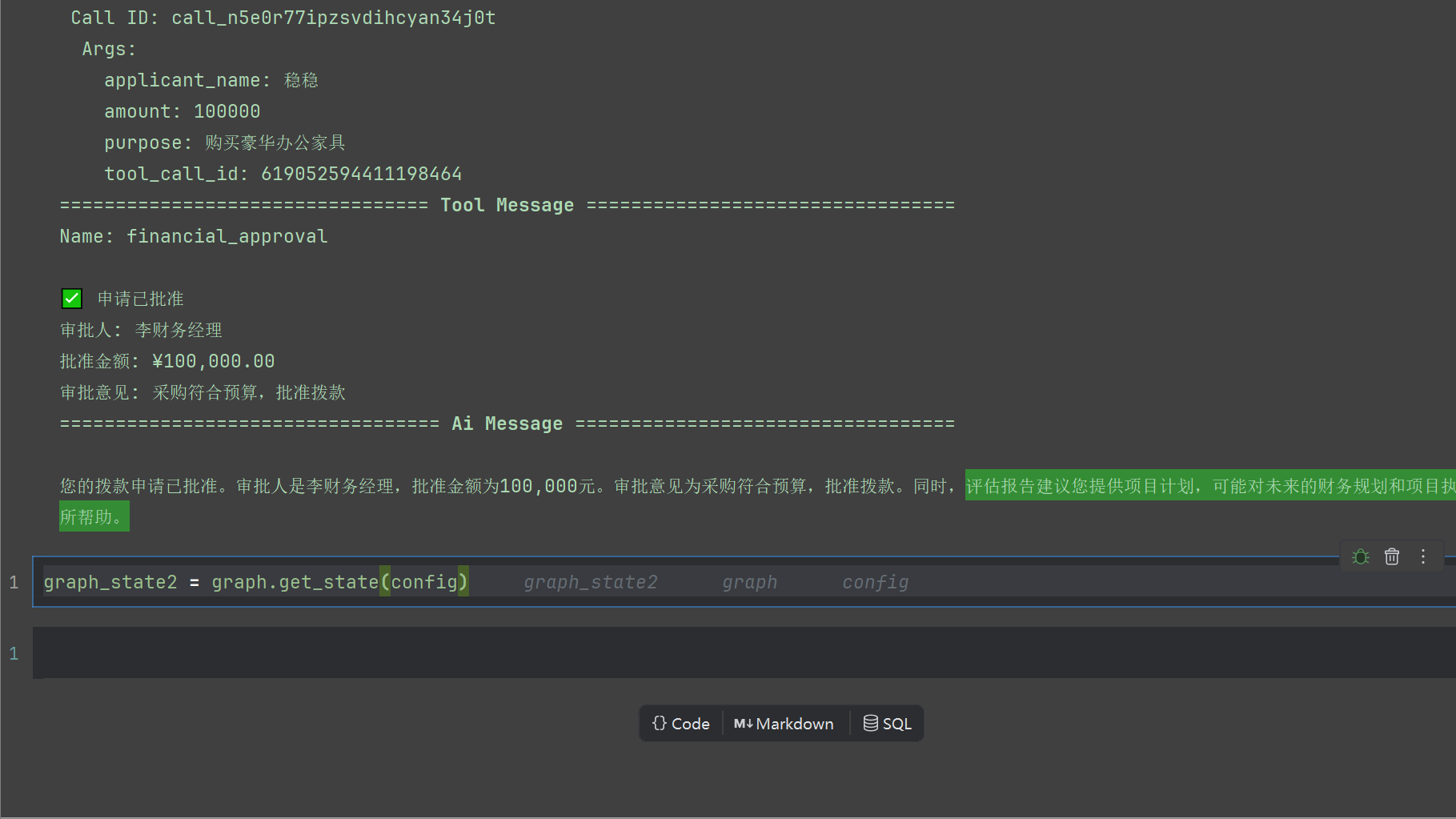
我们看看堆栈内容,消息最后可以看到AI最后的回复,以及状态机此时被改变了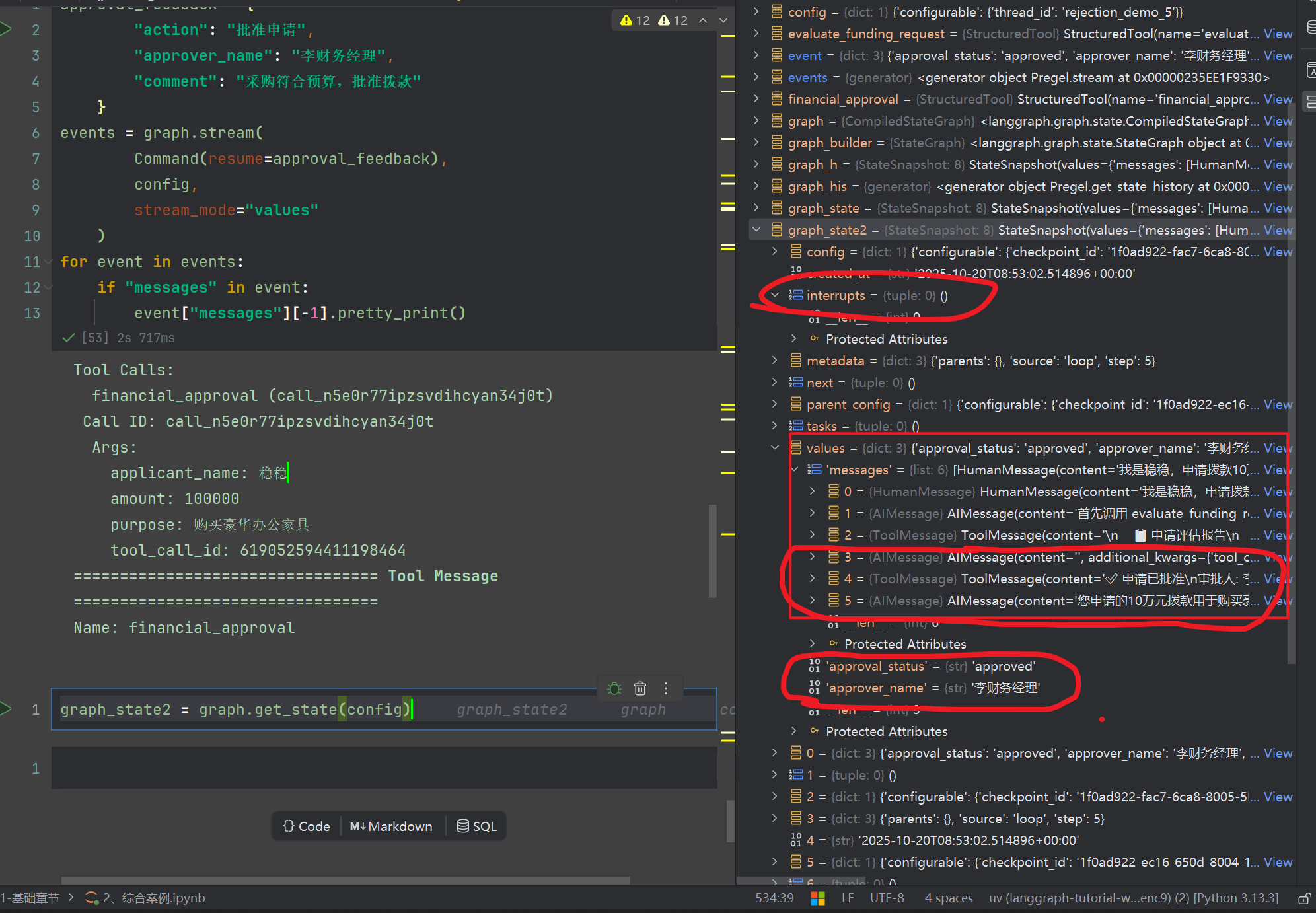
3.6 时间旅行
何为时间旅行?我们看过市面上的产品
- 交互式AI应用 - 用户可以"后悔"某个选择,回到之前重新开始
- 复杂工作流调试 - 开发者可以精确定位问题发生的节点
- A/B测试场景 - 从同一起点测试不同的AI决策路径
- 自主Agent开发 - 当Agent做出错误决策时,可以回溯并尝试替代方案
下面的案例,我们假定对于工具生成的结果不满意,重新生成,比如想豆包的设计
这里我们假定,有一个获取个人信息的工具,获取个人信息的工具,随机几个爱好,以便AI每次使用的时候,随机生成
3.6.1 基础代码
from typing import Annotated
from langchain_core.messages import BaseMessage
import random
from langchain.tools import tool
from typing_extensions import TypedDict
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_openai import ChatOpenAI
from IPython.display import Image, display
######################### 创建模型 #########################
llm = ChatOpenAI(model=modelName)
######################### 初始化图 #########################
# 创建信息载体
class State(TypedDict):
messages: Annotated[list, add_messages]
test:str
# 创建图
graph_builder = StateGraph(State)
######################### 构建工具 #########################
@tool
def get_personal_infos(name: str) -> dict:
"""
通过姓名获取个人信息
:param name:姓名
:return:
"""
return {
"name": name,
"age": 18,
"love": random.choice(["骑行","唱歌","跳舞","羽毛球"])
}
# 构建工具
tools = [get_personal_infos]
llm_with_tools = llm.bind_tools(tools)
######################### 绘制图 #########################
# 创建聊天节点
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 加入节点
graph_builder.add_node("chatbot",chatbot)
tool_node = ToolNode(tools=tools)
graph_builder.add_node("tools",tool_node)
# 构建条件分支节点
graph_builder.add_conditional_edges(
"chatbot",tools_condition
)
# 创建关系
graph_builder.add_edge("tools","chatbot")
# 开始
graph_builder.add_edge(START,"chatbot")
# 创建记忆点
memory = MemorySaver()
######################### 编译图 #########################
graph = graph_builder.compile(memory)
######################### 查看图 #########################
display(Image(graph.get_graph().draw_mermaid_png()))
运行上面代码
config = {"configurable":{"thread_id":"10086"}}
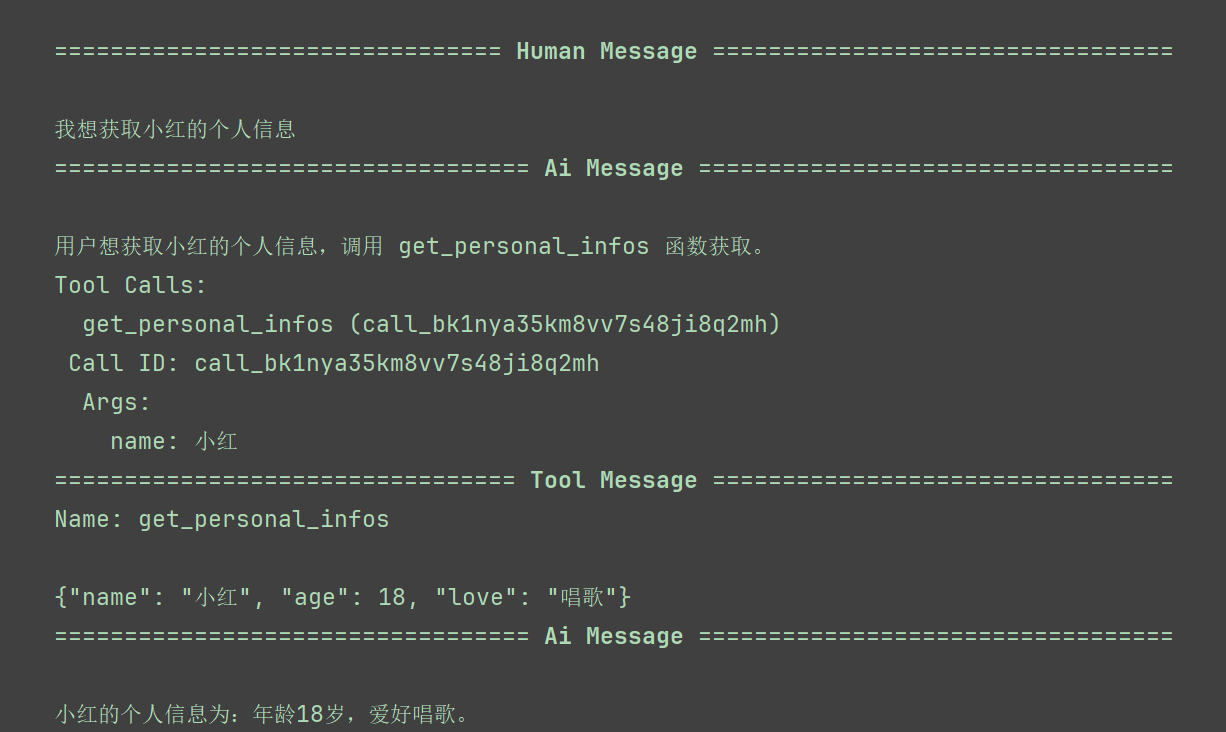
events = graph.stream({"messages":[{"role":"user","content":"我想获取小红的个人信息"}]},
config=config,
stream_mode="values"
)
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
输出如下
3.6.2 查看历史
graph_hist = list(graph.get_state_history(config))
可以看到有这么一个对象StateSnapshot 官方文档地址:https://langchain-ai.github.io/langgraph/reference/types/?h=statesnapshot#langgraph.types.StateSnapshot

查看堆栈,有5个对象,对应的其实,就是从问题开始到结束的所有步骤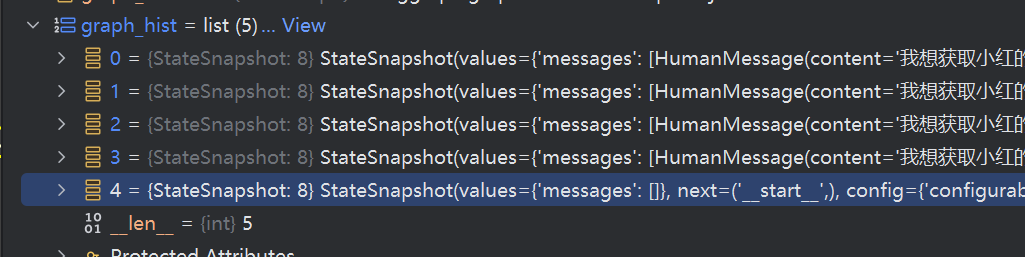
我们可以观察一下第4,跟第3个,以及第0个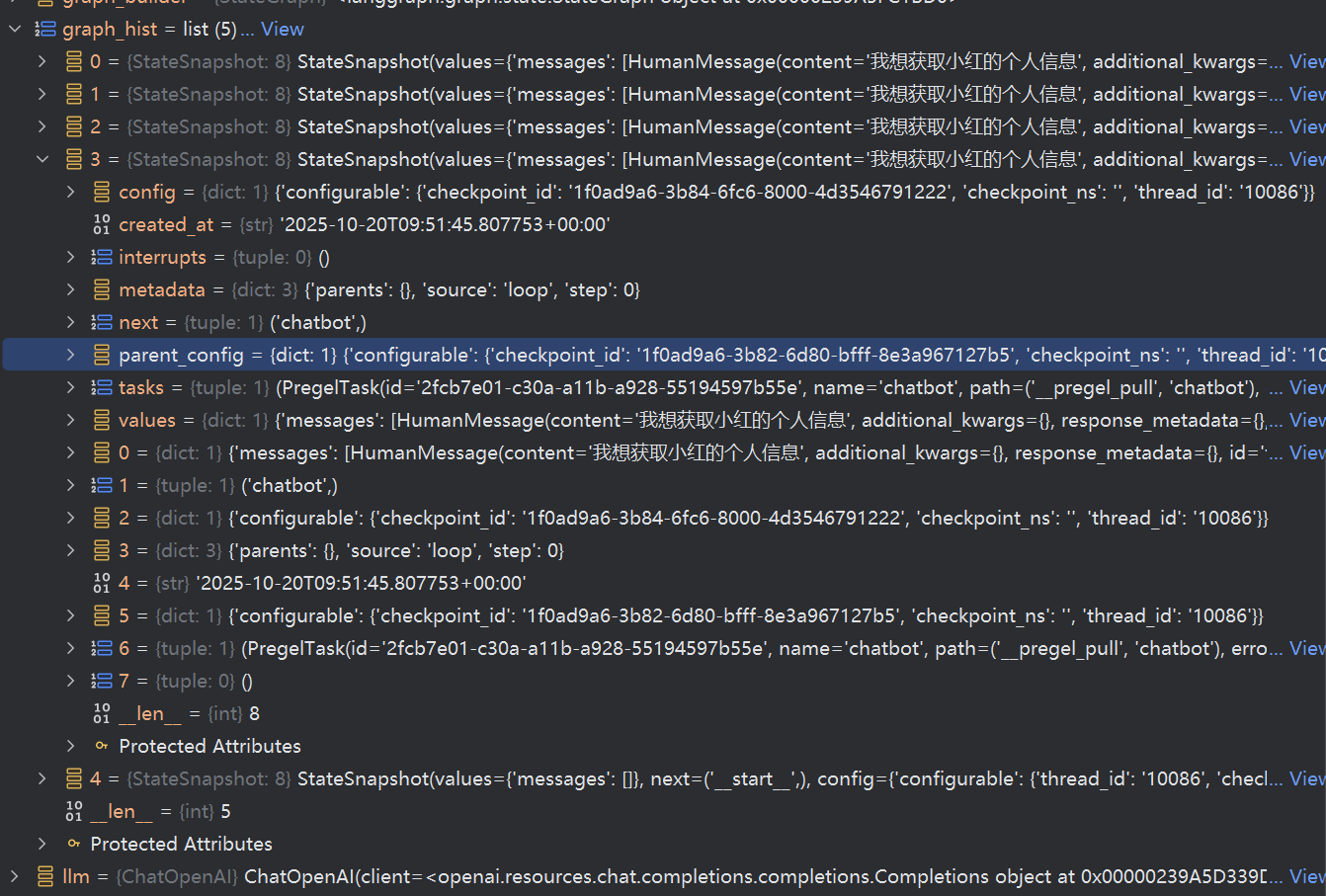
现在运行这段代码,我们看看
for StateSnapshot in graph_hist[::-1]:
print("下一个节点名称:",StateSnapshot.next)
print("当前执行步骤快照配置:\n",StateSnapshot.config)
print("上一步父快照配置:\n",StateSnapshot.parent_config)
print("★"*50,"\n")
这个记录了,从用户执行到工具结束所有的快照id
工具执行节点的ID为:1f0ad9a6-4780-608f-8001-d7ff1d762934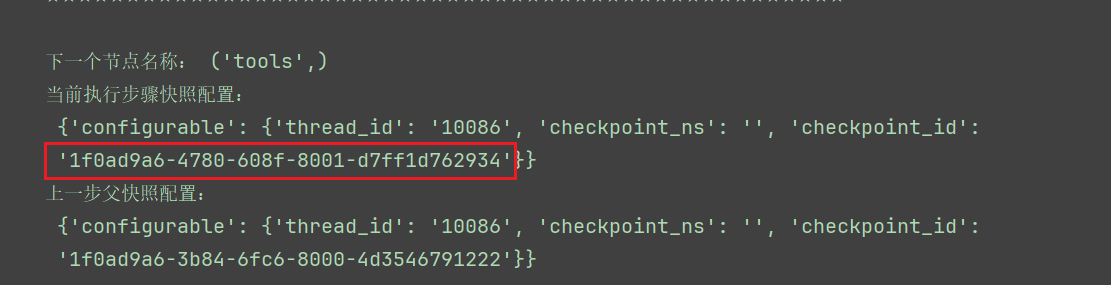
3.6.3 从某个快照/节点恢复
我们现在从工具节点重新生成
config = {'configurable': {
'thread_id': '10086',
'checkpoint_ns': '',
'checkpoint_id': '1f0ad9a6-4780-608f-8001-d7ff1d762934'}}
for event in graph.stream(None,config, stream_mode="values"):
if "messages" in event:
event["messages"][-1].pretty_print()
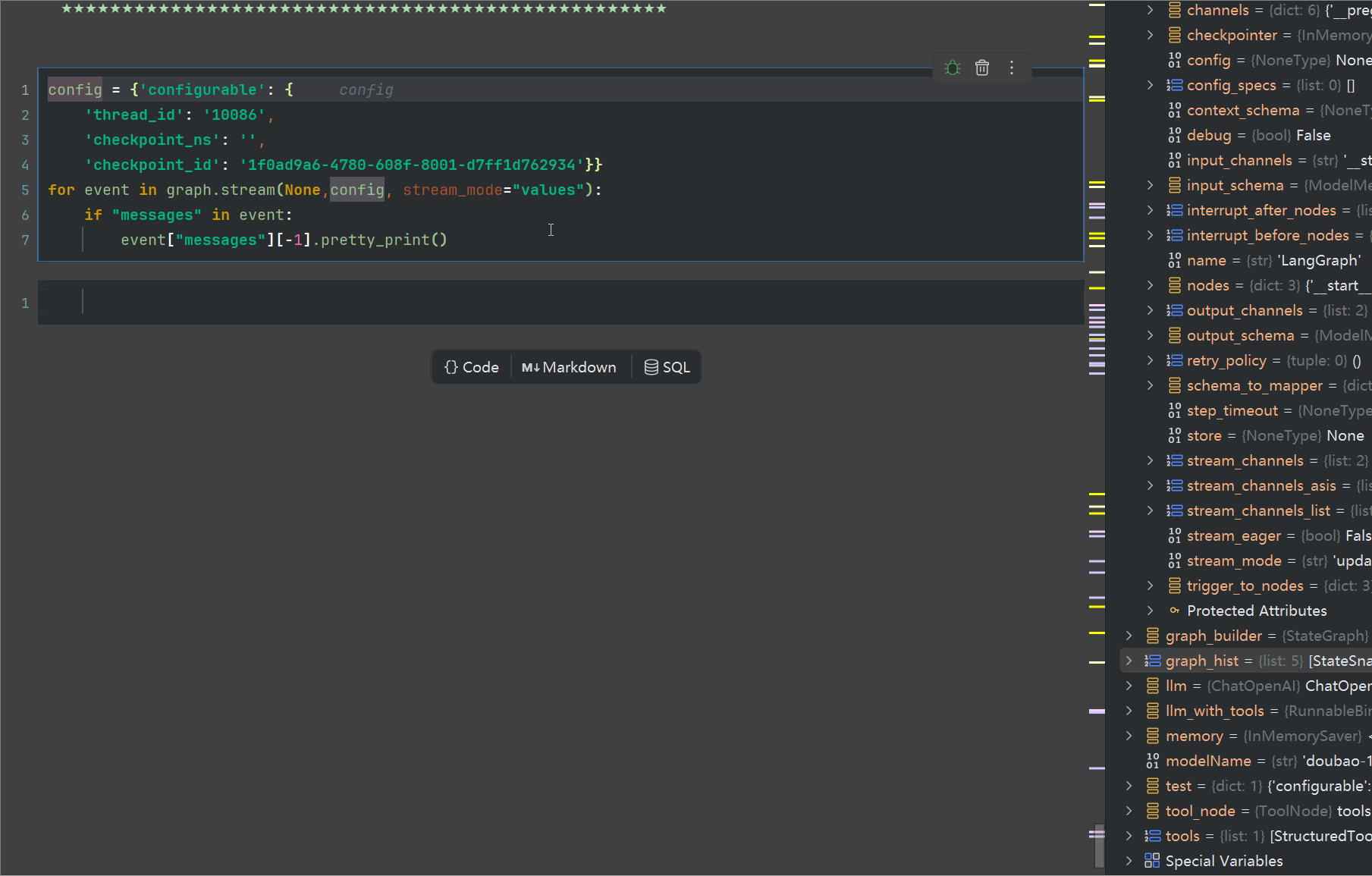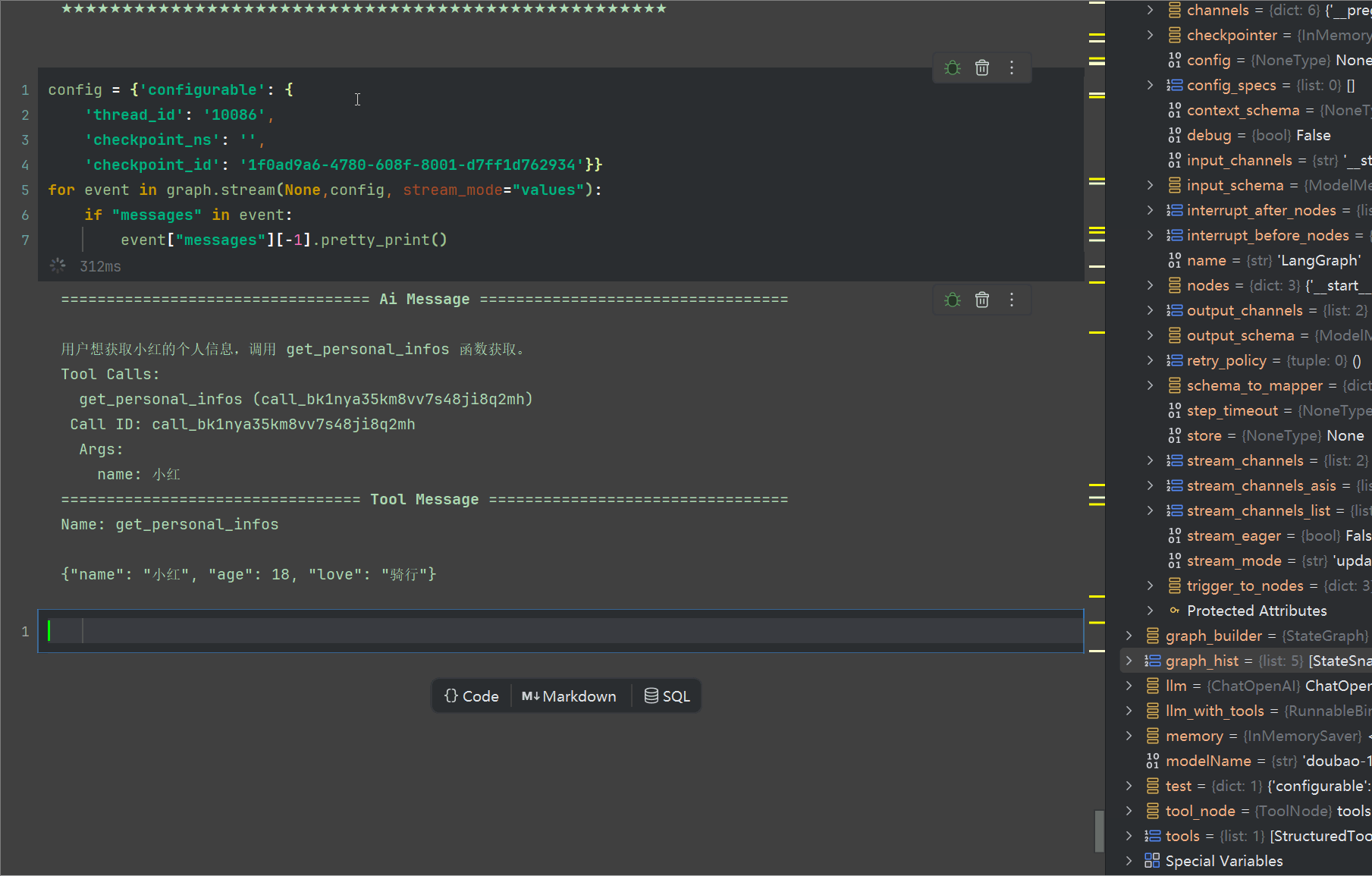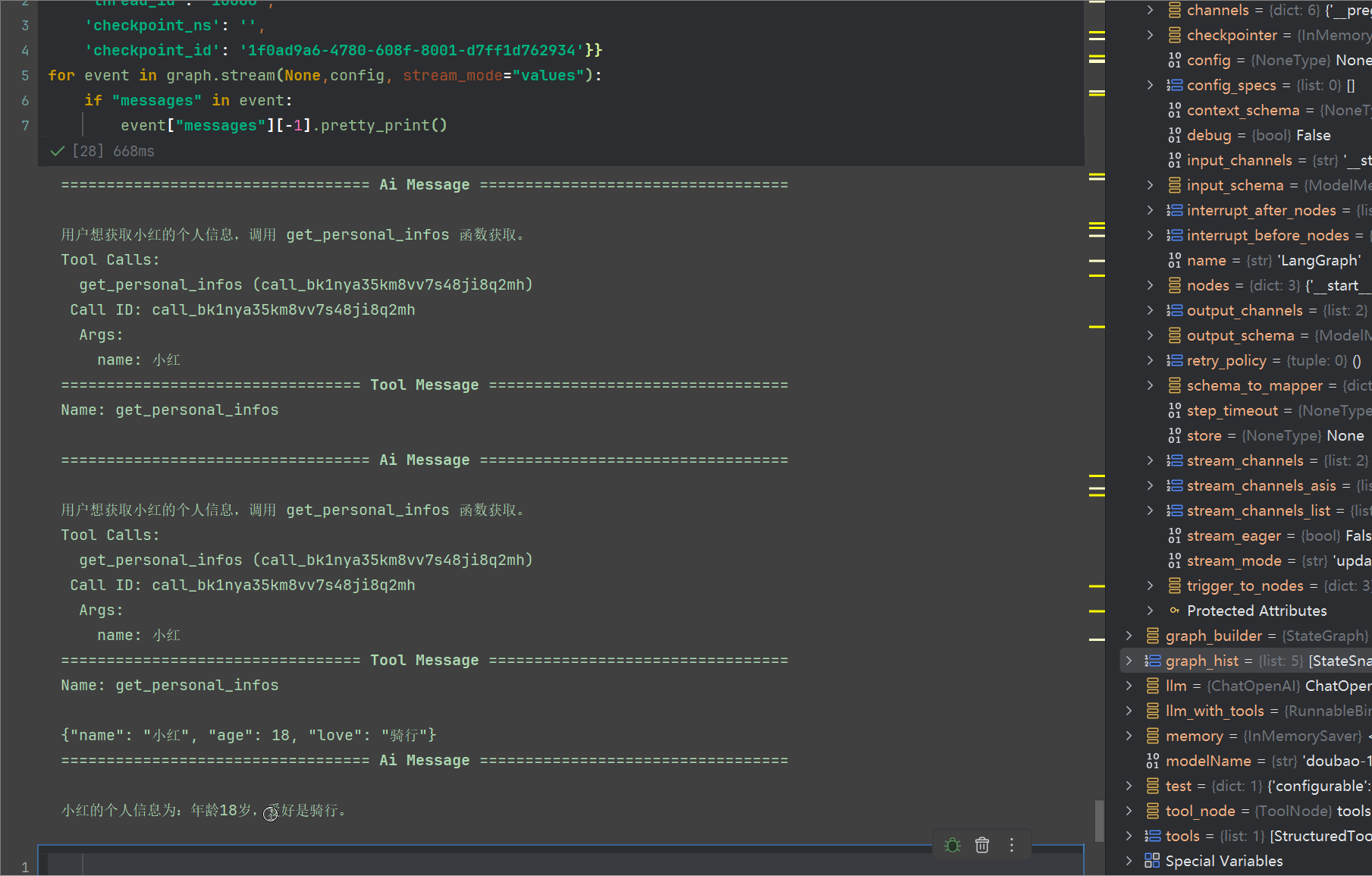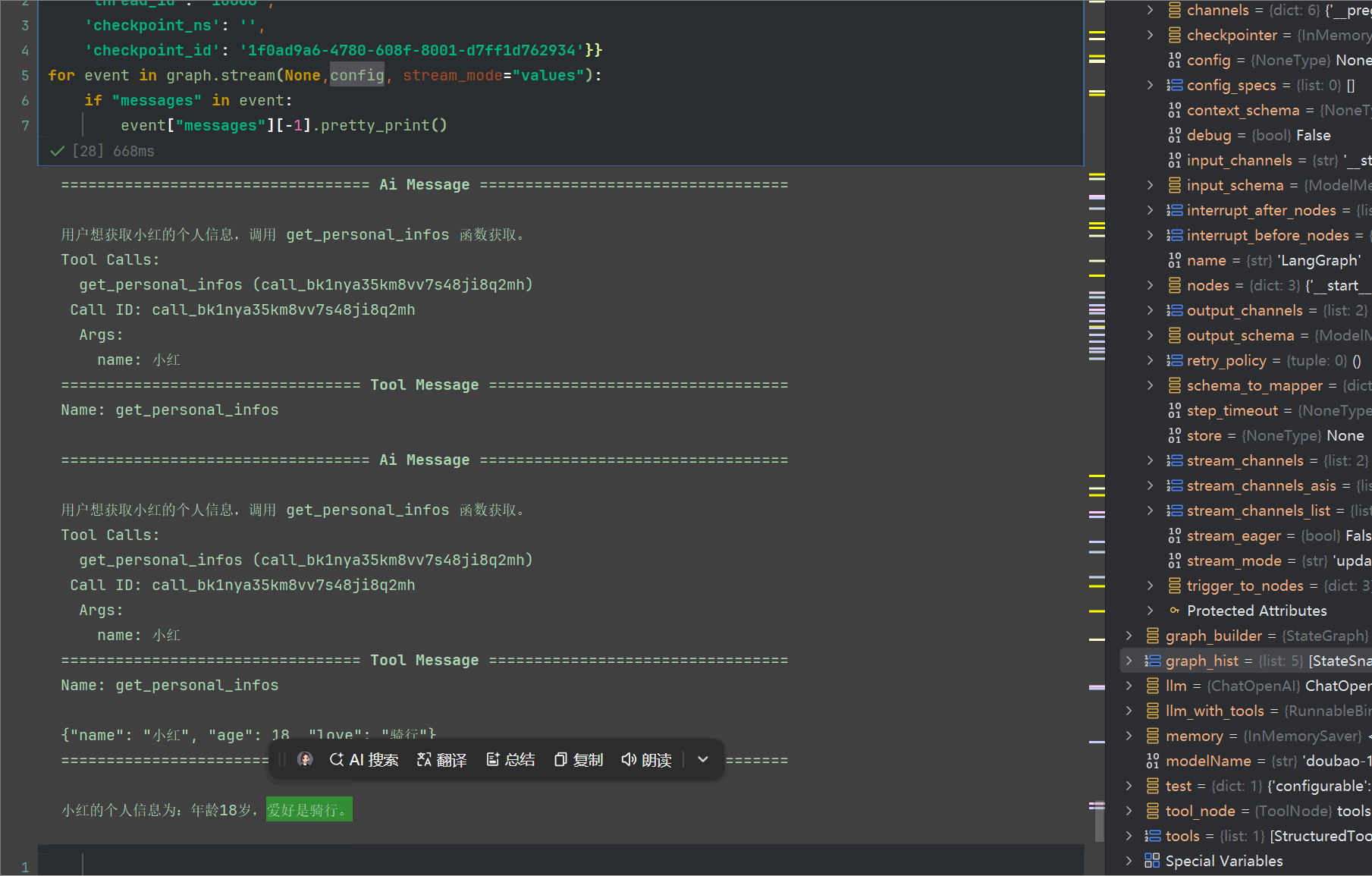
工具执行节点的ID为:1f0ad9a6-4780-608f-8001-d7ff1d762934,回顾一下,前面我们第一次执行出来的结果是唱歌,现在我们可以重复调用这个代码,可以看到会随机从["骑行","唱歌","跳舞","羽毛球"] 得到值,爱好骑行
三、总结
1、 什么是代理?
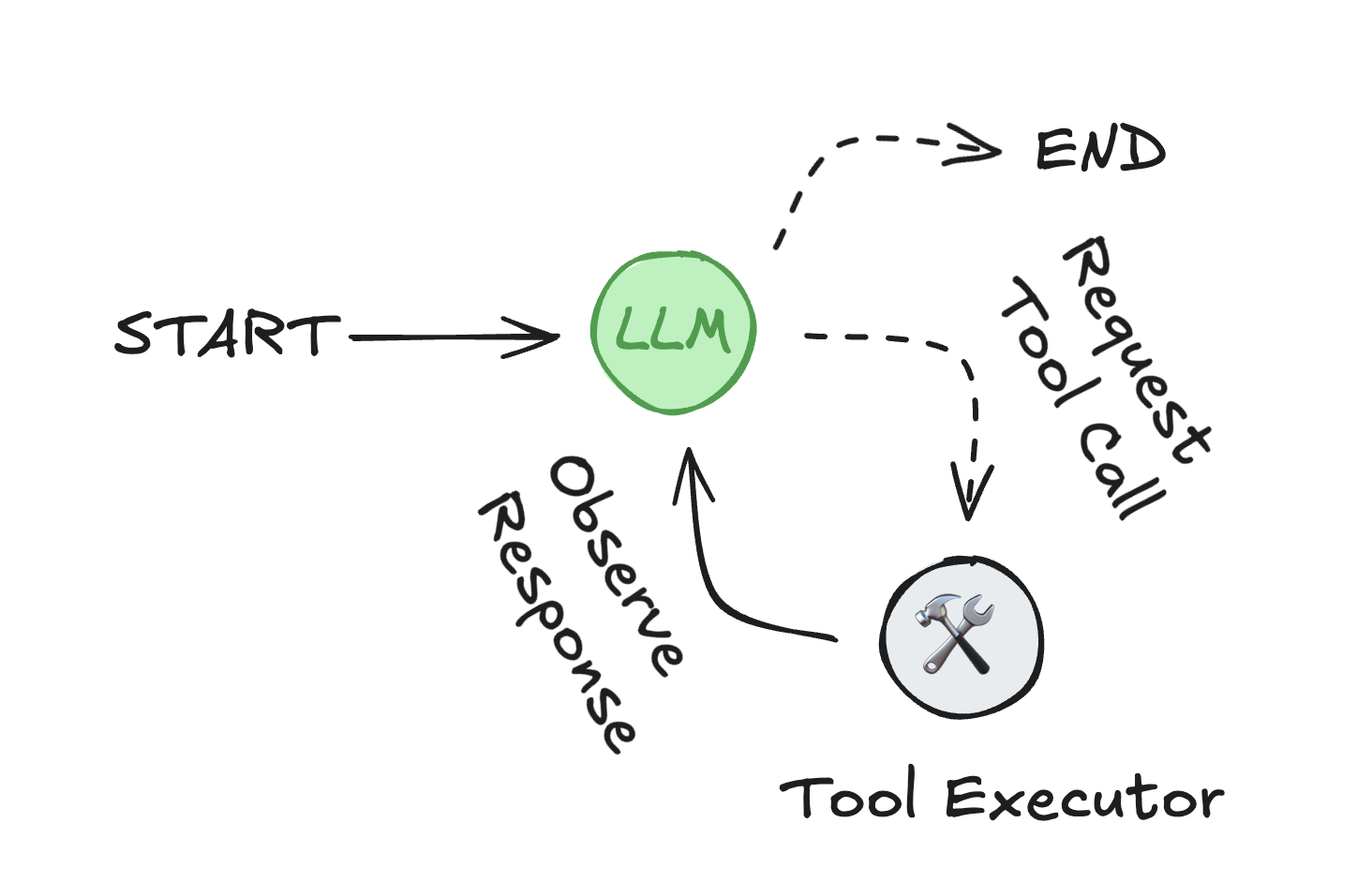
代理(Agent)由三个核心组件构成:
- 大语言模型(LLM):提供智能决策能力
- 工具集(Tools):可调用的函数、API或其他对象
- 提示词(Prompt):提供指令和上下文
2、 代理工作循环:
- LLM选择并调用工具
- 接收工具执行结果(观察)
- 基于观察决定下一步行动
- 重复循环直到满足停止条件
3、 关键特性:
- 内存集成:支持短期(会话级)和长期(跨会话)内存
- 人工介入控制:可无限期暂停等待人工反馈
- 流式支持:实时流式传输状态、token、工具输出
- 部署工具:包含LangGraph Platform和Studio可视化IDE
4、 预构建组件包生态:
| 包名 | 描述 | 安装命令 |
|---|---|---|
| langgraph-prebuilt | 创建基础代理的预构建组件 | pip install -U langgraph langchain |
| langgraph-supervisor | 构建监督者代理 | pip install -U langgraph-supervisor |
| langgraph-swarm | 构建群体多代理系统 | pip install -U langgraph-swarm |
| langchain-mcp-adapters | MCP服务器接口 | pip install -U langchain-mcp-adapters |
| langmem | 代理内存管理 | pip install -U langmem |
| agentevals | 代理性能评估工具 | pip install -U agentevals |
5、 核心组件详解:
- 节点(Nodes):图中的实体或对象,可包含属性和元数据
- 边(Edges):定义节点间的关系和连接
- 条件边(Conditional Edges):包含动态决策逻辑的连接
- 状态(State):维护当前上下文和交互历史
- 工具(Tools):可调用的功能和外部系统接口
- 路径(Paths):代理遍历图的节点和边序列
6、基础知识点总结:
6.1 创建模型
from langchain.chat_models import init_chat_model
llm = init_chat_model(model=f"openai:{modelName}")
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model=modelName)
6.2 创建代理
可以使用与构建组件,快速创建一个Agent
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import InMemorySaver
class WeatherResponse(BaseModel):
conditions: str
agent = create_react_agent(
model=model, # 既可以是模型字符串名称,也可以是模型的示例
tools=[get_weather],
prompt=prompt, # 既可以是prompt的静态content内容,也可以通过函数构建func实现动态prompt
checkpointer=checkpointer # 指定为内存节点 ,创建图的时候就要声明
response_format=WeatherResponse,# 指定结构化输出
)
为图添加记忆
- 可以在create_react_agent通过指定
response_format,
结构化输出
- 可以在create_react_agent通过指定
response_format,或者利用prompt结构化输出内容
6.3 图基础架构
- 状态机定义:使用
TypedDict定义状态,add_messages管理对话历史 - 图构建:
StateGraph→ 添加节点 → 添加边 →compile() - 节点类型:聊天节点、工具节点、条件路由节点
6.4 工具节点对比
6.4.1 自定义工具节点
class BasicToolNode:
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, state: State):
# 手动处理工具调用
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(tool_call["args"])
outputs.append(ToolMessage(...))
return {"messages": outputs}
6.4.2 内置工具节点
from langgraph.prebuilt import ToolNode
tool_node = ToolNode([get_personal_info]) # 一行搞定
对比要点:
- 自定义:完全控制工具调用逻辑,适合复杂业务场景
- 内置:开箱即用,代码简洁,适合标准工具调用
6.5 路由机制对比
6.5.1 自定义路由
def route_tools(state: State):
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return END
graph_builder.add_conditional_edges(
"chatbot",
route_tools, # 自定义路由函数
{"tools": "tools", END: END},
)
6.5.2 内置路由
from langgraph.prebuilt import tools_condition
graph_builder.add_conditional_edges(
"chatbot",
tools_condition, # 内置路由函数
{"tools": "tools", END: END},
)
对比要点:
- 自定义路由:灵活控制判断逻辑,支持复杂业务规则
- 内置路由:标准工具调用判断,代码简洁
6.6 工具集成
- 工具定义:使用
@tool装饰器 - 工具绑定:
llm.bind_tools(tools) - 工具路由:
tools_condition自动判断是否需要调用工具 - 工具节点:
ToolNode处理工具调用
6.7 人机交互
- 中断机制:
interrupt()暂停执行等待用户输入 - 恢复执行:
Command(resume=...)恢复执行 - 表单处理:通过
interrupt收集用户数据
6.8 记忆管理
- 检查点:
MemorySaver()提供持久化记忆 - 线程ID:
thread_id区分不同对话会话 - 状态历史:
get_state_history()查看执行历史
6.9 时间旅行
- 状态快照:每个执行步骤都有唯一
checkpoint_id - 回滚执行:通过
checkpoint_id回到任意历史状态 - 父级关系:
parent_config维护执行路径
6.10 高级特性
- 自定义状态:扩展状态字段支持复杂业务逻辑
- 条件路由:
add_conditional_edges实现智能分支 - 工具注入:
InjectedToolCallId自动注入工具调用ID - 状态更新:
Command(update=...)批量更新状态
6.11 关键设计模式
- 流式处理:
stream()实时获取执行结果 - 事件驱动:通过事件循环处理异步操作
- 状态持久化:自动保存和恢复执行状态
- 可观测性:完整的执行历史和状态追踪
6.12 选择策略
- 简单场景:使用内置
ToolNode+tools_condition - 复杂业务:自定义工具节点 + 自定义路由
- 性能要求:内置组件性能更优
- 灵活性要求:自定义组件控制更精细

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐


 39
39 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)