内存、性能、并发、生态:Rust 凭什么与主流语言同台竞技?
本文从内存管理、性能表现、并发模型和生态系统四个维度对比了Rust与主流编程语言的技术特性。Rust通过所有权机制实现编译期内存安全,在性能上接近C++,其并发模型兼具安全性与高效性。相比Java的GC机制、Go的轻量级线程和C++的灵活性,Rust提供了一种新的安全范式选择。文章指出技术选型需要权衡性能、开发效率和生态支持,Rust特别适合对可靠性和性能要求高的系统级开发场景。最后强调应根据实际
随着现代软件系统对安全性、性能和并发处理能力的要求不断提升,编程语言的设计理念和技术特性也在持续演进。Rust作为一门相对年轻的系统编程语言,以其独特的内存安全、零成本抽象、并发可靠特性迅速崛起,成为与C/C++、Java、Go等主流语言同台竞技的重要选项。本文从工程实践中最核心的四个维度——内存管理、性能表现、并发模型和生态系统,结合代码示例,剖析Rust与主流编程语言的差异,为开发者的技术选型提供参考。
目录
一、内存管理
内存管理是系统编程的核心考量因素,不同语言通过不同的机制实现安全性与效率之间的平衡,这也是Rust与传统语言在设计上最显著的差异点之一。
1.1 Rust:编译期所有权机制
Rust彻底摒弃了手动管理和垃圾回收两种传统模式,独创所有权(Ownership)、借用(Borrowing)、生命周期(Lifetime)三位一体的编译期检查机制,将内存安全问题提前到编码阶段解决,运行时无任何额外开销。其核心逻辑可概括为三个明确:
所有权唯一:每个值在内存中仅有一个“所有者”,当所有者离开作用域(如函数执行结束、变量超出代码块),值会被自动释放,从根源杜绝内存泄漏;
借用规则严格:值的引用(借用)分为不可变引用(&T)和可变引用(&mut T),同一时间要么存在多个不可变引用,要么仅存在一个可变引用,彻底规避数据竞争;
生命周期显式化:通过生命周期标注(如&'a T)明确引用的有效范围,编译器据此判断引用是否合法,避免悬垂引用。
下面的代码示例同时展示了所有权转移与生命周期的实际应用,这是Rust内存管理的核心实践场景:
// 生命周期标注示例:返回两个字符串切片中较长的一个
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}
fn main() {
// 所有权转移场景
let mut s1 = String::from("Rust ownership");
let s2 = s1; // s1的所有权转移给s2,s1自此失效
// println!("{}", s1); // 编译错误:value borrowed here after move
// 借用规则场景
let s3 = String::from("borrowing rule");
let r1 = &s3; // 不可变借用
let r2 = &s3; // 允许多个不可变借用
println!("Two immutable borrows: {} and {}", r1, r2);
let mut s4 = String::from("mutable borrow");
let r3 = &mut s4; // 可变借用
r3.push_str(" test");
println!("Mutable borrow result: {}", r3);
// let r4 = &s4; // 编译错误:可变借用期间不允许不可变借用
// 生命周期应用场景
let str1 = String::from("hello");
let str2 = "world rust";
let result = longest(str1.as_str(), str2);
println!("Longer string: {}", result);
}
运行结果:

这种机制的优势在于编译期买单,运行期免费——开发者只需遵循规则编写代码,编译器即可完成所有安全检查,运行时无需GC线程占用资源,也无需手动调用释放函数。其局限则是学习曲线陡峭,需理解抽象的生命周期概念。
1.2 C++:手动管理+智能指针
C++默认采用手动内存管理机制,通过new/delete操作符进行内存分配和释放,这种设计提供了极大的灵活性但也容易导致内存泄漏、野指针、双重释放等经典问题。C++11之后引入的智能指针(如unique_ptr、shared_ptr)在一定程度上模拟了所有权概念,但开发者仍需深入理解底层逻辑,且运行时存在引用计数的开销。
#include <iostream>
#include <memory>
#include <vector>
using namespace std;
int main() {
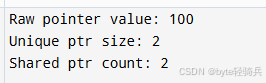
// 1. 原始手动管理:灵活但风险高
int* raw_ptr = new int[1024]; // 分配1024个int的数组
raw_ptr[0] = 100;
cout << "Raw pointer value: " << raw_ptr[0] << endl;
delete[] raw_ptr; // 必须手动释放,遗漏则内存泄漏
// 2. 智能指针:unique_ptr独占所有权
unique_ptr<vector<int>> unique_vec = make_unique<vector<int>>();
unique_vec->push_back(1);
unique_vec->push_back(2);
// unique_ptr<vector<int>> unique_vec2 = unique_vec; // 编译错误:独占所有权不可复制
cout << "Unique ptr size: " << unique_vec->size() << endl;
// 无需手动释放,超出作用域自动销毁
// 3. 智能指针:shared_ptr共享所有权(引用计数)
shared_ptr<string> shared_str = make_shared<string>("shared ownership");
shared_ptr<string> shared_str2 = shared_str; // 引用计数+1(此时为2)
cout << "Shared ptr count: " << shared_str.use_count() << endl;
// 最后一个shared_ptr销毁时,内存才会释放
}
运行结果:
1.3 Java:垃圾回收自动管理
Java通过JVM的垃圾回收机制实现自动内存管理,开发者无需关注内存释放的具体时机,大大提高了开发效率和内存安全性。但GC运行时会暂停应用线程(Stop-The-World现象),虽然G1、ZGC等新一代收集器不断优化暂停时间,但在高吞吐量和低延迟场景下仍可能产生不可预测的性能波动。
public class MemoryManagementDemo {
private static class DataHolder {
private byte[] data = new byte[1024 * 1024]; // 1MB数据
private String description;
public DataHolder(String desc) {
this.description = desc;
}
}
public static void demonstrateGarbageCollection() {
// JVM自动管理内存分配,无需手动释放
DataHolder holder1 = new DataHolder("First allocation");
DataHolder holder2 = new DataHolder("Second allocation");
// 对象引用置空,成为GC候选对象
holder1 = null;
// 显式建议JVM进行垃圾回收(仅用于演示,生产环境不推荐)
System.gc();
// 强制进行最终化操作
System.runFinalization();
System.out.println("Garbage collection demonstration completed");
}
public static void main(String[] args) {
demonstrateGarbageCollection();
// 内存分配压力测试
for (int i = 0; i < 100; i++) {
new DataHolder("Temporary object " + i);
}
System.gc(); // 再次触发GC观察行为
}
}运行结果:
![]()
1.4 Go:并发标记清除GC
Go语言采用并发标记清除+三色标记的垃圾回收算法,其设计目标是在保证自动内存管理的同时最小化STW时间(通常控制在微秒级别),在自动管理和性能之间取得了较好的平衡。但与Rust的编译期管理相比,Go仍存在运行时的GC开销,且在内存使用效率上通常高于编译期管理的语言。
package main
import (
"fmt"
"runtime"
"time"
)
type DataStruct struct {
payload []byte
id int
}
func demonstrateGoGC() {
fmt.Println("开始Go垃圾回收演示")
// 创建大量临时对象模拟内存分配压力
for i := 0; i < 10000; i++ {
data := &DataStruct{
payload: make([]byte, 1024), // 每个对象1KB
id: i,
}
_ = data // 使用后立即成为垃圾
}
// 显式触发GC(实际开发中通常不需要)
runtime.GC()
// 查看GC统计信息
var memStats runtime.MemStats
runtime.ReadMemStats(&memStats)
fmt.Printf("GC次数: %d\n", memStats.NumGC)
fmt.Printf("最近GC暂停时间: %v\n", time.Duration(memStats.PauseNs[(memStats.NumGC+255)%256]))
}
func main() {
demonstrateGoGC()
// 持续内存分配模式演示
var holders []*DataStruct
for i := 0; i < 1000; i++ {
holder := &DataStruct{
payload: make([]byte, 10*1024), // 10KB对象
id: i,
}
holders = append(holders, holder)
if i%100 == 0 {
fmt.Printf("已分配 %d 个对象\n", i+1)
}
}
// 释放部分引用
holders = holders[:500]
runtime.GC() // 观察部分对象被回收
}运行结果:

二、性能表现
编程语言的性能特征受到编译优化策略、运行时开销、内存布局效率等多重因素的影响。从技术架构角度看,Rust与C++同属静态编译语言,在性能上最为接近,而Java和Go由于各自的运行时机制存在不同程度的性能特征差异。
2.1 Rust与C++
Rust和C++都是静态编译型语言,不依赖虚拟机环境,支持直接内存访问和零成本抽象。两者都基于LLVM编译器框架,在优化能力上相当接近。在标准基准测试中,如计算密集型任务和系统级操作,两者的性能差异通常在5%以内。
// Rust性能基准测试示例:大规模数据排序
use std::time::{Instant, Duration};
fn benchmark_sort_performance() -> Duration {
const SIZE: usize = 1_000_000;
let mut test_data: Vec<i32> = (0..SIZE as i32).rev().collect();
let start_time = Instant::now();
test_data.sort_unstable(); // 使用不稳定排序以获得最佳性能
start_time.elapsed()
}
fn benchmark_computation() -> Duration {
const ITERATIONS: usize = 10_000_000;
let mut accumulator: f64 = 0.0;
let start_time = Instant::now();
for i in 0..ITERATIONS {
accumulator += (i as f64).sqrt().sin();
}
start_time.elapsed()
}
fn main() {
println!("Rust性能基准测试");
// 排序性能测试
let sort_duration = benchmark_sort_performance();
println!("100万整数排序耗时: {:?}", sort_duration);
// 计算性能测试
let compute_duration = benchmark_computation();
println!("1000万次数学计算耗时: {:?}", compute_duration);
// 内存分配性能测试
let alloc_start = Instant::now();
let large_vec: Vec<u64> = Vec::with_capacity(1_000_000);
std::mem::forget(large_vec); // 避免释放开销影响计时
println!("大内存块分配耗时: {:?}", alloc_start.elapsed());
}运行结果:

对应的C++基准测试实现:
#include <iostream>
#include <vector>
#include <chrono>
#include <algorithm>
#include <cmath>
using namespace std;
using namespace std::chrono;
class PerformanceBenchmark {
public:
static duration<double> benchmarkSort() {
const size_t SIZE = 1000000;
vector<int> data(SIZE);
for (size_t i = 0; i < SIZE; ++i) {
data[i] = SIZE - i - 1;
}
auto start = high_resolution_clock::now();
sort(data.begin(), data.end());
auto end = high_resolution_clock::now();
return duration_cast<duration<double>>(end - start);
}
static duration<double> benchmarkComputation() {
const size_t ITERATIONS = 10000000;
double accumulator = 0.0;
auto start = high_resolution_clock::now();
for (size_t i = 0; i < ITERATIONS; ++i) {
accumulator += sin(sqrt(static_cast<double>(i)));
}
auto end = high_resolution_clock::now();
return duration_cast<duration<double>>(end - start);
}
};
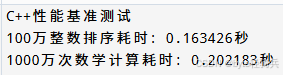
int main() {
cout << "C++性能基准测试" << endl;
auto sort_time = PerformanceBenchmark::benchmarkSort();
cout << "100万整数排序耗时: " << sort_time.count() << "秒" << endl;
auto compute_time = PerformanceBenchmark::benchmarkComputation();
cout << "1000万次数学计算耗时: " << compute_time.count() << "秒" << endl;
return 0;
}运行结果:
根据多个基准测试项目的综合结果(如The Computer Language Benchmarks Game),在典型工作负载下各语言的相对性能大致如下:
| 语言 | 相对性能基准 | 主要运行时特征 |
| C++ | 1.0x(基准) | 无运行时开销,极致优化 |
| Rust | 0.95-1.02x | 无运行时开销,安全约束下优化 |
| Go | 0.7-0.9x | 轻量运行时,GC开销可控 |
| Java | 0.6-0.8x | JVM JIT优化,但GC和元数据开销 |
| Python | 0.05-0.2x | 解释执行,动态类型开销 |
2.2 Java
Java采用半编译半解释的执行模型,通过JIT编译器在运行时将热点代码编译为本地机器码,这种渐进式优化使得Java应用在预热后能够获得接近本地代码的性能。但在应用启动阶段和初次执行路径上,解释执行和JIT编译会带来明显的性能开销。
import java.util.Arrays;
import java.util.Random;
public class JavaVsRustComparison {
// Java排序实现
public static long javaSortBenchmark(int size) {
int[] data = new int[size];
Random random = new Random();
for (int i = 0; i < size; i++) {
data[i] = random.nextInt(size);
}
long startTime = System.nanoTime();
Arrays.sort(data);
return System.nanoTime() - startTime;
}
// 内存分配测试
public static long memoryAllocationBenchmark(int size) {
long startTime = System.nanoTime();
int[][] arrays = new int[1000][];
for (int i = 0; i < 1000; i++) {
arrays[i] = new int[size];
}
return System.nanoTime() - startTime;
}
public static void main(String[] args) {
// 使用英文输出避免编码问题
System.out.println("Java Performance Benchmark Results");
System.out.println("==================================");
// 不同数据规模的测试
int[] sizes = {10000, 50000, 100000};
for (int size : sizes) {
long sortTime = javaSortBenchmark(size);
long allocTime = memoryAllocationBenchmark(size / 100);
System.out.printf("Data size: %,d%n", size);
System.out.printf("Sort time: %.2f ms%n", sortTime / 1_000_000.0);
System.out.printf("Memory allocation time: %.2f ms%n", allocTime / 1_000_000.0);
System.out.println("---");
}
// JVM信息
System.out.println("JVM Information:");
System.out.println("Java version: " + System.getProperty("java.version"));
System.out.println("JVM name: " + System.getProperty("java.vm.name"));
System.out.println("Available processors: " + Runtime.getRuntime().availableProcessors());
}
}运行结果:
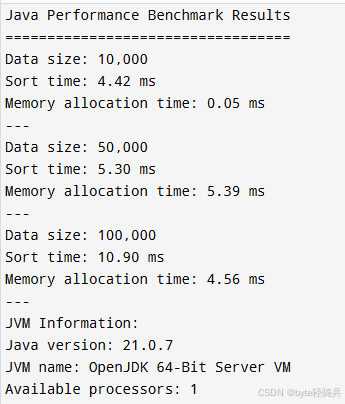
2.3 Go
Go语言虽然也是静态编译,但其运行时包含了垃圾回收器、协程调度器等组件,在内存分配效率和执行速度上略低于Rust和C++。不过,Go的编译速度极快,且生成的二进制文件包含完整的运行时,部署简便,在云原生场景下这一优势尤为明显。
package main
import (
"fmt"
"runtime" // 补充导入runtime包
"sort"
"time"
)
func benchmarkSort() time.Duration {
const size = 1000000
data := make([]int, size)
for i := range data {
data[i] = size - i - 1
}
start := time.Now()
sort.Ints(data)
return time.Since(start)
}
go
func benchmarkAllocation() time.Duration {
start := time.Now()
// 分配大量小对象
for i := 0; i < 100000; i++ {
_ = make([]byte, 128)
}
return time.Since(start)
}
func main() {
fmt.Println("Go性能基准测试")
sortTime := benchmarkSort()
fmt.Printf("100万整数排序耗时: %d 微秒\n", sortTime.Microseconds())
allocTime := benchmarkAllocation()
fmt.Printf("10万个小对象分配耗时: %d 微秒\n", allocTime.Microseconds())
// 显示内存统计
var memStats runtime.MemStats
runtime.ReadMemStats(&memStats)
fmt.Printf("堆内存使用: %d KB\n", memStats.HeapAlloc/1024)
}运行结果:

三、并发模型
在多核处理器成为主流的今天,并发编程能力成为衡量编程语言实用性的重要指标。不同语言在并发模型的设计上体现了各自对安全性和开发效率的不同取舍。
3.1 Rust:编译期保证的并发安全
Rust通过类型系统的Send和Sync特质来确保并发安全性:Send表示值可以在线程间安全转移所有权,Sync表示值的引用可以安全地在线程间共享。这种编译期检查机制与async/await异步语法相结合,既保证了高性能又杜绝了数据竞争。
use std::thread;
use std::sync::{Arc, Mutex};
use std::time::Duration;
// 线程安全的计数器实现
struct SafeCounter {
value: Mutex<i32>,
}
impl SafeCounter {
fn new() -> Self {
SafeCounter {
value: Mutex::new(0),
}
}
fn increment(&self) {
let mut guard = self.value.lock().unwrap();
*guard += 1;
}
fn get_value(&self) -> i32 {
*self.value.lock().unwrap()
}
}
fn demonstrate_concurrent_safety() {
let counter = Arc::new(SafeCounter::new());
let mut handles = vec![];
// 创建10个线程并发增加计数器
for _ in 0..10 {
let counter_ref = Arc::clone(&counter);
let handle = thread::spawn(move || {
for _ in 0..100 {
counter_ref.increment();
thread::sleep(Duration::from_micros(100));
}
});
handles.push(handle);
}
// 等待所有线程完成
for handle in handles {
handle.join().unwrap();
}
println!("最终计数值: {}", counter.get_value()); // 正确输出1000
}
// 异步并发示例
async fn async_task(id: u32) -> u32 {
tokio::time::sleep(Duration::from_millis(100)).await;
println!("任务 {} 完成", id);
id * 2
}
#[tokio::main]
async fn demonstrate_async_concurrency() {
let tasks: Vec<_> = (0..5).map(|i| async_task(i)).collect();
let results = futures::future::join_all(tasks).await;
println!("所有异步任务结果: {:?}", results);
}
fn main() {
println!("Rust并发安全演示");
demonstrate_concurrent_safety();
// 运行异步示例
demonstrate_async_concurrency();
}运行结果:

3.2 C++:灵活但依赖经验的并发编程
C++通过标准库提供的互斥锁、条件变量、原子操作等底层原语构建并发程序,这种设计提供了极大的灵活性但要求开发者具备丰富的经验来避免竞态条件、死锁等经典问题。C++20引入的协程和jthread等新特性简化了部分并发编程任务,但安全性仍主要依赖开发者的技术水平。
#include <iostream>
#include <thread>
#include <mutex>
#include <vector>
#include <chrono>
#include <future>
#include <atomic>
class CppCounter {
private:
int value = 0;
std::mutex mutex;
public:
void increment() {
std::lock_guard<std::mutex> lock(mutex);
++value;
}
int getValue() {
std::lock_guard<std::mutex> lock(mutex);
return value;
}
};
// 使用原子操作的计数器
class AtomicCounter {
private:
std::atomic<int> value{0};
public:
void increment() {
++value;
}
int getValue() {
return value.load();
}
};
void demonstrate_mutex_concurrency() {
CppCounter counter;
std::vector<std::thread> threads;
std::cout << "C++ Mutex Concurrency Demo" << std::endl;
// 创建并发工作线程
for (int i = 0; i < 10; ++i) {
threads.emplace_back([&counter]() {
for (int j = 0; j < 100; ++j) {
counter.increment();
std::this_thread::sleep_for(std::chrono::microseconds(100));
}
});
}
// 等待所有线程完成
for (auto& thread : threads) {
thread.join();
}
std::cout << "Final counter value: " << counter.getValue() << std::endl;
}
void demonstrate_atomic_concurrency() {
AtomicCounter counter;
std::vector<std::thread> threads;
std::cout << "\nC++ Atomic Concurrency Demo" << std::endl;
// 创建并发工作线程
for (int i = 0; i < 10; ++i) {
threads.emplace_back([&counter]() {
for (int j = 0; j < 100; ++j) {
counter.increment();
std::this_thread::sleep_for(std::chrono::microseconds(100));
}
});
}
// 等待所有线程完成
for (auto& thread : threads) {
thread.join();
}
std::cout << "Final atomic counter value: " << counter.getValue() << std::endl;
}
// 使用std::async的异步编程(替代协程)
int async_computation(int input) {
std::this_thread::sleep_for(std::chrono::milliseconds(100));
return input * 2;
}
void demonstrate_async_programming() {
std::cout << "\nC++ Async Programming Demo" << std::endl;
// 使用std::async进行异步计算
auto future1 = std::async(std::launch::async, async_computation, 10);
auto future2 = std::async(std::launch::async, async_computation, 20);
auto future3 = std::async(std::launch::async, async_computation, 30);
// 获取结果
int result1 = future1.get();
int result2 = future2.get();
int result3 = future3.get();
std::cout << "Async result 1: " << result1 << std::endl;
std::cout << "Async result 2: " << result2 << std::endl;
std::cout << "Async result 3: " << result3 << std::endl;
std::cout << "Total: " << (result1 + result2 + result3) << std::endl;
}
int main() {
demonstrate_mutex_concurrency();
demonstrate_atomic_concurrency();
demonstrate_async_programming();
return 0;
}运行结果:

3.3 Java:企业级的并发工具生态
Java通过synchronized关键字和java.util.concurrent包提供了一套完整的并发编程工具集,内置的锁机制和线程池降低了并发开发的门槛。但Java线程的创建和上下文切换成本较高,在高并发场景下需要精心设计线程池策略。CompletableFuture等异步编程工具功能强大但API相对复杂。
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class JavaConcurrencyDemo {
// 使用synchronized的传统方式
static class SynchronizedCounter {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
// 使用Atomic类的无锁方式
static class AtomicCounter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet();
}
public int getCount() {
return count.get();
}
}
// 使用线程池的现代方式
public static void demonstrateExecutorService() throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(10);
AtomicCounter counter = new AtomicCounter();
int taskCount = 100;
CountDownLatch latch = new CountDownLatch(taskCount);
for (int i = 0; i < taskCount; i++) {
executor.submit(() -> {
counter.increment();
latch.countDown();
});
}
latch.await(); // 等待所有任务完成
executor.shutdown();
System.out.println("Executor service tasks completed, counter value: " + counter.getCount());
}
// 使用CompletableFuture的异步编程
public static CompletableFuture<String> asyncOperation(String input) {
return CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return input.toUpperCase();
});
}
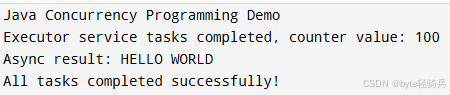
public static void main(String[] args) throws Exception {
System.out.println("Java Concurrency Programming Demo");
demonstrateExecutorService();
// 异步操作示例 - 修复:使用get()等待完成
CompletableFuture<String> future1 = asyncOperation("hello");
CompletableFuture<String> future2 = asyncOperation("world");
// 方法1: 使用allOf和get等待所有任务完成
CompletableFuture<Void> combined = CompletableFuture.allOf(future1, future2);
combined.thenRun(() -> {
try {
System.out.println("Async result: " + future1.get() + " " + future2.get());
} catch (Exception e) {
e.printStackTrace();
}
}).get(); // 添加get()等待thenRun完成
// 方法2: 直接获取结果(替代方案)
// String result1 = future1.get();
// String result2 = future2.get();
// System.out.println("Async result: " + result1 + " " + result2);
System.out.println("All tasks completed successfully!");
}
}运行结果:
3.4 Go:基于CSP理论的轻量级并发
Go语言的并发模型基于Tony Hoare的通信顺序进程理论,通过goroutine和channel实现通过通信来共享内存的哲学。Goroutine是极轻量的执行单元(初始栈仅2KB),支持数十万级别的并发。Channel提供了安全的通信机制,但使用不当仍可能导致死锁或性能问题。
package main
import (
"fmt"
"sync"
"time"
)
// 使用互斥锁的传统方式
type MutexCounter struct {
mu sync.Mutex
value int
}
func (c *MutexCounter) Increment() {
c.mu.Lock()
defer c.mu.Unlock()
c.value++
}
func (c *MutexCounter) Value() int {
c.mu.Lock()
defer c.mu.Unlock()
return c.value
}
// 使用channel的Go风格方式
func channelBasedCounter() {
const workerCount = 10
incrementCh := make(chan bool, 1000) // 缓冲channel
resultCh := make(chan int)
// 启动计数收集器
go func() {
count := 0
for range incrementCh {
count++
}
resultCh <- count
}()
// 启动多个工作goroutine
var wg sync.WaitGroup
for i := 0; i < workerCount; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
for j := 0; j < 100; j++ {
incrementCh <- true
time.Sleep(time.Microsecond * 100)
}
}(i)
}
wg.Wait()
close(incrementCh) // 关闭channel使收集器退出
finalCount := <-resultCh
fmt.Printf("Channel-based计数器结果: %d\n", finalCount)
}
// 使用select处理多个channel
func demonstrateSelect() {
ch1 := make(chan string)
ch2 := make(chan string)
go func() {
time.Sleep(100 * time.Millisecond)
ch1 <- "来自channel 1"
}()
go func() {
time.Sleep(50 * time.Millisecond)
ch2 <- "来自channel 2"
}()
// select会等待多个channel操作
for i := 0; i < 2; i++ {
select {
case msg1 := <-ch1:
fmt.Println("接收:", msg1)
case msg2 := <-ch2:
fmt.Println("接收:", msg2)
}
}
}
func main() {
fmt.Println("Go并发模型演示")
// 互斥锁方式
var counter MutexCounter
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for j := 0; j < 100; j++ {
counter.Increment()
}
}()
}
wg.Wait()
fmt.Printf("Mutex计数器结果: %d\n", counter.Value())
// Channel方式
channelBasedCounter()
// Select多路复用
demonstrateSelect()
}运行结果:

四、开发体验与生态系统
编程语言的实际价值不仅体现在技术特性上,更体现在开发效率、工具链成熟度、社区支持和生态系统完整性等工程化因素上。
4.1 开发工具链对比
| 语言 | 构建工具 | 包管理 | 开发环境 | 调试体验 |
| Rust | Cargo(一体化) | Cargo registry | VSCode + rust-analyzer、IntelliJ Rust | 良好,原生支持 |
| C++ | CMake、Makefile等 | vcpkg、Conan等 | Visual Studio、CLion、VSCode | 成熟但配置复杂 |
| Java | Maven、Gradle | Maven Central | IntelliJ IDEA、Eclipse | 企业级完善支持 |
| Go | go build(内置) | Go Modules | GoLand、VSCode | 简洁快速 |
| Python | setuptools等 | pip、conda | PyCharm、VSCode | 交互式优秀 |
4.2 学习曲线分析
根据开发者社区的普遍反馈,各语言的学习难度和掌握时间存在明显差异:
Python:学习曲线最为平缓,适合编程初学者,通常2-4周可掌握基础
Go:语法简洁明了,概念清晰,1-2个月可达到生产级开发水平
Java:概念体系完整但相对繁杂,需要2-4个月系统学习
JavaScript/TypeScript:入门容易但精通困难,异步编程和生态系统需要长期积累
Rust:学习曲线最陡峭,所有权和生命周期概念需要1-3个月适应期
C++:复杂度极高,语言特性和最佳实践需要数年时间才能真正掌握
4.3 社区活跃度与就业市场
根据2023年的技术社区调查和招聘市场数据分析:
-
JavaScript/TypeScript:Web开发领域绝对主导,社区最活跃,就业机会最多
-
Python:数据科学和机器学习领域快速增长,社区热情高,岗位需求旺盛
-
Java:企业级开发稳定需求,社区成熟规范,就业市场体量巨大
-
Go:云原生和基础设施领域快速增长,社区质量高,薪资水平较好
-
Rust:系统编程和新兴技术领域关注度高,社区技术深度好,岗位数量增长快
-
C++:游戏、嵌入式等专业领域需求稳定,社区经验丰富,高级人才稀缺
五、生态系统与适用场景
不同编程语言经过长期发展,在特定领域形成了各自的生态优势,技术选型需要充分考虑目标应用场景的特点。
5.1 各语言的核心生态优势与典型应用场景
| 语言 | 核心生态优势 | 典型适用场景 | 代表性项目 |
| Rust | 系统工具链完善(Cargo)、异步生态成熟(tokio)、WASM支持优秀、内存安全保证 | 系统编程(操作系统、浏览器引擎)、基础设施工具、WebAssembly应用、区块链开发 | Firefox、Deno、Rust编译器、Solana |
| C++ | 数十年生态积累、硬件控制能力极强、性能优化空间最大、跨平台库丰富 | 游戏引擎开发、高性能计算、嵌入式系统、金融交易系统、桌面应用 | Unreal Engine、Chrome、MySQL、Photoshop |
| Java | 企业级框架成熟稳定(Spring生态)、JVM跨平台性优秀、监控调试工具完善 | 大型企业应用、分布式系统、Android应用、大数据处理 | Hadoop、Android OS、Elasticsearch、Kafka |
| Go | 并发原语简单高效、编译部署便捷、云原生生态完整、标准库实用 | 云原生服务、微服务架构、API网关、命令行工具、网络服务 | Docker、Kubernetes、etcd、Terraform |
| Python | 科学计算库丰富、机器学习生态完整、脚本自动化高效、Web开发快速 | 数据科学与分析、机器学习/AI、Web后端开发、自动化脚本 | TensorFlow、Django、NumPy、Ansible |
| JavaScript/TypeScript | 全栈开发能力、前端生态繁荣、npm包管理庞大、跨平台应用支持 | Web前端开发、Node.js后端、移动跨平台应用、桌面应用 | React、Vue.js、Node.js、Electron |
5.2 场景驱动的技术选型建议
①系统底层与性能敏感场景
-
首选:Rust、C++
-
考量因素:内存安全需求、性能极致要求、硬件控制需求
-
典型用例:操作系统组件、游戏引擎、数据库系统、加密算法实现
②企业级复杂业务系统
-
首选:Java、C#
-
考量因素:团队技术储备、长期维护性、企业集成需求
-
典型用例:银行核心系统、电商平台、大型ERP系统
③云原生与高并发服务
-
首选:Go、Java、Rust
-
考量因素:并发处理规模、部署便捷性、资源效率
-
典型用例:微服务架构、API网关、消息队列、服务网格
④数据科学与人工智能
-
首选:Python
-
考量因素:算法生态完整性、开发迭代速度、团队协作效率
-
典型用例:机器学习模型训练、数据分析平台、科研计算
⑤快速原型与初创项目
-
首选:Python、JavaScript、Go
-
考量因素:开发速度、团队规模、技术债务控制
-
典型用例:MVP产品开发、概念验证、内部工具
六、技术选型的多维度平衡艺术
通过以上四个核心维度的客观分析,我们可以看到每种编程语言都在特定的技术权衡空间中找到了自己的定位:
Rust的核心价值在于填补了内存安全与零成本抽象之间的历史空白,其编译期检查机制为系统级软件提供了新的安全范式。虽然学习曲线相对陡峭,但在对可靠性和性能都有严苛要求的场景下,Rust提供了独特的技术价值。
C++的技术定位仍然是性能极致追求和硬件直接控制的首选,数十年的生态积累和优化经验使其在特定领域具有不可替代性。但需要团队具备深厚的技术积累来规避复杂性和安全风险。
Java的生态优势体现在企业级开发的完整解决方案和人才储备上,JVM的跨平台特性和成熟的工具链使其在大型复杂业务系统中继续保持强大生命力。
Go的设计哲学以简单高效为核心,在并发处理和云原生场景中展现出显著优势,特别适合需要快速开发和高效部署的中等规模分布式系统。
Python的领域特长在于数据科学和快速开发,丰富的库生态系统和简洁的语法使其在特定领域几乎形成垄断地位。
技术选型的本质是在性能要求、开发效率、团队能力、维护成本、生态支持等多个维度间寻找最佳平衡点。Rust并非旨在取代现有语言,而是为开发者提供了一个在安全性和性能之间取得更好平衡的新选项,推动了整个编程语言生态向更安全、更高效的方向持续演进。
在实际项目中,建议采用渐进式的技术采纳策略:对于新项目,基于具体的业务需求和技术约束进行客观评估;对于现有系统,考虑通过FFI互操作或微服务化架构逐步引入新技术栈。最重要的是建立基于数据和事实的技术决策文化,避免盲目追求技术潮流或固守陈旧技术栈,让每个技术选择都服务于实际的业务目标和工程需求。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐


 70
70 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)