为什么词向量(Word Embedding)能表示语义?
词向量通过高维空间映射将语义关系可视化,使机器能理解单词间的关联。不同于传统One-Hot编码,词向量让语义相近的词在空间中的距离更近,并能捕捉复杂的逻辑关系(如"国王-男人+女人=女王")。它通过海量训练抽象出单词的多维度语义特征,使机器不仅能判断相似性,还能进行类比推理。词向量的本质是构建了一个量化语义网络,用空间关系编码单词的"社会关系",让机器突破符
词向量为啥能懂语义?高维空间里的“语言魔法”🧩
做NLP开发的同学肯定都用过Word Embedding(词向量),但你有没有想过:明明只是一串数字,为啥“苹果”和“梨”的向量距离近,“苹果”和“电脑”的距离远?为啥模型能通过词向量搞懂“国王-男人+女人=女王”这种骚操作?其实词向量的核心魔法,就是把“看不见的语义”变成了“看得见的空间关系”,让机器终于不用再当“只会认符号的睁眼瞎”~
一、高维空间映射:给每个词发“专属坐标”🌐
传统NLP处理单词,靠的是One-Hot编码——比如“苹果”是[1,0,0,0],“梨”是[0,1,0,0],“电脑”是[0,0,1,0]。这种方式就像给每个词发“独立身份证”,彼此之间毫无关联,机器根本不知道“苹果”和“梨”都是水果,只知道它们是两个不同的符号。
词向量偏不这么玩!它把每个词都映射到一个高维空间(比如128维、256维),变成一串连续的数字(比如“苹果”=[0.23, 0.56, -0.12,…]),这串数字就是单词的“空间坐标”。关键在于:语义相近的词,坐标离得近;语义无关的词,坐标离得远。
就像现实世界的地图:“北京”和“上海”都是大城市,坐标在地图上是两个相近的“点”;“北京”和“泰山”一个是城市一个是山脉,坐标距离就远。词向量空间也是同理:
- “苹果”“梨”“香蕉”都属于水果,在高维空间里聚成一小团;
- “手机”“电脑”“平板”都是电子设备,聚成另一小团;
- 两团之间的距离,比团内单词的距离远得多。
机器通过计算这些“坐标”的距离(比如余弦距离),就能瞬间判断单词的语义相关性——这就是词向量能“懂语义”的基础:用空间距离量化语义相似度。
二、捕捉语义关系:不只是相似,还能“推理”🔗
词向量的牛掰之处,不只是能判断“像不像”,还能捕捉单词间的“逻辑关系”,支持类比推理。比如经典的“国王-男人+女人=女王”,背后就是词向量的“加减魔法”:
- 词向量中,“国王”和“男人”的差值,代表“男性君主”与“男性”的身份差异;
- 加上“女人”的向量,就相当于把这种身份差异迁移到女性身上,最终得到“女王”的向量。
这背后的逻辑是:词向量不仅编码了“单词本身”,还编码了单词之间的“关系模式”。比如:
- 同义词关系:“开心”和“快乐”的向量几乎重合,差值接近0;
- 上下位词关系:“狗”的向量在“动物”向量的“子空间”里,体现“特殊-一般”的包含关系;
- 因果关系:“下雨”和“潮湿”的向量存在固定差值,体现“原因-结果”的关联。
就像人类学语言:我们不仅知道“猫”和“狗”都是动物,还知道“猫是动物的一种”“下雨会导致潮湿”——词向量把这些隐性的语义关系,变成了可计算的向量运算,让机器也能像人一样“推理”语义。
三、抽象含义理解:跳出“表面符号”,抓住“本质内核”💡
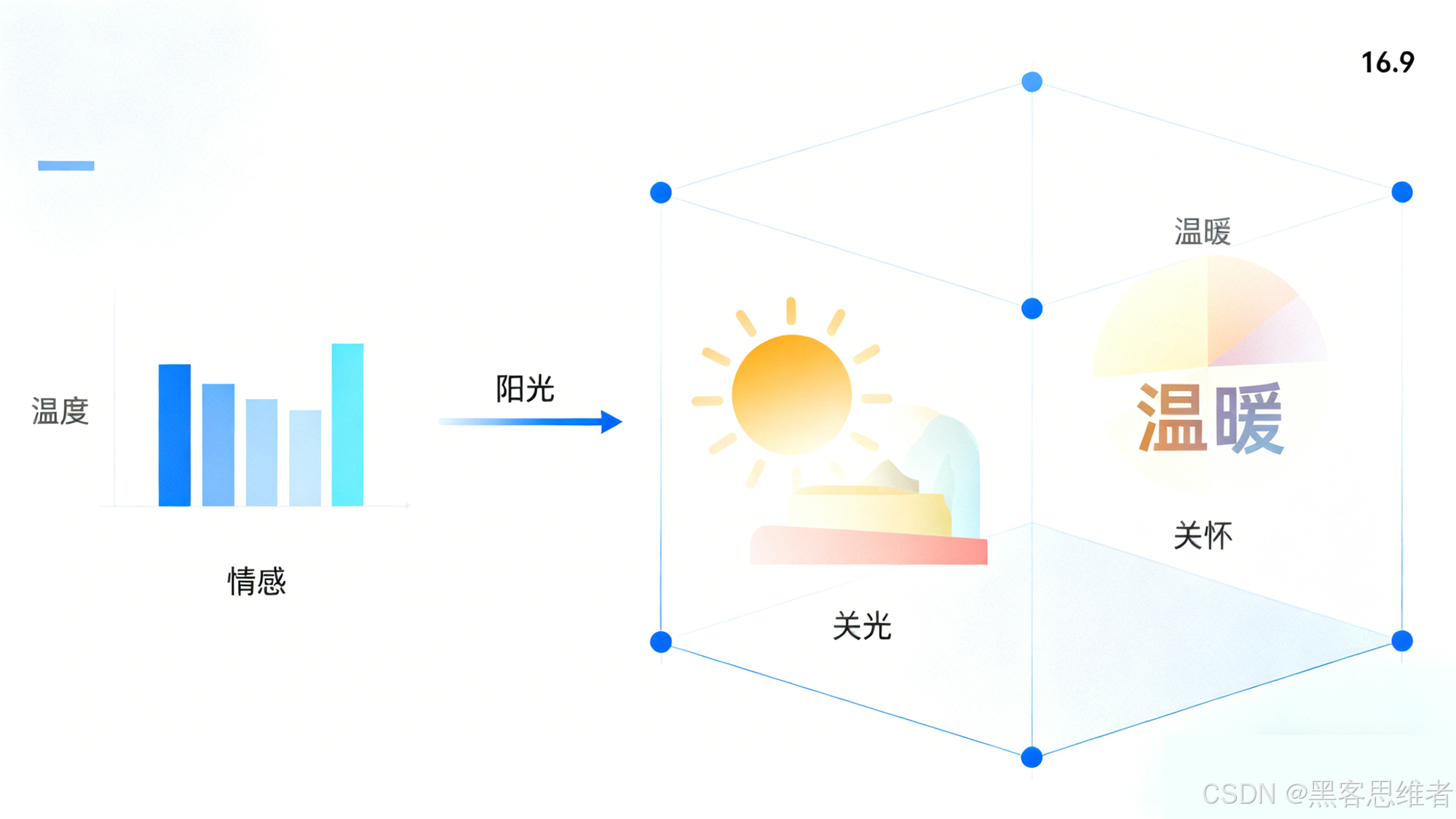
语言的本质是“抽象符号”,比如“温暖”既可以指温度(“温暖的阳光”),也可以指情感(“温暖的关怀”);“打”既可以指动作(“打球”),也可以指人际关系(“打交道”)。机器要理解这些抽象含义,光靠记符号没用,得抓住符号背后的“本质内核”。
词向量正是通过海量文本训练,捕捉到了单词的“抽象语义内核”。比如“温暖”的向量,会同时编码“温度适中”和“情感善意”这两种抽象特征:
- 当它和“阳光”搭配时,模型会激活“温度”相关的特征;
- 当它和“关怀”搭配时,模型会激活“情感”相关的特征。
这就像人类理解单词:我们不会把“温暖”只当成一个孤立的词,而是会联想到它的各种使用场景和抽象含义。词向量通过高维空间的“多维度特征编码”,让机器也能跳出“表面符号”,理解单词的抽象语义——这也是大模型能生成“有温度、有逻辑”文本的基础。
最后:词向量的本质,是“语言的量化世界观”🌍
其实词向量的思路,和人类认识世界的方式异曲同工:我们把世界上的事物分类、关联,形成认知框架;词向量把语言里的单词映射、关联,形成语义框架。
它没有把单词当成孤立的“字符串”,而是当成了“语义网络里的节点”——每个节点的位置,由它和其他所有节点的关系决定。这种“通过关系定义本质”的思路,正是词向量能表示语义的核心。
所以下次再用Word2Vec、BERT的词向量时,别只把它当成一串数字——那背后是机器对语言的“理解”:每个向量都是一个单词的“语义身份证”,既包含了它自己的本质,也记录了它和其他单词的“社会关系”~

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)