扒掉 Runtime 底裤:BoostKit 是如何通过重写 TF 执行流的
宏观架构层:用重写执行流,解决大量小算子带来的调度崩塌。微观算子层:用KDNN和KTFOP替换通用实现,利用 ARM 专有指令集和寄存器特性。硬件适配层:通过 NUMA 亲和性和 Zero Copy 技术,打通 CPU 和内存的任督二脉。对于咱们开发者来说,这个 Repo 绝对是学习“如何为特定硬件定制 AI 框架”的教科书。别再只会然后调参了。真正的技术大牛,都是像这样,敢于拿着手术刀,对着几百
前言:兄弟们,把手里的键盘先放一放。今天咱们不聊那些“三分钟学会TensorFlow”的幼儿园读物,也不整那些“AI赋能未来”的虚头巴脑。BoostKit 提供了一个名为 sra-tensorflow 的补丁。很多人只知道打上它能变快,但不知道为什么。今天我们剥离所有营销话术,直接打开 0001-boostsra-tensorflow.patch,从 C++ 源码层面还原它的加速逻辑。
鲲鹏Tensorflow是基于开源Tensorflow的高性能推理加速扩展,聚焦于搜推广推理场景下的高效执行。通过在图优化、算子、Runtime等方面进行了深度的性能增强,显著提升了模型推理的吞吐量和时延表现,为AI应用提供基于鲲鹏CPU极致性能。
主要特性包括:
- 图优化:识别Embedding常见子图进行融合,减少图执行开销;
- 算子优化:针对核心算子提供鲲鹏亲和实现,结合鲲鹏硬件底层指令集提升计算效率;
- 运行时优化:引入轻量化调度器,提升并发执行效率。
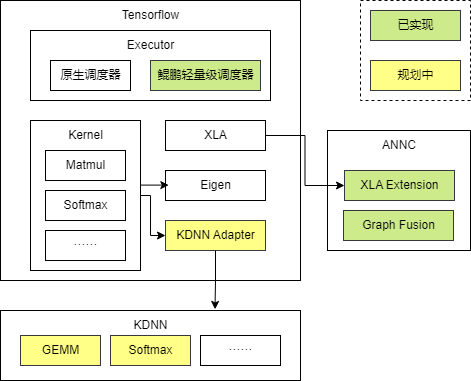
- Executor层:运行时优化。
- Kernel层:自定义算子,基于KDNN提供鲲鹏高性能DNN算子。
- XLA层:基于ANNC提供鲲鹏图编译器。
一、 构建系统的野心
起初我在浏览鲲鹏社区的开源地图时,注意到了 BoostKit/tensorflow 这个仓库,我以为它是TensorFlow的一个全量Fork版本,但点进 GitCode链接 一看,发现这个仓库极其“精简”。
打开仓库(参考截图),你会发现这里并没有成吨的TensorFlow源码。核心文件寥寥无几:
docs/: 文档目录。0001-boostsra-tensorflow.patch: 这是绝对的主角。README.md: 项目介绍。
BoostKit团队采用的是一种非常聪明的补模式。这种方式对开发者非常友好,你不需要去维护一个非官方的TF发行版,只需要在编译原生TensorFlow时,打上这个补丁,就能注入鲲鹏的加速能力。
说实话,刚开始Patch 文件的时候,我心里是犯嘀咕的。咱们混迹 GitHub 这么多年,见多了那种改几行配置参数就敢号称“性能提升50%”的 PPT 项目。但是,当我花了一下午读完 0001-boostsra-tensorflow.patch 里的几千行 C++ diff 之后,得到结论这确实很厉害。
很多所谓的“适配”,无非就是加个编译选项,让代码能在 ARM 上跑起来不报错。但你看一眼 .bazelrc 的改动,就知道事情并不简单。这帮人直接往 Bazel 配置里注入了一套全新的构建逻辑:
# Config setting to build ktfop.
build:ktfop --define=build_with_ktfop=true
build:ktfop --define=build_with_kblas=true
build:ktfop -c opt
# Config setting to build fused_embedding.
build:fused_embedding --define=build_with_fused_embedding=true
看到 ktfop 和 fused_embedding 这两个 flag 了吗?这意味着他们并没有污染原生 TF 的核心库,而是通过 Bazel 的模块化机制,把自己的私货(高性能算子库)像乐高积木一样插了进去。
特别是那个 build_with_kblas=true,懂行的看到这儿就该兴奋了。KBLAS 是华为基于鲲鹏架构优化的基础线性代数子程序库。这说明什么?说明底层的矩阵乘法(GEMM)不再是用通用的 Eigen 库在那硬算,而是直接调用了针对 ARMv8/SVE 指令集调优过的汇编级实现。
这还没开始跑,起跑线就不一样了。
二、Batch Scheduling Executor
如果说算子优化是战术层面的,那 Runtime(运行时)的改造就是战略层面的。
原生 TensorFlow 的 Executor(执行器)设计得非常通用,为了兼容各种设备,它把图里的每个节点(Node)都当作一个独立的任务扔进线程池。这在计算密集型的大算子(比如做 ResNet 训练)时没问题,但在**搜推广(搜索、推荐、广告)**场景下,简直就是灾难。
为什么?因为搜推广模型里有成千上万个极小的算子(Slice, Concat, Cast)。如果每个小算子都去抢线程锁、做上下文切换,CPU 的时间全浪费在调度上了,真正干活的时间没多少。
BoostKit 的兄弟显然深知这一点。在 tensorflow/core/common_runtime/executor.cc 里,我发现了一个完全新增的类:BatchSchedulingExecutorState。
注意看这段新增的逻辑:
// tensorflow/core/common_runtime/executor.ccif (args.executor_policy == ExecutorPolicy::USE_BATCH_SCHEDULING_EXECUTOR) {
return new BatchSchedulingExecutorState<PropagatorStateType>(
args, immutable_state, kernel_stats);
}
他们通过一个 executor_policy 标志位,把原生执行器给“偷梁换柱”了。
最骚的操作在 ScheduleReady 函数里。原生 TF 是把准备好的节点一股脑塞进队列等待调度,而 BoostKit 改成了这样:
// tensorflow/core/common_runtime/executor.cc (Patch片段)template <class PropagatorStateType>void BatchSchedulingExecutorState<PropagatorStateType>::ScheduleReady(
TaggedNodeSeq* ready, TaggedNodeReadyQueue* inline_ready) {
if (inline_ready == nullptr) {
// 咱们看这里:RunTask 里面套了一个 lambdathis->RunTask([this, ready = std::move(*ready), scheduled_nsec]() {
for (auto& tagged_node : ready) {
this->Process(tagged_node, scheduled_nsec);
}
});
}
// ...
}
看不懂的可能觉得这不就是个循环吗?大错特错!
这里的核心在于 inline_ready 的处理。它强制将一组已经 Ready 的节点,在同一个线程内,通过一个闭包(Closure)串行执行完毕。
这招真的太狠了。它直接消灭了线程间的切换开销(Context Switch Overhead)和锁竞争(Mutex Contention)。这就好比本来你要去十个窗口办业务,得排十次队;现在 VIP 窗口开了,你坐进去,一次性把十个章全盖了。
对于 CPU 的指令缓存(I-Cache)来说,这种连续执行简直是亲爹级的待遇。在鲲鹏这种多核架构上,这种 Runtime 级别的优化,比你优化一两个算子要猛得多。
三、 KDNN 的深度入侵
聊完调度,咱们来看算子。AI 推理的半壁江山都是矩阵乘法(MatMul)。
在 tensorflow/core/kernels/matmul_op_fused.cc 文件里,我看到了一段极为暴力的“劫持”代码:
// tensorflow/core/kernels/matmul_op_fused.cc#if defined(ENABLE_KDNN)// 检查一:KDNN 开关开了没?// 检查二:数据类型是不是 float?(浮点运算才是大头)// 检查三:是不是不需要转置 A 矩阵?if (IsKDNNEnabled() && std::is_same<T, float>::value && kdnn_enable_fusion && !transpose_a_) {
// 满足条件?走你!直接调用鲲鹏的实现
kdnnFusedGemm(context, a, b, output, fusion_relu, transpose_a_, transpose_b_);
return;
}
#endif
原生 TF 的 Eigen 实现直接被短路了。
你可能会问,这个 kdnnFusedGemm 是个啥?咱们顺藤摸瓜,找到 third_party/KDNN/kdnn_adapter.h。
这是一个极其标准的适配器模式(Adapter Pattern)。TF 的 Tensor 数据结构和 KDNN 库需要的数据结构肯定是不一样的。如果在这里做一次内存拷贝(Memcpy),那就算算子算得再快,性能也被拷贝拖死了。
看看 BoostKit 是怎么做的:
// third_party/KDNN/kdnn_adapter.hconst float *A = a.flat<float>().data(); // 直接拿指针!const float *B = b.flat<float>().data();
float *C = out->flat<float>().data();
// ... 省略中间配置代码 ...// 构造 KDNN 的 TensorInfo,传入维度和布局,零拷贝!const KDNN::TensorInfo srcInfo = {{m, k}, KDNN::Element::TypeT::F32, KDNN::Layout::AB};
// 直接让 KDNN 在原指针上跑KDNN::Gemm gemm(srcInfo, weightsInfo, dstInfo, biasInfo, attr);
gemm.Run(A, B, C, Bias, po_ptrs);
Zero Copy(零拷贝)。他们直接透传了底层的数据指针。
而且这里还有一个细节:fusion_relu。如果计算图里是 MatMul + BiasAdd + Relu,原生 TF 可能要跑三个 Kernel,读写三次内存。而这里通过 KDNN::PostOps,直接把 Relu 融合进了 Gemm 的计算尾部。
这意味着什么?意味着数据从内存加载到 CPU 寄存器后,算完乘法紧接着就算加法和激活,中间不用把结果写回内存。在 Memory Wall(内存墙)日益严重的今天,这种算子融合就是性能提升的王道。
四、 稀疏算子
是不是所有算子都要用 KDNN 加速?很多新手容易犯的错误就是“为了用而用”,不管数据规模大小,全扔给加速库。
但我在 tensorflow/core/kernels/sparse_tensor_dense_matmul_op.cc 里看到了一段非常有意思的代码:
// tensorflow/core/kernels/sparse_tensor_dense_matmul_op.ccif (rhs_right < kNumVectorize) {
// Disable vectorization if the RHS of output is too small// ... 走老路 ...
} else {
// 只有当维度足够大时,才走 KDNN 向量化路径
kdnnSparseMatmul<Tindices>(...);
}
这里的 kNumVectorize 定义为 32。
这段逻辑让我非常想给写代码的哥们点个赞。为什么?因为启动一个高度优化的向量化 Kernel 或者是调用第三方库是有 Overhead(开销)的。如果你的矩阵非常窄(比如只有几列),用 AVX/NEON 指令集的收益甚至覆盖不了启动成本。
这时候果断切回标量代码,才是真正的性能调优。这叫懂得取舍。
五、 Embedding 查找的终极形态
做过推荐系统的兄弟都知道,Embedding Lookup 是绝对的性能瓶颈。TF 原生的处理方式非常“学院派”:先搞个 StringToTensor,再 StringHash,再 Mod,最后 Gather。这一套下来,图里多了四五个节点,内存倒腾好几遍。
BoostKit 直接摊牌了,不装了。他们在 tensorflow/core/kernels/fused_embedding 下搞了个新算子:KPLookupEmbeddingByHash。
看这名字:Fused(融合)、ByHash(直接哈希)。
打开 lookup_embedding_by_hash.h,核心逻辑简单得令人发指,但也快得令人发指:
// tensorflow/core/kernels/fused_embedding/lookup_embedding_by_hash.hstatic inline int RegularLookup(...) {
// 遍历 Batchfor (int64_t i = 0; i < batch_size; ++i) {
if (lookup_length[i] != 0) {
// 1. 原地计算 Hash (FarmHash)uint64_t hash_value = ::util::Fingerprint64((char *)(lookup_embedding[i]), lookup_length[i]);
// 2. 取模拿到索引uint64_t x = hash_value % embedding_size_u64;
// 3. 内存拷贝 (memcpy 的变体)for (uint64_t j = 0; j < embedding_dims; ++j) {
output[j] = embedding_table[x * embedding_dims + j];
}
output += embedding_dims_u64;
}
}
return OK;
}
它把 TF 原本需要跨越多个算子、多次内存分配的过程,压缩成了一个极其紧凑的 C++ for 循环。
在这个循环里,CPU 的分支预测(Branch Prediction)能工作到极致,L1 Cache 也会非常舒服。对于动辄几百 GB 的 Embedding 表查询来说,这种优化带来的吞吐量提升是成倍的。
六、 NUMA 亲和性与线程池
鲲鹏 920 这种服务器级 CPU,核心数多(比如 64 核、128 核),而且是典型的 NUMA(Non-Uniform Memory Access)架构。
在 x86 上跑得欢的程序,到了这种多核怪兽上,往往会因为跨 Socket 内存访问而性能崩盘。这就好比你在 1 楼干活,非要去 20 楼的仓库拿工具,腿都跑断了。
我检查了 tensorflow/core/platform/numa.h,发现 Patch 增加了 ThreadAffinity 枚举:
enum ThreadAffinity {
OFF,
ORDER,
INTERVAL
};
并且在 third_party/KDNN/kdnn_threadpool.h 里,他们没有直接用 TF 的线程池,而是封装了一个 KDNNThreadPool。
这背后的逻辑很清晰:他们在试图控制线程的物理位置。通过设置亲和性,强制计算线程“钉”在离内存最近的那个 CPU Die 上。
在 tensorflow/core/common_runtime/direct_session.cc 里,也能看到对 use_batch_scheduling_executor_ 的初始化。配合前面提到的 Runtime 优化,这实际上是在构建一个**对硬件拓扑有感知(Topology-Aware)**的调度系统。
七、 总结
BoostKit 的这个 Patch,给我展示了三个层次的优化:
- 宏观架构层:用
BatchScheduling重写执行流,解决大量小算子带来的调度崩塌。 - 微观算子层:用
KDNN和KTFOP替换通用实现,利用 ARM 专有指令集和寄存器特性。 - 硬件适配层:通过 NUMA 亲和性和 Zero Copy 技术,打通 CPU 和内存的任督二脉。
对于咱们开发者来说,这个 Repo 绝对是学习“如何为特定硬件定制 AI 框架”的教科书。
别再只会 import tensorflow as tf 然后调参了。真正的技术大牛,都是像这样,敢于拿着手术刀,对着几百万行代码的庞然大物,直接动手去做,所以咱们也抓紧学起来吧,注明:昇腾PAE案例库对本文写作亦有帮助。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)