C语言基础语法详解(有漫画进行辅助理解)
本文介绍了C语言的基础语法环境和数据运算。主要内容包括:注释的使用规则和注意事项;标识符命名规范;三种常量机制(字面量、宏常量、const常量)及其区别;计算机进制表示及存储规则(原码、反码、补码、大小端);基本数据类型及其内存占用;scanf函数的使用注意事项;算术运算的类型转换规则。文中通过代码示例展示了各种语法特性的实际应用,并强调了常见错误和最佳实践。
C 语言
第一部分:基础语法环境
1. 注释 (Comments)
详细讲解:
注释是写给程序员自己或他人阅读的说明文字,编译器在预处理阶段会完全忽略或移除它们。C 语言原生只支持多行注释,单行注释是 C99 标准从 C++ 借鉴而来。
底层原理:预处理器在编译前直接删除所有注释内容,因此注释不会占用最终可执行文件的任何空间,但会影响源码可读性。
注意事项:
- 多行注释不支持嵌套(
/* /* */ */会提前结束第一个注释导致语法错误)。 - 过度注释反而降低可读性,应注释“为什么”而不是“做什么”。
#include <stdio.h>
int main() {
// 单行注释:C99 以后支持
printf("Hello\n");
/* 多行注释:
可以写很长的说明
常用于临时注释掉一大段代码 */
/*
* 推荐这种带 * 的风格,便于阅读
*/
return 0;
}

2. 标识符与命名规则
详细讲解:
标识符是程序中用来标识变量、函数、结构体、宏等实体的名字。C 语言对标识符的命名有严格规则,违反会直接导致编译错误。
底层原理:编译器在词法分析阶段检查标识符是否合法,并将其映射到符号表中。关键字被保留,不能用作标识符。
注意事项:
- 区分大小写:
age和Age是两个不同的标识符。 - 以
_或大写字母开头的标识符常被系统库或宏占用,普通变量建议用小写 + 下划线风格(如user_count)。 - 长度理论上无限制,但实际前 31 个字符必须唯一(老标准限制)。
int my_age = 25; // 推荐风格
int _internal_var = 0; // 系统常用,慎用
int StudentID; // 驼峰风格(部分项目使用)
// 以下会报错
// int 2player = 1; // 不能以数字开头
// int int = 10; // 关键字不能用作标识符

3. 常量 (Constants)
详细讲解:
常量是在程序运行期间值不可改变的数据。C 语言提供了三种常量机制,各有适用场景。
底层原理:
- 字面常量直接嵌入指令中(如
mov eax, 100)。 #define宏常量在预处理阶段进行文本替换,无类型、无内存。const修饰的变量在编译期有类型检查,运行时占用内存(只读)。
注意事项:- 宏常量无类型检查,容易出错(如
#define PI 3.14用于整数计算会隐式截断)。 const在 C 中不是真正的常量(不能用于数组长度定义,除非用 C99 的 VLA),推荐宏或enum替代。
#include <stdio.h>
#define MAX_USERS 100 // 宏常量:预处理替换
#define PI 3.14159
int main() {
const int LIMIT = 500; // const 常量:有类型、有地址、只读
// LIMIT = 600; // 错误:赋值给只读变量
int arr[MAX_USERS]; // 宏可以用作数组长度
// int arr2[LIMIT]; // C89 报错,C99 支持可变长数组(VLA)
printf("PI = %f\n", PI);
return 0;
}

4. 计算机进制 (Number Systems)
详细讲解:
计算机底层使用二进制存储数据,C 语言支持多种进制字面量方便程序员阅读和调试。
底层原理:无论哪种进制写法,最终在内存中都是二进制补码形式存储。编译器在编译时完成转换。
注意事项:
- 二进制字面量
0b...是 GCC/Clang 扩展,非 ISO C 标准,但现代编译器普遍支持。 - 八进制常用于 Unix 文件权限,十六进制常用于内存地址和位操作。
#include <stdio.h>
int main() {
int a = 10; // 十进制
int b = 012; // 八进制 → 10
int c = 0xA; // 十六进制 → 10
int d = 0b1010; // 二进制(GCC扩展) → 10
printf("%d %d %d %d\n", a, b, c, d); // 全都输出 10
return 0;
}

5. 计算机存储规则(原码、反码、补码、大小端)
详细讲解:
有符号整数在计算机中以补码形式存储,这是为了让加法器统一处理加减法(减法变成加负数的补码)。
转换规则(以 8 位为例):
- 正数:原码 = 反码 = 补码
- 负数:原码 → 反码(符号位不变,其余取反) → 补码(反码 +1)
大小端:多字节数据在内存中的存储顺序。 - 小端(Little Endian):低字节存低地址(x86、ARM 主流)。
- 大端(Big Endian):高字节存低地址(网络协议常用)。
#include <stdio.h>
int main() {
int num = -1; // 补码全是 1
unsigned int u = num; // 无符号解读:最大值 4294967295 (32位)
printf("%u\n", u);
// 判断大小端
int x = 0x12345678;
char *p = (char*)&x;
if (*p == 0x78) printf("小端\n");
else printf("大端\n");
return 0;
}

第二部分:数据与运算
6. 数据类型
详细讲解:
C 语言是强类型语言,每种数据类型占用固定字节并决定取值范围和运算行为。实际大小与编译器和平台相关(sizeof 可查询)。
底层原理:类型决定了内存解释方式(如 float 的 IEEE 754 格式)。
注意事项:
char是否有符号取决于实现(可能 -128~127 或 0~255)。- 建议显式使用
unsigned或signed避免歧义。 long在 32 位和 64 位系统大小可能不同,推荐用int32_t、int64_t(需<stdint.h>)固定宽度。
#include <stdio.h>
int main() {
printf("char: %zu 字节\n", sizeof(char));
printf("int: %zu 字节\n", sizeof(int));
printf("long: %zu 字节\n", sizeof(long));
printf("double: %zu 字节\n", sizeof(double));
return 0;
}

7. 键盘录入 (scanf)
详细讲解:scanf 从标准输入(键盘)读取格式化数据,写入指定变量的内存地址。
底层原理:它从输入缓冲区逐字符解析,遇到空格、换行、分隔符停止当前字段。
常见坑:
- 忘记加
&(字符串数组除外)。 - 输入数字后回车留下的
\n会被后续%c误读。 %s不读取空格,遇到空格停止。
#include <stdio.h>
int main() {
int age;
char grade;
char name[20];
printf("请输入姓名 年龄 成绩等级(如 Tom 20 A): ");
scanf("%s %d %c", name, &age, &grade); // 注意 %c 前可能有残留换行
// 更安全的做法:先读取整行再解析,或用 getchar() 吃掉换行
printf("姓名:%s 年龄:%d 成绩:%c\n", name, age, grade);
return 0;
}

8. 算术运算符与类型转换
详细讲解:
算术运算遵循“提升”规则:表达式中所有操作数会自动转换为最高精度类型再运算。
底层原理:整数除法向零截断(C99 前为实现定义)。
注意事项:
- 避免整数除法丢失精度,先转换再除。
- 强制转换优先级高于多数运算符。
#include <stdio.h>
int main() {
int a = 5, b = 2;
printf("%d\n", a / b); // 2 (整数除法)
printf("%.2f\n", (double)a / b); // 2.50
double d = 3.14;
int x = (int)d; // 强制转换:3
printf("%d\n", x);
return 0;
}

第二部分:数据与运算
9. 字符运算
详细讲解:
C 语言中 char 类型本质上是 1 字节的整数(有符号或无符号取决于编译器实现),其值对应 ASCII 码表。因此字符可以直接参与算术运算,常用于大小写转换、加密等场景。
底层原理:字符在内存中以整数形式存储,'A' 的值是 65,'a' 是 97,相差 32。运算时会自动提升为 int 进行计算。
注意事项:
- 不同系统的 ASCII 扩展可能不同(中文系统可能有扩展)。
- 超出
char范围时会溢出(有符号 char 可能从 127 回到 -128)。
#include <stdio.h>
int main() {
char c = 'A';
printf("ASCII 值: %d\n", c); // 65
printf("小写: %c\n", c + 32); // 'a'
printf("下一个字符: %c\n", c + 1); // 'B'
char digit = '5';
int num = digit - '0'; // 常用技巧:字符转数字
printf("数字值: %d\n", num); // 5
return 0;
}

10. 自增自减运算符(++ 和 --)
详细讲解:
自增自减是单目运算符,有前置和后置两种形式,区别在于返回值和修改时机。
底层原理:编译器会生成不同的指令序列。后置版本通常需要临时变量保存旧值。
注意事项:
- 不要在同一表达式中对同一变量多次使用自增自减(如
i = i++ + ++i;是未定义行为)。 - 前置版本效率略高(无临时变量)。
#include <stdio.h>
int main() {
int a = 10;
printf("后置: %d\n", a++); // 输出 10,然后 a 变为 11
printf("当前 a: %d\n", a); // 11
printf("前置: %d\n", ++a); // a 先变为 12,然后输出 12
printf("当前 a: %d\n", a); // 12
return 0;
}

11. 逻辑、关系、三元、逗号运算符及优先级
详细讲解:
这些运算符用于条件判断和表达式组合。逻辑运算有短路特性,三元是唯一的三目运算符,逗号保证求值顺序。
底层原理:
- 逻辑短路:编译器优化,若左侧已确定结果,右侧不求值(可用于避免空指针等)。
- 三元运算符返回的是值(lvalue 情况复杂,慎用)。
- 逗号运算符优先级最低,常用于 for 循环初始化和步进。
注意事项:优先级记住“算术 > 关系 > 逻辑 > 赋值”,括号优先。
#include <stdio.h>
int main() {
int x = 0, y = 5;
if (x && y++) { // 短路:x 为 0,y++ 不执行
printf("不会执行\n");
}
printf("y = %d\n", y); // 仍为 5
int max = (x > y) ? x : y; // 三元
printf("max = %d\n", max); // 5
int z = (x = 1, y = 2, x + y); // 逗号表达式值为最后一个
printf("z = %d\n", z); // 3
return 0;
}

运算符优先级简表(高到低关键部分):
| 优先级 | 运算符 | 说明 |
|---|---|---|
| 1 | () [] . -> | 括号、数组、下标 |
| 2 | ! ~ ++ – (类型) * & | 单目运算符 |
| 3 | * / % | 乘除模 |
| 4 | + - | 加减 |
| 5 | << >> | 移位 |
| 6 | < <= > >= | 关系 |
| 7 | == != | 相等 |
| 8 | & ^ | | |
| 9 | && || | 逻辑 |
| 10 | ?: | 三元 |
| 11 | = += -= 等 | 赋值 |
| 12 | , | 逗号(最低) |
第三部分:流程控制
12. 判断结构(if-else 和 switch)
详细讲解:if 用于条件分支,switch 用于多分支等值判断,更高效且可读。
底层原理:switch 在 case 值连续时编译器可能生成跳转表(jump table),效率高于多个 if。
注意事项:
switch中忘记break会导致 case 穿透(fall through)。case标签必须是编译期常量。
#include <stdio.h>
int main() {
int score = 85;
if (score >= 90) {
printf("优秀\n");
} else if (score >= 60) {
printf("及格\n");
} else {
printf("不及格\n");
}
int day = 3;
switch (day) {
case 1: printf("星期一\n"); break;
case 2: printf("星期二\n"); break;
case 3: printf("星期三\n"); // 故意漏 break 演示穿透
case 4: printf("星期四\n"); break;
default: printf("无效\n");
}
// 输出:星期三 星期四
return 0;
}

13. 循环结构与 break、continue、goto
详细讲解:
C 提供 while、do-while、for 三种循环。break 跳出循环,continue 跳过本次剩余代码,goto 无条件跳转。
底层原理:所有循环最终编译为条件跳转指令。goto 破坏结构化编程,现代代码极少使用。
注意事项:
do-while至少执行一次。goto只建议用于多层嵌套循环的统一错误处理和资源清理。
- for 循环
for (int i = 1; i <= 5; i++) {
printf("%d ", i);
printf("\n");
}
- while 循环
while (i <= 5) {
printf("%d ", i);
printf("\n");
i++;
}
- do-while 循环
while (i <= 5) {
printf("%d ", i);
printf("\n");
i++;
}
- 循环控制
#include <stdio.h>
int main() {
// for 循环
for (int i = 1; i <= 5; i++) {
if (i == 3) continue; // 跳过 3
if (i == 5) break; // 提前结束
printf("%d ", i);
}
printf("\n"); // 输出 1 2 4
// goto 示例(错误处理)
FILE *fp = fopen("nonexist.txt", "r");
if (fp == NULL) goto error;
// ... 正常处理文件
error:
printf("打开文件失败,进行清理\n");
return 0;
}

第四部分:函数与内存核心
14. 函数(有参/无参、有返回/无返回)
详细讲解:
函数是代码复用的基本单位。C 是严格的值传递语言,但数组参数会退化为指针。
底层原理:调用函数时通过栈传递参数和返回地址(调用约定如 cdecl、stdcall)。
注意事项:
- 函数内修改普通形参不影响实参。
- 数组形参写成
int arr[]实际等价于int *arr。 - 建议大结构体用指针传递避免拷贝开销。
#include <stdio.h>
// 无参无返回
void sayHello() {
printf("Hello\n");
}
// 有参无返回
void addAndPrint(int a, int b) {
printf("%d + %d = %d\n", a, b, a + b);
}
// 有返回
int max(int a, int b) {
return a > b ? a : b;
}
int main() {
sayHello();
addAndPrint(10, 20);
printf("较大值: %d\n", max(15, 25));
return 0;
}

15. 随机数生成
详细讲解:
C 标准库提供 rand() 生成伪随机数,需要用 srand() 设置种子。
底层原理:rand() 使用线性同余算法,周期有限。种子相同则序列相同。
注意事项:常用 time(NULL) 作为种子实现“每次运行不同”。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main() {
srand((unsigned int)time(NULL)); // 设置种子
for (int i = 0; i < 8; i++) {
int r = rand() % 100; // 0~99
printf("%d ", r);
}
printf("\n");
return 0;
}

16. 内存地址与基本指针
详细讲解:
指针是保存变量地址的变量。通过 & 取地址,* 解引用。
底层原理:地址是内存的整数编号(32/64 位对应 4/8 字节指针)。
注意事项:指针类型决定解引用时读取多少字节。
#include <stdio.h>
int main() {
int a = 100;
int *p = &a; // p 保存 a 的地址
printf("a 的值: %d\n", a);
printf("a 的地址: %p\n", &a);
printf("p 保存的地址: %p\n", p);
printf("通过 p 取值: %d\n", *p);
*p = 200; // 修改 a
printf("修改后 a: %d\n", a); // 200
return 0;
}

17. 野指针、空指针与高级指针
详细讲解:
- 野指针:指向无效/已释放内存,解引用会导致崩溃。
- 空指针:
NULL,安全哨兵值。 - 二级指针:指向指针的指针,常用于修改指针本身或二维数组。
底层原理:所有指针大小相同(平台决定),区别仅在类型检查。
#include <stdio.h>
#include <stdlib.h>
int main() {
int *wild; // 未初始化 → 野指针,危险!
int *null_p = NULL; // 空指针,安全
if (null_p != NULL) {
printf("%d\n", *null_p); // 不会执行
}
// 二级指针
int a = 10;
int *p = &a;
int **pp = &p;
printf("通过二级指针取值: %d\n", **pp); // 10
**pp = 99;
printf("修改后 a: %d\n", a); // 99
// 指针数组
int x = 1, y = 2, z = 3;
int *arr_p[] = {&x, &y, &z};
printf("指针数组第二个元素: %d\n", *arr_p[1]); // 2
// 数组指针
int matrix[2][3] = {{1,2,3}, {4,5,6}};
int (*p_matrix)[3] = matrix; // 指向含3个int的数组
printf("数组指针访问: %d\n", p_matrix[1][2]); // 6
// 函数指针
int add(int a, int b) { return a + b; }
int (*func_p)(int, int) = add;
printf("函数指针调用: %d\n", func_p(5, 7)); // 12
return 0;
}

18. 数组与指针遍历
详细讲解:
数组名在多数情况下退化为指向首元素的指针,arr[i] 等价于 *(arr + i)。
底层原理:指针加法会自动乘以元素大小(指针算术)。
#include <stdio.h>
int main() {
int arr[] = {10, 20, 30, 40};
int *p = arr;
// 三种遍历方式
for (int i = 0; i < 4; i++) {
printf("下标法: %d\n", arr[i]);
}
for (int i = 0; i < 4; i++) {
printf("偏移法: %d\n", *(p + i));
}
for (; p < arr + 4; p++) { // 指针移动法(最灵活)
printf("移动法: %d\n", *p);
}
return 0;
}

第五部分:复杂数据结构
19. 字符串与字符数组
详细讲解:
C 无内置字符串类型,字符串是以 \0 结尾的字符数组。
底层原理:字符串字面量存储在只读数据段,指向它的指针不可修改内容。
注意事项:
char str[] = "hello";可修改。char *str = "hello";指向常量区,修改会导致段错误。
#include <stdio.h>
#include <string.h>
int main() {
char str1[] = "Hello"; // 栈上,可修改
char *str2 = "World"; // 常量区,不可修改
str1[0] = 'X'; // 合法 → "Xello"
// str2[0] = 'Y'; // 运行时崩溃!
printf("长度: %zu\n", strlen(str1));
strcat(str1, " World"); // 拼接(注意空间足够)
printf("%s\n", str1);
return 0;
}

20. 结构体(struct)
详细讲解:
结构体是将不同类型数据组合成一个自定义类型的机制。支持嵌套、typedef、指针传递。
底层原理:内存对齐为了 CPU 高效访问(通常按最大成员或 4/8 字节对齐)。
注意事项:
- 用
->访问指针成员更简洁。 - 传递大结构体时用指针避免拷贝。
#include <stdio.h>
#include <string.h>
typedef struct {
int id;
char name[20];
float score;
} Student;
void printStudent(Student *s) { // 指针传递
printf("ID: %d, Name: %s, Score: %.1f\n", s->id, s->name, s->score);
}
int main() {
Student s1 = {1, "张三", 95.5};
printStudent(&s1);
// 嵌套结构体
typedef struct {
int year, month, day;
} Date;
typedef struct {
char name[20];
Date birthday;
} Person;
Person p = {"李四", {2000, 5, 1}};
printf("%s 生日: %d-%d-%d\n", p.name, p.birthday.year, p.birthday.month, p.birthday.day);
// 内存对齐演示
struct Align {
char a; // 1
int b; // 4,需要补齐 3 字节
short c; // 2
};
printf("结构体大小: %zu\n", sizeof(struct Align)); // 通常 12
return 0;
}

21. 共用体(union)及其与结构体的区别
详细讲解:
共用体所有成员共享同一块内存,适合节省空间或不同类型解释同一数据。
底层原理:大小等于最大成员(加对齐),修改一个成员会覆盖其他。
区别对比:
| 项目 | struct | union |
|---|---|---|
| 内存布局 | 每个成员独立连续分配 | 所有成员从同一地址开始 |
| 大小 | 所有成员大小之和 + 对齐填充 | 最大成员大小 + 对齐填充 |
| 成员访问 | 可同时访问所有成员 | 同一时刻只有一个成员有效 |
| 典型用途 | 表示复合数据(如学生信息) | 类型双关、节省空间、大小端判断 |
#include <stdio.h>
union Data {
int i;
float f;
char c;
};
int main() {
union Data d;
d.i = 65;
printf("作为字符: %c\n", d.c); // 'A'(小端机器)
printf("共用体大小: %zu\n", sizeof(d)); // 通常 4
// 大小端判断
d.i = 0x00000001;
if (d.c == 1) printf("小端\n");
else printf("大端\n");
return 0;
}

第六部分:动态内存与文件操作
22. 动态内存分配(malloc、calloc、realloc)
详细讲解:
动态内存从堆(heap)分配,生命周期由程序员控制。
底层原理:操作系统维护空闲块链表,malloc 寻找合适块。
注意事项:
- 分配失败返回 NULL,必须检查。
- 每次 malloc 对应一次 free,避免内存泄漏。
- free 后立即置 NULL 防野指针。
#include <stdio.h>
#include <stdlib.h>
int main() {
// malloc:分配但不初始化
int *arr1 = (int*)malloc(5 * sizeof(int));
if (arr1 == NULL) {
printf("分配失败\n");
return 1;
}
for (int i = 0; i < 5; i++) arr1[i] = i + 1;
// calloc:分配并清零
int *arr2 = (int*)calloc(5, sizeof(int));
// realloc:扩容(可能移动内存)
arr1 = (int*)realloc(arr1, 10 * sizeof(int));
if (arr1 == NULL) {
printf("扩容失败\n");
return 1;
}
// 使用完必须释放
free(arr1);
free(arr2);
arr1 = arr2 = NULL; // 防止野指针
return 0;
}

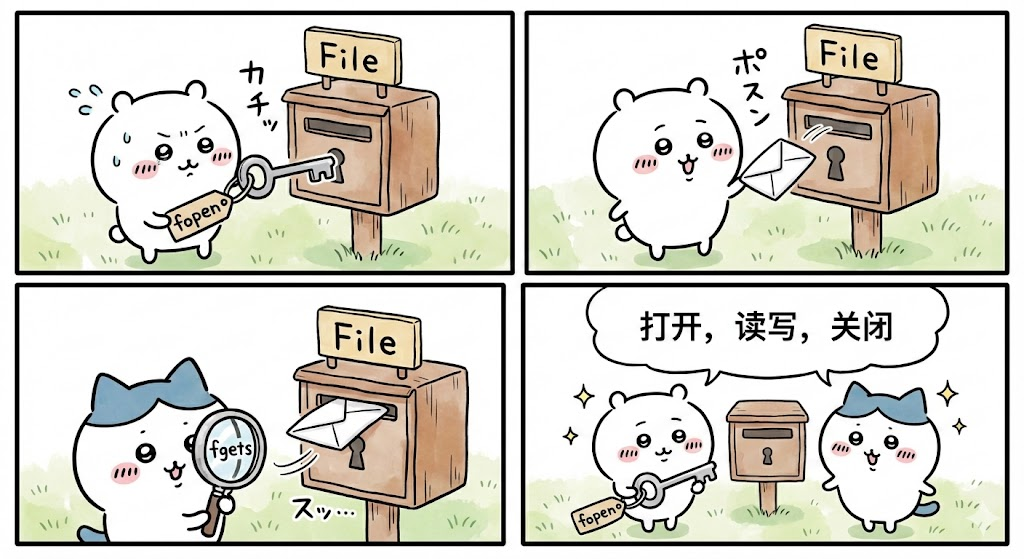
23. 文件操作
详细讲解:
C 通过 FILE* 流操作文件,支持文本和二进制模式。
底层原理:操作系统提供文件描述符,标准库缓冲数据提高效率。
注意事项:
- 每次打开必须关闭(
fclose)。 - 写操作后建议
fflush刷新缓冲区。 - 检查 fopen 返回值。
#include <stdio.h>
int main() {
// 写文件
FILE *fp = fopen("demo.txt", "w");
if (fp == NULL) {
printf("打开失败\n");
return 1;
}
fprintf(fp, "Hello C File\n");
fprintf(fp, "数字: %d %.2f\n", 100, 3.14);
fclose(fp);
// 读文件
fp = fopen("demo.txt", "r");
if (fp == NULL) return 1;
char line[100];
while (fgets(line, sizeof(line), fp) != NULL) {
printf("读取: %s", line);
}
fclose(fp);
// 二进制读写示例
int nums[] = {1, 2, 3};
fp = fopen("binary.dat", "wb");
fwrite(nums, sizeof(int), 3, fp);
fclose(fp);
return 0;
}

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐



 80
80 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)