2026 第一枪:字节提出的超连接,被 DeepSeek 救活了
2026 第一枪:字节提出的超连接,被 DeepSeek 救活了
新年第一天,被 DeepSeek 新论文刷屏了!
DeepSeek 的老传统:每逢节假日,总得做点啥。
这次元旦,是一篇论文。
2025 年 12 月 31 日,DeepSeek 在 arXiv 上发表了一篇技术论文。
标题是「mHC: Manifold-Constrained Hyper-Connections」,翻译过来叫「流形约束超连接」。
论文的核心贡献是提出了一种新的网络连接方式「mHC」,解决了此前「超连接」(Hyper-Connections)在大规模训练时不稳定的问题。
划重点,DeepSeek 创始人梁文锋也在作者名单里。

DeepSeek 元旦发布的 mHC 论文。
「超连接」本身不是 DeepSeek 的发明,是字节豆包的。
2024 年 9 月,字节豆包大模型团队首次提出了「超连接」,作为「残差连接」的替代方案,论文后来被 ICLR 2025 接收。

字节豆包团队的超连接论文,已被 ICLR 2025 收录。
那么,残差连接是什么?
训练深度神经网络有个老问题:网络层数一多,信息从前往后传的时候会逐渐失真,到最后几层几乎学不到东西。
这个问题困扰了科研界很久。
直到 2015 年,计算机视觉大神何恺明提出了「ResNet」,用一个巧妙的方法解决了它。

何恺明 2016 年提出的 ResNet,残差连接的起源。
每一层不光接收上一层处理过的结果,还同时保留一份原始输入,两个加在一起再往下传递。
这相当于给信息开了一条「直通车」。
不管中间那些层把信息处理成什么样,原始信号都能通过这条直通车传到后面,不会丢失。
这就是残差连接。
何恺明凭借这篇论文拿下了 CVPR 2016 最佳论文奖,后来这个方法几乎成了深度学习的标配,现在的大模型基本都在用。
但残差连接有个「两难困境」。
一种做法(Pre-Norm)能防止信息衰减,但层数多了之后,各层学到的东西会越来越像,梯度贡献变小。
另一种做法(Post-Norm)能避免这个问题,但信息衰减又回来了。
豆包团队的思路是:既然一条直通车不够,那就开四条。
让网络自己学习这四条通道之间怎么配合、怎么混合。
这就是超连接。
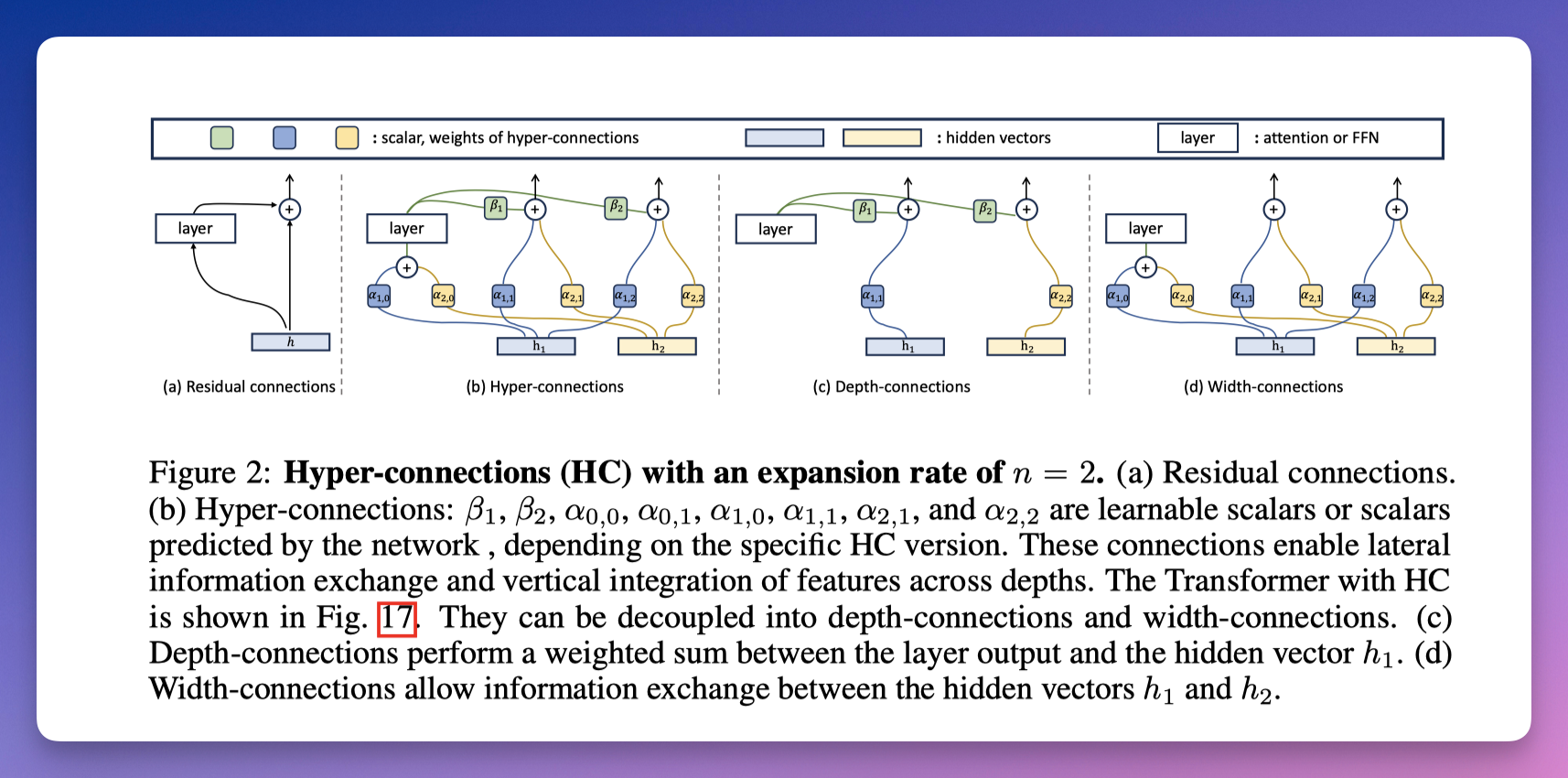
从残差连接到超连接,核心是把一条通道扩成多条。
实验效果很好,模型收敛速度最快加速了 80%。
但四条直通车的超连接也有个问题,模型规模一大,训练就容易出事。
DeepSeek 训练 270 亿参数的模型时发现,用超连接的模型跑到一万多步时,训练损失(Train Loss)突然飙升,整个训练直接废了。
Train Loss 是什么?你可以理解为「模型犯错率」,越低越好。
问题出在哪?
大神何恺明提出的残差连接就像一面镜子,信号进去是 1,出来还是 1,不放大也不缩小。
但豆包团队的超连接为了让四条通道能互相配合,引入了一个可学习的「混合矩阵」。
这个矩阵一层一层乘下去,效果会累积。
DeepSeek 测了一下,在 270 亿参数的模型里,信号经过所有层之后被放大了将近 3000 倍。
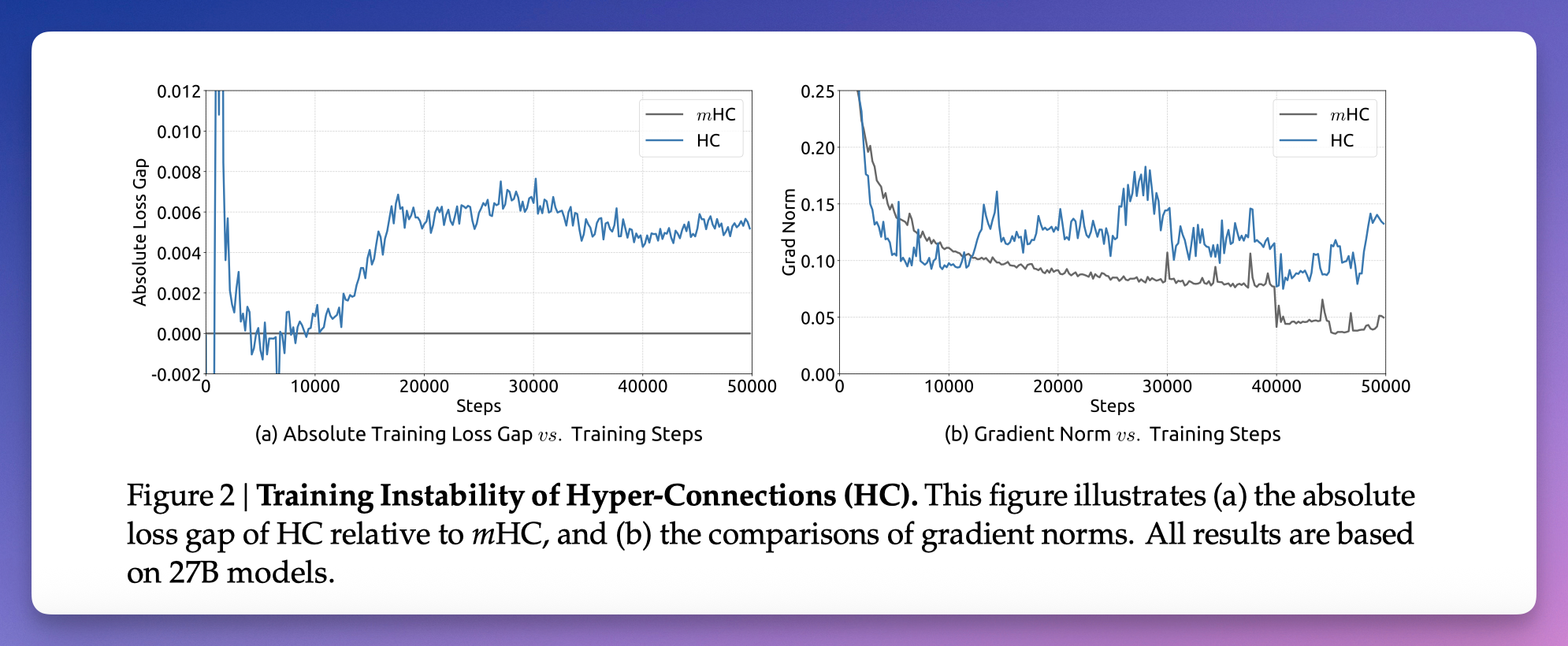
蓝线是原版超连接,灰线是 mHC,训练稳定性差距明显。
你想象一下把音响音量开到 3000 倍会怎样。
训练损失爆炸,训练报废。
DeepSeek 的解法是给这个混合矩阵装一个「限速器」。
具体来说,他们要求这个矩阵必须满足一个条件:每一行加起来等于 1,每一列加起来也等于 1。
数学上叫「双随机矩阵」。
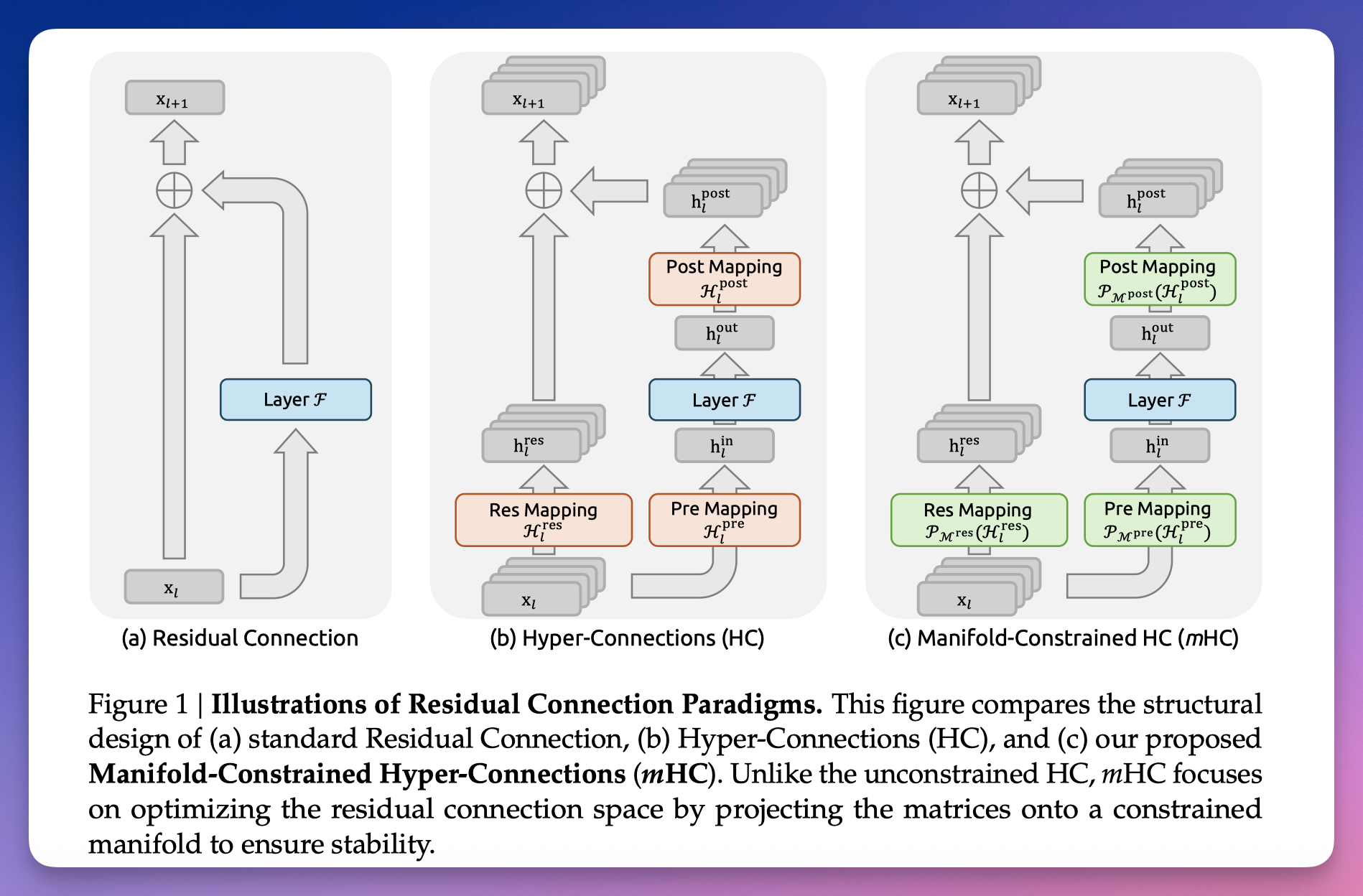
三代连接方式的演进:残差连接 → 超连接 → mHC。
这个约束有什么用?
它能保证信号经过这个矩阵之后,最多保持原样,绝不会被放大。
而且不管叠多少层,这个性质都能保持。
效果立竿见影。
加了这个约束之后,信号的放大倍数从 3000 降到了 1.6,降了三个数量级。
训练曲线变得平滑,稳定跑完。
当然,四条通道比一条通道要费更多资源。
DeepSeek 在工程上做了不少优化,把多个计算步骤合并、减少内存读写、让计算和通信并行。
这也是 DeepSeek 一直以来的强项。
最终这套方案只比原来多花 6.7% 的训练时间。
性能提升也很明显。
在测试中,mHC 在 8 个任务上全面超过了原版,大部分指标也超过了豆包的超连接。
比如 BBH 推理测试从 43.8 提升到 51.0,DROP 阅读理解从 47.0 提升到 53.9。
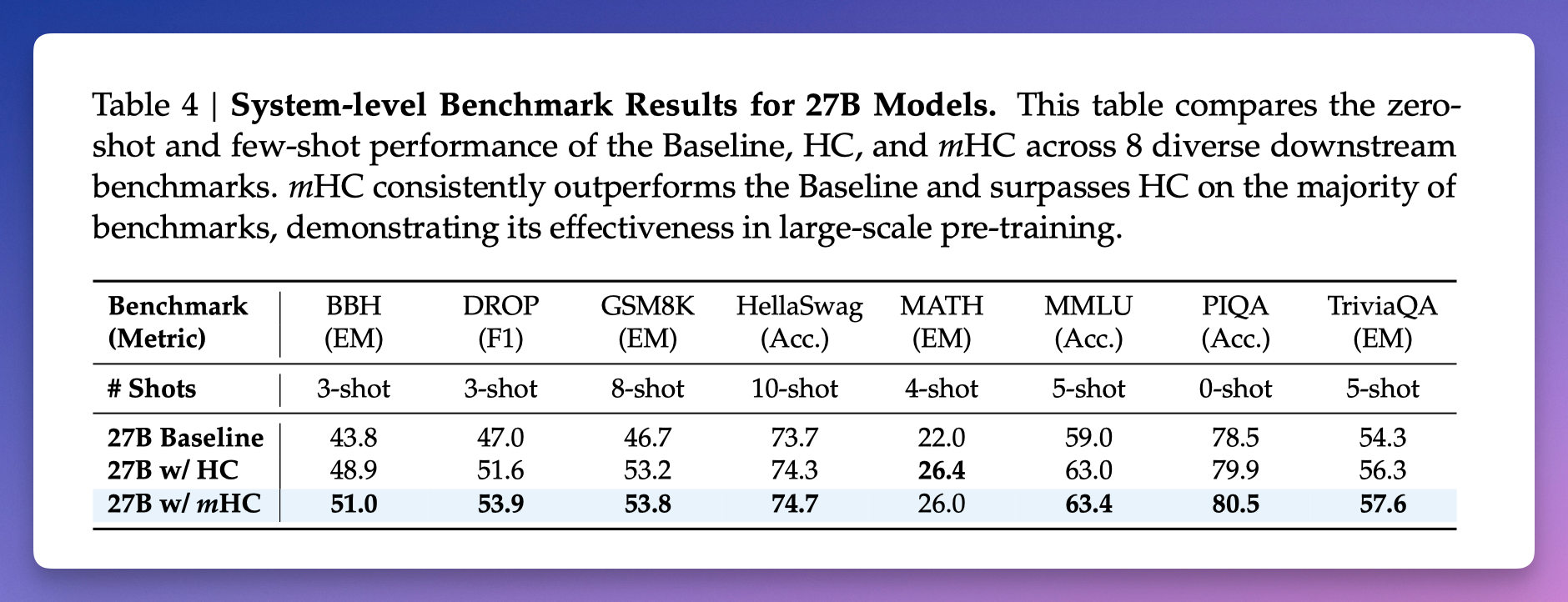
270 亿参数模型的测试结果,mHC 在多数指标上领先。
DeepSeek 还测了不同规模的模型,结论是:「模型越大,mHC 的优势越明显。」
这篇论文很 DeepSeek。
在技术上做深度优化,解决真正阻碍落地的问题。
超连接是豆包团队 2024 年提出的,效果好,但大规模训练时不稳定。DeepSeek 加了一层数学约束,让它能稳定完成 270 亿参数的训练。
这种扎实的工程能力,可能比提出一个新概念更实际。
梁文锋出现在作者名单里,这不是第一次。
2025 年 7 月,DeepSeek 和北大合作的 NSA(原生稀疏注意力)论文拿了 ACL 2025 最佳论文奖,梁文锋也在通讯作者里。
对于 AI 公司的 CEO 来说,这种技术参与度不多见。
mHC 如果被验证有效,大概率会用在 DeepSeek 后续模型里。
论文基于 DeepSeek-V3 的 MoE(混合专家)架构做实验,发布时间点又是 2025 年最后一天,很难不让人联想这是在为 2026 年的新模型做铺垫。
DeepSeek 发论文的同时,国内其他 AI 公司也没有闲着。
智谱 12 月 30 日开启港股招股,1 月 8 日以股票代码「2513」挂牌上市,有望成为「全球大模型第一股」。
MiniMax 也通过了港交所聆讯,同样计划 1 月上市。
月之暗面的 Kimi 据说会在 1 月或 3 月上线新的多模态模型,可能是 K2.1 或 K2.5。
2026 年的 AI 竞争,从 DeepSeek 的论文和智谱的招股书开始。
附上文中提到的相关论文链接。
-
mHC:https://arxiv.org/abs/2512.24880
-
超连接:https://arxiv.org/abs/2409.19606
-
ResNet:https://arxiv.org/abs/1512.03385
我是木易,Top2 + 美国 Top10 CS 硕,现在是 AI 产品经理。
关注「AI信息Gap」,让 AI 成为你的外挂。
精选推荐

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐


 42
42 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)