Kafka 消息队列深入解析
摘要:Apache Kafka是一个高可靠、高吞吐的分布式消息队列系统,采用日志顺序写入和分区机制存储数据,通过副本和ACK机制确保可靠性。Kafka采用Pull模型,支持持久化存储和水平扩展,适用于实时数据处理、日志聚合等场景。相比NSQ,Kafka更适合需要高吞吐和持久化的应用。其核心优势包括顺序I/O、分区负载均衡和灵活的消息确认机制,使其成为现代微服务架构中处理大规模数据流的理想选择。(1
# Kafka 消息队列深入解析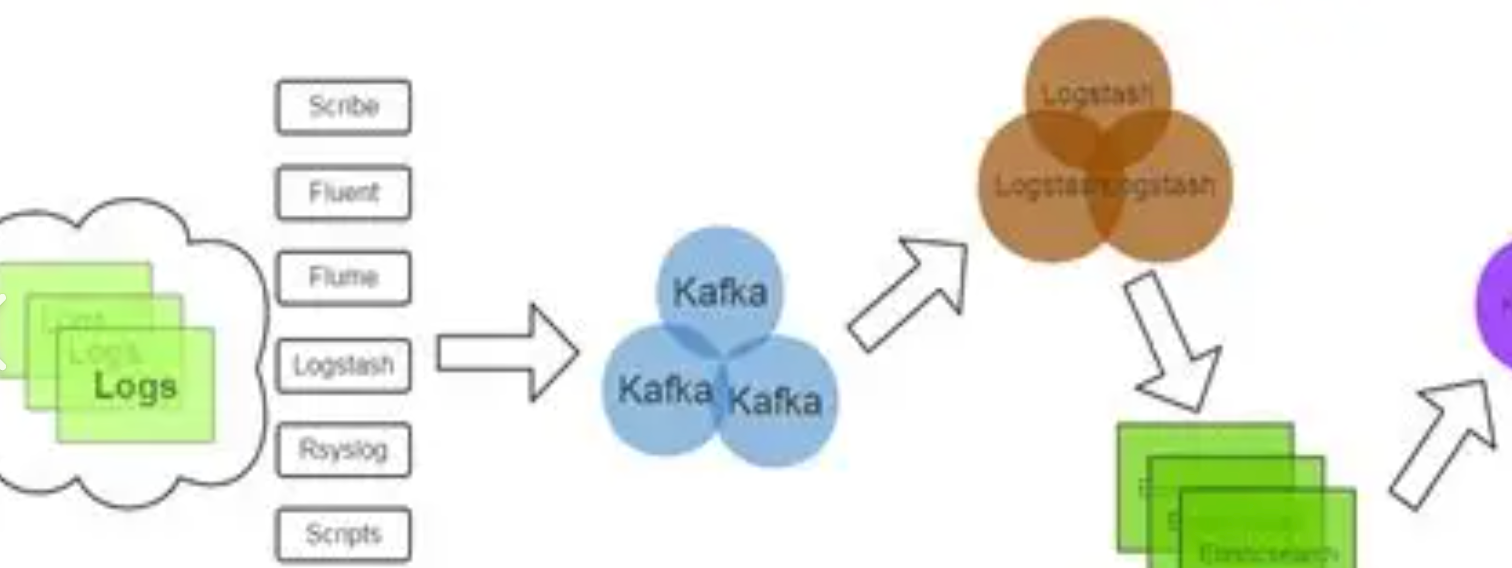
Apache Kafka 是一个开源的分布式事件流平台,广泛应用于实时数据处理和数据传输。它的高吞吐量、可扩展性和可靠性使其成为现代微服务架构中不可或缺的一部分。本文将探讨 Kafka 的可靠性机制、使用场景以及与其他消息队列(如 NSQ)的比较。
## 1. Kafka 的可靠性
### 日志如何保存
Kafka 将所有消息以顺序的方式写入到日志文件中。这些日志文件存储在磁盘上,并按照主题(topic)和分区(partition)进行组织。每条消息都有一个唯一的偏移量(offset),用于标识其在日志中的位置。
### 副本机制
为了提高数据的可靠性,Kafka 提供了副本机制。每个分区可以有多个副本(replicas),这些副本分布在不同的 broker 上,以避免单点故障。一个分区的一个副本被称为主副本(leader),其他副本为从副本(follower)。所有的写入和读取操作都通过主副本进行,而从副本则负责同步数据。
### ACK 机制
Kafka 使用 ACK 机制来确保消息的可靠性。在生产者发送消息时,可以设置不同的 ACK 级别:
- `acks=0`:生产者不等待任何确认,最不可靠。
- `acks=1`:生产者等待主副本确认,较可靠。
- `acks=all`:生产者等待所有副本确认,最高可靠性。
通过调整 ACK 级别,可以在性能和可靠性之间找到平衡。
## 2. 为何使用 Kafka?
Kafka 适用于多种场景,包括实时数据流处理、日志聚合和事件源等。其主要优点包括:
- **高吞吐量**:Kafka 能够处理数百万条消息每秒,适合大规模数据流。
- **可扩展性**:通过增加 broker 和分区,可以轻松扩展 Kafka 集群。
- **持久性**:消息可以持久化到磁盘,确保数据安全。
### Kafka 中的 Broker
Broker 是 Kafka 集群中的服务器,负责存储和转发消息。一个集群可以包含多个 broker,它们共同工作以提供高可用性和负载均衡。
### Kafka 如何实现分区
Kafka 通过将主题划分为多个分区来实现数据的分布和负载均衡。每个分区都是一个有序的、不可变的消息序列。生产者可以根据某种策略(如轮询、哈希等)将消息发送到不同的分区,从而实现并行处理。
## 3. Kafka 是 Push 还是 Pull?
Kafka 采用的是 Pull 模型。消费者主动向 Kafka 请求消息,而不是由 Kafka 主动推送消息给消费者。这种设计允许消费者灵活控制消费速率,提高了系统的稳定性。
### Kafka 与 NSQ 的区别
- **架构**:Kafka 是一个分布式系统,支持数据持久化和高可用性;而 NSQ 更简单,通常用于内存中消息的快速处理。
- **消息模型**:Kafka 使用主题和分区进行消息分类和存储,支持多种消费模式;而 NSQ 则更侧重于实时消息处理,适合低延迟场景。
- **使用场景**:Kafka 更适合需要高吞吐量和持久化的场景,如日志收集和流处理;而 NSQ 则在需要快速响应和简单架构的场合更为合适。
### Partition 数据如何保存到硬盘
Kafka 将每个分区的数据以日志的形式顺序写入到磁盘。每当有新消息产生时,Kafka 会将其追加到日志文件的末尾。数据的写入是顺序的,因此可以充分利用磁盘的读写性能,从而提升整体吞吐量。Kafka 还会定期进行日志压缩和清理,确保磁盘的有效使用。
## 总结
Apache Kafka 是一个强大的消息队列系统,凭借其高可靠性、高吞吐量和良好的可扩展性,成为许多企业实时数据处理的首选。了解 Kafka 的工作原理和特点,有助于开发者在合适的场景下选择和使用它,以满足业务需求。无论是处理日志、事件流,还是进行实时分析,Kafka 都是一个值得信赖的解决方案。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)