一篇文章入门 C++(三万字长文,从用法到底层原理,全面分析)
本文全面介绍了C++的入门知识,从Hello World程序开始,详细讲解了命名空间、输入输出、缺省参数、函数重载、引用、内联函数和nullptr等核心概念。文章通过大量代码示例和底层原理分析,帮助读者理解C++如何弥补C语言的不足,提升编程效率和安全性。内容包括命名空间解决命名冲突、引用简化指针操作、内联函数替代宏函数等实用技巧,为后续学习类和对象打下坚实基础。全文约3万字,适合有一定C语言基础
目录
入门:第一个 C++ 程序:Hello World
(一)C++ 的起源原因
C++ 研发的初衷就是为了弥补 C 语言缺陷,保留高效性。以下是一些核心改进方向:
|
C 语言缺陷 |
C++ 解决方案 |
|
命名冲突 |
命名空间(namespace) |
|
函数传参效率低、无法修改实参 |
引用(&) |
|
函数调用灵活性不足 |
缺省参数、函数重载 |
|
宏函数易出错、无类型检查 |
内联函数(inline) |
|
空指针类型歧义 |
nullptr(C++11) |
|
编程范式单一 |
面向对象(类与对象)、泛型编程(模板) |
本篇文章,将会以第一个 C++ 程序作为开始,依次讲解命名空间、C++的输入输出、引用、缺省参数、函数重载、内联函数、nullptr,从而入门C++语法,了解本贾尼博士的设计初衷。
(二)C++的第一个程序
C++ 兼容 C语言绝大多数的语法,所以 C语言实现的 hello world 依旧可以运行,C++中需要把定义文件代码后缀改为.cpp。
vs 编译器看到是 .cpp 就会调用 C++编译器编译,linux 下要用 g++ 编译,不再是 gcc。
1、C语言程序代码
#include <stdio.h> // C语言标准输入输出头文件
int main()
{
printf("Hello World\n"); // C语言IO函数,需手动加换行符
return 0;
}2、C++程序代码
#include <iostream> // C++标准IO流头文件
using namespace std; // 展开std命名空间(标准库所有内容均在std中)
int main()
{
cout << "Hello World" << endl; // C++输出流,支持链式调用
return 0;
}这里的 using namespace std; 意思为展开命名空间,命名空间是为了避免命名冲突而设计的;cout << "Hello World" << endl; 是用来打印 Hello World 的。接下来我们来讲解这两个语法。
一、命名空间
(一)命名空间的价值
很直观得,我们来看一段代码:
#include <stdio.h>
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
int main()
{
// 编译报错:error C2365: “rand”: 重定义;以前的定义是“函数”
printf("%d\n", rand);
return 0;
}在预处理阶段,#inclued<stdlib.h> 会被展开为头文件内的文本,其中声明的 rand() 函数会进入全局作用域;而我们在全局作用域定义的 rand 变量与这个函数标识符重名,因此在编译阶段编译器会检测到命名冲突并报错。
就是说:同一个作用域下,不能出现同名变量。
作用域可以这样区分:
程序最顶层、没有被任何 “代码块边界”({ }/ 缩进 / 命名空间)包裹的区域为全局作用域;
命名空间 / 类的{}属于 “全局层级的限定作用域”;
除此之外,被 “代码块边界” 包裹的区域(不管是{}、缩进、函数参数())称为局部作用域。
所以我们可以得出结论:namespace 的本质是定义出一个域,这个域跟全局域各自独立,不同的域可以定义同名变量,即可解决上面 rand 变量冲突的问题。
那我们怎么去定义命名空间呢?
(二)命名空间的定义
1、定义命名空间的方法
定义命名空间,需要使用到 namespace 关键字,后面跟命名空间的名字,然后接一对 {} 即可,{} 中即为命名空间的成员。命名空间中可以定义变量 / 函数 / 类型等。
所以我们就可以解决上面的问题了:
#include <stdio.h>
#include <stdio.h>
#include <stdlib.h>
namespace bit
{
int rand = 10;
}
int main()
{
// 这⾥默认是访问的是全局的rand函数指针
printf("%p\n", rand);
// 这⾥指定bit命名空间中的rand
printf("%d\n", bit::rand);
return 0;
}这里的 bit:: 的意思是去 bit 这个作用域下去查找 rand 变量。
C++中域有函数局部域、全局域、命名空间域、类域;域影响的是编译时语法查找一个变量/函数/类型出处(声明或定义)的逻辑。所有有了域隔离,名字冲突就解决了。
局部作用域与全局作用域不仅会影响编译阶段的名字查找逻辑,还会直接决定变量的生命周期;而命名空间域和类域属于全局层级的限定作用域(并非 “本质等同于全局域”)。
其中:命名空间域内的变量均为全局生命周期,仅限定名字查找;类域中静态成员为全局生命周期,非静态成员的生命周期随对象(由对象所在作用域决定),二者均不会像局部域那样改变变量的全局 / 局部生命周期属性。(类在下一篇文章讲解,这里仅为知识完整性书写)
2、namespace的嵌套定义
在实际项目开发中,团队成员分工不同且人数较多,若所有开发者都直接在全局作用域下定义命名空间,会导致命名空间数量杂乱,严重影响项目的整体管理效率。
因此,我们通常先为每个业务小组,在全局作用域下分配一个独立的命名空间;小组内部,成员再在该命名空间下创建专属的子命名空间。
这种命名空间的定义,就叫作嵌套定义。
我们之前提到过,要访问 bit 命名空间下的 rand 变量,写法是 bit::rand;如果是嵌套命名空间,只需在前面逐层补充命名空间名称即可,比如要访问 bit 下 xiaoming 子命名空间的 rand 变量,就写成 bit::xiaoming::rand。
但是我们要注意一个点,namespace只能定义在全局域。
#include <iostream>
// 定义外层命名空间
namespace bit
{
// 定义嵌套的子命名空间(对应小组成员xiaoming)
namespace xiaoming {
int rand = 10; // 子命名空间内的变量
}
// 再定义一个子命名空间(对应成员lihua)
namespace lihua {
double rand = 3.14; // 不同子命名空间可同名变量,无冲突
}
}
int main()
{
// 访问嵌套命名空间的变量
std::cout << "小明的rand变量:" << bit::xiaoming::rand << std::endl; // 输出 10
std::cout << "李华的rand变量:" << bit::lihua::rand << std::endl; // 输出 3.14
return 0;
}3、命名空间的重复定义
在同一项目的多个源文件中,允许定义名称相同的命名空间。
编译器在编译链接阶段,会自动将这些分散在不同文件中的同名命名空间,合并为一个统一的命名空间,其内部的标识符(变量、函数、子命名空间等)会被整合,使用时完全等同于在单个文件中定义的完整命名空间。
文件 1:bit_namespace1.cpp
#include <iostream>
// 定义bit命名空间,包含xiaoming的变量
namespace bit
{
namespace xiaoming {
int rand = 10; // 小明定义的rand变量
}
}文件 2:bit_namespace2.cpp
#include <iostream>
// 同名的bit命名空间,编译器会和文件1的bit合并
namespace bit
{
namespace lihua {
double rand = 3.14; // 李华定义的rand变量
}
}
// 主函数测试
int main()
{
// 可直接访问两个文件中bit命名空间下的子命名空间变量
std::cout << "小明的rand:" << bit::xiaoming::rand << std::endl; // 输出10
std::cout << "李华的rand:" << bit::lihua::rand << std::endl; // 输出3.14
return 0;
}(三)命名空间的使用
编译查找一个变量的声明/定义时,默认只会在局部或者全局查找,不会到命名空间里面去查找。所以下面程序会编译报错。所以我们要使用命名空间中定义的变量/函数,有三种方式。
#include<stdio.h>
namespace bit
{
int a = 0;
int b = 1;
}
int main()
{
// 编译报错:error C2065: “a”: 未声明的标识符
printf("%d\n", a);
return 0;
}1、指定命名空间访问
项目中推荐这种方式。格式:命名空间::成员
前面的bit::rand、bit::xiaoming::rand,已经进行了较为详细的讲解,这里不再过多阐述。
指定命名空间访问是项目开发中最推荐、最安全的方式 —— 它能清晰标明标识符的归属,完全避免命名冲突,尤其适合多人协作、多模块嵌套的复杂项目。
以下是具体的代码案例:
#include <iostream>
// 项目命名空间
namespace bit {
int rand = 10; // 自定义rand变量
}
int main()
{
// 核心:指定完整命名空间访问(推荐写法)
std::cout << bit::rand << std::endl; // 精准访问bit命名空间的rand
return 0;
}2、using将命名空间中某个成员展开
项目中经常访问的不存在冲突的成员推荐这种方式。格式:using 命名空间::成员
可以只将命名空间中特定的无冲突成员 “展开” 到当前作用域。
既能简化常用成员的访问,不用每次写完整的 命名空间::;又能避免一次性展开整个命名空间即 using namespace xxx,从而导致的命名冲突风险,非常适合项目中频繁访问且无重名的成员。
以下是具体的代码案例,其中的 std::cout 我们先当成 cout 来看,是打印的作用,马上我们将讲解它的具体含义:
#include <iostream>
namespace project
{
namespace util
{
int square(int num) {
return num * num;
}
int cube(int num) {
return num * num * num;
}
int rand = 100;
}
}
int main()
{
// 核心:只展开频繁使用且无冲突的 square 函数
using project::util::square;
// 简化访问:不用写 project::util::square,直接用 square
std::cout << "5的平方:" << square(5) << std::endl; // 输出 25
// 不常用的 cube 函数,仍用完整命名空间访问(避免不必要的展开)
std::cout << "5的立方:" << project::util::cube(5) << std::endl; // 输出 125
// 有冲突风险的 rand 变量,仍用完整命名空间访问(防止和全局 rand() 函数冲突)
std::cout << "自定义rand:" << project::util::rand << std::endl; // 输出 100
return 0;
}3、展开命名空间中全部成员
项目不推荐,冲突风险很大,日常小练习程序、算法题为了方便推荐使用。
我们第一个代码中给出了 using namespace std; 这句代码,意思就是展开 std 命名空间中的所有成员;C++ 标准库都放在这个 std 命名空间中,即 standard。
就比如上面的 std::cout、std::endl 都是 std 这个命名空间中的内容。
前面的命名空间都是定义好了才能使用,那为什么这个可以直接使用呢?
首先,我们要明确 using namespace std; 这句代码并不会创建 std 命名空间。
之所以能直接引用 std 内的标识符(如 cout、endl),核心原因在于:std 是 C++ 标准库提前定义好的全局命名空间,并非由开发者创建。当我们通过 #include <iostream>、<string> 等指令引入标准库头文件时,这些头文件会自动将 std 命名空间的定义(包含所有标准库标识符,如 cout、endl、vector 等)加载到程序的全局作用域中。
需要注意的是,项目开发中不推荐在全局作用域写 using namespace std;,这会将 std 内上千个标识符全部暴露到全局作用域,极易与自定义标识符(如 count、rand 等)产生命名冲突。
更推荐局部使用(如仅在函数内写),或直接用 std::cout 这种指定命名空间的方式访问,兼顾简洁性与安全性。
#include <iostream>
#include <algorithm>
// 自定义全局变量count,无冲突风险
int count = 10;
int main()
{
// 仅在main函数内(局部作用域)展开std命名空间
using namespace std;
// 函数内可直接用cout/endl,简化书写
cout << "自定义count:" << ::count << endl; // 输出 10
// 同时可正常使用std::count(通过限定符区分)
int arr[] = {1,2,3,1,1};
int num = count(arr, arr+5, 1); // 统计1的个数,输出 3
std:cout << "数组中1的个数:" << num << std::endl;
return 0;
}这里的 ::count 表示到全局域中寻找标识符 count,因为展开了命名空间 std 后,局部作用域中已经有了 count 命名的函数,为了准确找到 count 变量,应该去全局域中找。
所以我们寻找标识符的规则到底是什么呢?
(四)标识符的寻找规则
我们从命名空间使用的三种方式去展开这个问题。
(1)命名空间::成员
如果使用了 bit::count 这种带有命名空间限定符,直接到该命名空间下去查找,不会有任何的起义,全局作用域的话是 ::count。(以count标识符为例)
(2)using spacename 命名空间;
使用 using spacename 命名空间;后,我们寻找标识符的优先级是这样的:
第一优先级:当前局部作用域。只要当前代码块(函数、{} 包裹的区域)内有同名标识符,直接使用,不会再去其他层级查找。
第二优先级:外层局部作用域。如果当前局部找不到,就逐层向上查找更外层的局部作用域,直到最外层函数作用域。
第三优先级:展开的命名空间 + 全局作用域。所有通过 using namespace 命名空间; 注入的标识符,和全局作用域的标识符处于同一优先级层级。若同名且类型 / 签名完全兼容,编译器无法区分,会报错误;若不同名或类型 / 签名可区分,则正常匹配。
我们需要注意一个点,命名空间只可以在全局作用域定义,而不能在局部作用域定义。
但命名空间却可以在全局作用域或者局部作用域展开,但是无论在哪里展开,它的查找优先级,都是第三优先级。
(3)using 命名空间::成员
这个与上面的 using spacename 命名空间; 截然不同,上面的展开之后,无论在哪里展开,最后都是第三优先级。
但是 using 命名空间::成员 如果在当前作用域写了,就是相当于把这个标识符拉到这个作用域了,拥有与这个作用域相同的优先级。
二、C++ 输入 & 输出
(一)头文件
<iostream> 是 Input Output Stream 的缩写,即标准的输入输出流库;定义了标准的输入、输
出对象。包含 istream、ostream等类的声明
(二)输出
1、std:cout
std::cout 是 ostream 类的对象,它主要面向窄字符(char)的标准输入流。而 << 就是流插入运算符,专门用于输入。
C++ 中的 cout 和 C 语言的printf最终都会将数据转化为字符形式输出到屏幕,但二者的实现逻辑有显著区别.
cout 内部提前准备好了处理不同类型数据的方式,编译器会根据输出数据的类型(如 int、double、char等),自动找到对应的处理方式,将数据转换成字符序列后输出,且类型不匹配时会在编译期报错,安全性更高。
而 printf 作为 C 语言函数没有这种自动识别能力,必须通过占位符( %d / %f / %s 等)手动指定数据类型,程序会按占位符规则解析数据,并转换为字符输出,若占位符与数据类型不匹配,不会在编译期提示错误,运行时会出现输出乱码、错误值甚至程序崩溃的问题。
这就是 C++ 在输出这方面的优越之处,不需要占位符的匹配,以及较为繁琐的格式。
2、std::endl
std::endl 是一个函数,流插入输出时,相当于插入一个换行字符加刷新缓冲区。
换行与输出放在一起讲解,是因为自动换行的 “视觉动作” 仅在程序执行输出功能时主动发生,而换行的本质是使用了转义字符 \n(换行符)。
输出场景下,当程序通过 cout << '\n' 或者 cout << endl 等方式输出\ n 时,控制台会自动识别该字符并执行换行动作,此过程无需用户手动干预,是程序主动触发的 “自动换行”。
而输入场景中,不存在 “自动换行” 的动作,控制台光标会始终停留在同一行等待输入,只有用户手动按下回车键(本质是输入\n 字符),光标才会跳到下一行,该换行是用户手动触发的,而非输入功能本身自动产生。
所以说,endl = \n + 强制刷新缓冲区。强制刷新能保证数据及时输出(调试 / 实时场景必备),但性能略低;普通输出用 \n 更高效,仅需立刻输出时用 endl。
3、自定义类型输出
但是这里涉及到运算符重载的知识,在此部分不作详细讲解。
我们只需要知道:未重载 << 运算符时,cout 不能直接输出结构体(无默认输出规则);重载 << 运算符后,cout 可以像输出普通变量一样直接输出结构体(按自定义格式输出)。
printf 只能输出一些内置类型变量(int、char等),但是不能输出复合类型,也就是自定义类型的;而 C++ 中的 cout 通过运算符重载之后可以,这也是 C++ 于 C语言的一个进步。
4、具体代码实例
cout / cin / endl 等都属于 C++ 标准库,C++ 标准库都放在一个叫 std(standard) 的命名空间中,所以要通过命名空间的使用方式去用他们。
可以指定命名空间访问,也可以展开命名空间,这样就不需要 std:: 前缀了。
同时我们要知道,这里我们没有包含<stdio.h>,但是也可以使用 printf 和 scanf,在包含<iostream> 时间接包含了。vs 系列编译器是这样的,其他编译器可能会报错。
#include<iostream>
int main()
{
int a = 1;
double b = 2.0;
char c = 'b';
//输出
/*
1、endl是一个函数,可以作为换行符号;或者直接用"\n"换行也可以
2、输出的时候,可以多次使用“流出入运算符号 <<”
3、每个 << 后面必须跟一个独立的、合法的内容(字符串、数值、变量等);多个内容之间必须用 << 分隔,不能直接挨在一起。
*/
cout << "1、三种数值输出测试" << endl;
std::cout << a << std::endl; //变量
std::cout << b << std::endl;
std::cout << c << std::endl;
std::cout << 1 << std::endl; //数值
std::cout << 'e' << "\n"; //字符
std::cout << "hello world" << std::endl ; //字符串
std::cout << "是吧" << "\n" << std::endl; //中文
/*
(1)使用了using namespace之后,我们就可以把前面的“空间名::”给去除掉
(2)但是也可以继续使用“空间名::”的方式去使用里面定义的内容
(3)注意,如果命名空间嵌套使用了,那么展开的时候,就“外层空间名::内层空间名”
*/
cout << "2、展开命名空间测试" << endl;
cout << c << endl << a << endl;
return 0;
}(三)输入
1、std::cin
std::cin 是 istream 类的对象,它主要面向窄字符的标准输入流。而 >> 就是流提取运算符,专门用于输出。
cin 是 C++ 标准库中 std::istream 类的全局对象,依托 C++ 运算符重载机制实现输入功能,可自动识别输入数据的类型(如int、double、char等),无需手动指定格式,且类型不匹配时会在编译期报错,安全性更高。
而 scanf 是 C 语言的标准输入函数,无类型自动识别能力,必须通过占位符(%d / %f / %c等)手动指定输入数据的格式,若占位符与数据类型不匹配,编译期无提示,运行时会出现输入错误、数据乱码甚至程序崩溃的问题。
总结一下就是:输入的原始数据均为字符序列(字符串),cin 会自动识别变量类型、scanf 需通过占位符指定类型,二者都会将字符串解析转换为对应类型的数据后,再赋值给变量。
2、具体代码实例
#include<iostream>
int main()
{
//输入
cout << "1、输入" << endl;
long long a1, a2, a3;
cout << "请依次输入三个数的数值:";
cin >> a1 >> a2 >> a3;
// 如果再在变量 a1 a2 a3前加入空格,不会输出
// 没有加引号的空格,是格式空格,不会输出
// 引号里面的是内容空格,会输出
cout << "第一个值为:" << a1 << endl;
cout << "第二个值为:" << a2 << endl;
cout << "第三个值为:" << a3 << endl;
return 0;
}三、缺省参数
(一)概念与本质
1、概念
缺省参数是声明或定义函数时,为函数的参数指定一个默认值,即缺省值。
在调用该函数时,调用时可省略该参数:如果没有指定实参,则采用该形参的缺省值,否则使用指定的实参。
缺省参数分为全缺省参数和半缺省参数(默认参数)。
全缺省就是全部形参给缺省值,如:void Func(int a=10, int b=20, int c=30) 。
半缺省就是部分形参给缺省值,必须从右往左,依次连续缺省,不能间隔跳跃给缺省值。比如,可以 void Func(int a, int b=20, int c=30),不允许 void Func(int a=10, int b, int c=30))。
2、本质:提升函数调用灵活性,避免重复传参,优化性能(如减少扩容开销)
3、语法格式:返回值类型 函数名(参数类型 参数名 = 缺省值)
(二)示例代码与调用规则
#include <iostream>
using namespace std;
// 全缺省
void Func1(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
// 半缺省
void Func2(int a, int b = 10, int c = 20)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
// 1、全缺省调用方式(灵活省略参数)
Func1(); // 省略所有参数:a=10, b=20, c=30
Func1(100); // 省略后两个参数:a=100, b=20, c=30
Func1(100, 200); // 省略最后一个参数:a=100, b=200, c=30
Func1(100, 200, 300); // 不省略参数:a=100, b=200, c=300
// 2、半缺省调用方式(必须传递左侧无默认值的参数)
Func2(50); // 传递a,省略b、c:a=50, b=20, c=30
Func2(50, 60); // 传递a、b,省略c:a=50, b=60, c=30
Func2(50, 60, 70); // 传递所有参数:a=50, b=60, c=70
return 0;
}(三)工程级注意事项
1、半缺省参数必须从右往左连续指定
(1)错误示例:void Func(int a=10, int b);(左侧缺省,右侧未缺省)
(2)原因
避免传参歧义。
编译器按 “左到右” 匹配实参,若允许间隔缺省,即中间参数有默认值而右侧无,无法确定实参对应哪个形参。
(3)案例以及底层原因说明
如果编译器允许 void Func(int a=10, int b);,那么我们调用时会产生严重歧义。
比如,Func(20); ,这个 20 应该给 a?还是给 b?
当我我们可以,Func(20, 30);,这样正常没问题,但上面那个调用就乱了。
这个时候,我们可能就会有一个疑问,难道 C++ 就不会跳过有缺省值的参数,直接传值给没有缺省值的参数吗?
答案是:本贾尼博士在设计的时候,并没有采取这样的方案。
其中的一个原因是:本贾尼博士在《The C++ Programming Language》中反复强调:C++ 的语法设计必须 “让编译器和程序员都能无歧义地理解代码”。
若允许 “跳跃传参”,语法会引入致命歧义。
比如定义 void Func(int a=10, int b=20, int c);,调用Func(30);时,编译器无法判断 30 是给a、b还是c;即便增加语法糖(如Func(, , 30)),也会让代码可读性骤降。
程序员需要额外记忆 “哪些参数被跳过”,编译器需要额外解析 “跳跃标记”,违背 C++“简单解析、直观理解” 的初衷。
而 “从右往左连续缺省” 的规则,让参数匹配逻辑绝对唯一:实参从左到右匹配无缺省的形参,剩下的用缺省值,编译器和程序员都能一眼看懂,无任何歧义。
2、函数声明与定义分离时,缺省值只能在声明中指定
(1)错误案例
// 头文件.h
void Func(int a); // 声明未给缺省值
// 源文件.cpp
void Func(int a=10) {} // 定义给缺省值:编译报错(2)原因
我们从它的对立面去解释为什么。
首先是,为什么是只能在声明中指定,而不能只在定义中指定。
因为假设现在有三个文件,main.cpp、func.h、func.cpp。编译 main.cpp 时,编译器只看 main.cpp 和它 #include 的 func.h,完全不知道func.cpp里写了什么。
如果缺省值写在 func.cpp 的定义里,编译器编译main.cpp时根本看不到,就无法确定func()该用什么缺省值。
如果你在 func.h 中定义了两个参数,但是由于你在 func.cpp 里面写了缺省值,此时,如果你调用时使用了缺省值,只传递了一个参数,这样编译器会判定 “传递的实参数量与函数声明要求的形参数量不匹配”,直接编译失败。
因为到了链接时,才会查找所有 .cpp 编译出的目标文件,匹配函数声明和定义,最终确定函数的实际实现。
然后就是为什么不能同时指定呢?
第一,假设这个函数有三个参数,如果同时指定,你声明中指定了一个,定义时指定了两个,在你调用时,运用到了定义的两个缺省值,就会出现上面所说的问题。
第二,假设声明与函数定义的缺省值不一样,那么用谁的呢?这就会导致歧义。
而函数声明与定义分离时,缺省值只能在声明中指定;这样去制定规则,就可以完美地避开上面所提及的两个问题 —— ①形参与实参个数不一、②缺省值歧义。
3、缺省值必须是常量或全局变量
(1)错误示例:void Func(int a = rand());(rand () 是函数调用,非常量)
(2)原因
函数的缺省参数本质是:编译器在编译阶段帮你自动填充的参数值,而非运行时动态计算。
编译器处理函数声明 / 定义时,需要明确知道 “当调用者不传这个参数时,该用什么值替代”,这个值必须在编译时就能确定,不能依赖运行时的上下文。
局部变量(比如函数内的 int a = 10;)的内存分配、值的确定都在运行时:局部变量的作用域仅限于函数执行期间,编译器无法在编译阶段确定它的地址或值,比如局部变量可能每次函数调用都在栈上分配不同地址,因此无法作为缺省值。
而常量(如 10、3.14)、全局 / 静态变量(存储在全局 / 静态存储区,编译期就确定地址和初始值)属于编译期可确定的值,编译器能直接把它们作为缺省值 “固化” 到编译后的代码中。
(四)缺省参数实际应用:栈初始化优化
我们栈的初始化,是要先开辟空间的,有时候我们并不确定需要多少空间,那么就可以使用缺省参数的值;如果确定的话,自己赋值就可以了,示例如下:
1、Stack.h

2、Stack.cpp

3、test.cpp

四、函数重载
(一)概念与核心条件
1、定义
C++ 支持同一作用域中出现同名函数,但要求这些同名函数的形参不同,C 语言不支持。
2、重载条件(什么是形参不同)
(1)参数个数不同:void f() 与 void f(int a)
(2)参数类型不同:int Add(int a, int b) 与 double Add(double a, double b)
(3)参数顺序不同:void f(int a, char b) 与 void f(char b, int a)(本质是类型不同)
3、禁用条件
返回值有无或者返回值类型不同,不能构成重载,因为调用时可能不接受返回值,此时编译器无法区分调用哪个版本。
(二)示例代码与工程应用
#include <iostream>
using namespace std;
// 1. 参数类型不同
int Add(int x, int y) {
return x + y;
}
double Add(double x, double y) {
return x + y;
}
// 2. 参数个数不同
void Print(int x) {
cout << "x=" << x << endl;
}
void Print(int x, int y) {
cout << "x=" << x << ", y=" << y << endl;
}
// 3. 参数顺序不同
void Show(int a, char b) {
cout << "a=" << a << ", b=" << b << endl;
}
void Show(char a, int b) {
cout << "a=" << a << ", b=" << b << endl;
}
int main() {
cout << Add(1, 2) << endl; // 调用int版本(匹配参数类型)
cout << Add(1.5, 2.5) << endl; // 调用double版本
Print(10); // 调用单参数版本
Print(10, 20); // 调用双参数版本
Show(10, 'a'); // 调用int+char版本
Show('a', 10); // 调用char+int版本
return 0;
}(三)底层原理:函数名修饰
1、C 语言不支持函数重载的原因
编译时函数名直接编码,如Add编码为_Add,同名函数会生成相同的编码,导致链接冲突。
2、C++ 支持函数重载的原因
编译时采用 “函数名 + 参数列表” 的名字修饰规则(不同编译器修饰规则不同)。
例如:Add(int, int)编码为_Add_int_int;Add(double, double)编码为_Add_double_double;链接时可通过修饰后的函数名区分不同函数,避免冲突。
(四)常见误区
1、函数重载与缺省参数的冲突场景
// 冲突示例:调用时存在歧义
void Func() {
cout << "无参版本" << endl;
}
void Func(int a = 10) {
cout << "缺省参数版本" << endl;
}
int main()
{
// 编译报错:调用不明确(既可以匹配无参版本,也可以匹配缺省参数版本)
Func();
return 0;
}在这种情况下,你根本无法确定我调用的是 Func(),还是说 Func(int a = 10)。
所以我们要:避免在同一作用域中定义 “无参函数” 与 “全缺省参数函数”,或通过显式传参消除歧义(如Func(20))。
2、关于 const 修饰
1、问题 1:以下两个函数是否构成重载?
void f(int a) {}
void f(const int a) {} // 不构成重载!不构成重载。原因:const 修饰的形参,若为值传递,编译器视为同一类型(形参是实参的拷贝,const 不影响参数类型)
2、问题 2:以下两个函数是否构成重载?
void f(int* a) {}
void f(const int* a) {} // 构成重载!构成重载。原因:const 修饰指针指向的内容,参数类型不同(int* 与 const int*)。
3、详细说明原因
一句话总结就是:
值传递时,const 只限制函数内部对副本的操作,不改变参数类型,所以 int 和 const int 不能重载。
指针 / 引用传递时,const 改变了指针的访问权限(只读 → 读写),类型不同,所以 int 和 const int 可以重载。
再具体一点:
传值调用时,函数拿到的是实参的独立副本,哪怕给副本加 const,也仅限制函数内修改副本,不会影响实参本身,编译器认为 int a 和 const int a 是同一个接口,因此无法构成重载。
传址调用时,函数直接操作的是实参所在的内存地址,const 会直接限制对该地址指向的实参的修改权限(int*可改实参、const int*不可改实参),这是两种不同的参数类型,编译器能明确区分,因此可以构成重载。
也就是,我们只需要关注一个重点,我加 const 之后,实参的权限有没有不一样;还是一样,不构成重载,不一样了,构成重载。
五、引用
(一)概念与本质
1、定义:为已存在的变量取别名,编译器不为引用开辟独立空间,与原变量共用同一块内存。(注意它仅仅是一个别名,不是新定义的变量。)
2、语法格式:类型& 引用名 = 原变量;(必须初始化)
3、底层本质
引用在底层等价于不可修改指向的指针常量,汇编层面与指针完全一致,如 int& b = a 等价于 int* const b = &a 。
Tip:指针常量就是 const 修饰指针,指针的指向不能被修改,指针指向的内容可以修改。
4、对底层本质的常见疑问
(1)问题一:引用是取别名,如同上面,给 a 取了一个别名 b,对 b 执行 b++,本质上就是 a++ ,但是你却跟我说在底层,b 其实是指针,它又是值,又是指针,这不是自相矛盾了吗?
在语法上,引用表现为变量的 “别名”,操作起来完全像值一样直接,如 ++b 直接作用于 a。
但在底层,其实是编译器偷偷用 “指针常量”(如 int* const)的逻辑来实现的,对于语法层的内容,它自动帮你做了解引用,让你感觉不到指针的存在,所以汇编层面和指针完全一致。
转化逻辑是:你的 ++b 在底层本质上是 ++(*b) ,就是说你用,是正常 ++b 去用,但是编译器在编译阶段,会自动把你的 ++b,翻译为++(*b)。
所以这不矛盾,因为引用在底层虽然是指针,但它是编译器自动帮你解引用的特殊指针。语法上它完全等同于原变量,底层实现上它存储了原变量的地址。
C++ 引用的本质可以概括为一句话:“语法层面是变量的别名,底层实现是指针常量”。 编译器帮我们完成了自动解引用,所以我们用起来像值语义一样方便,但底层效率和指针一致。
(2)问题二:引用汇编层面与指针怎么会一样,不是多了一个 const 修饰吗?
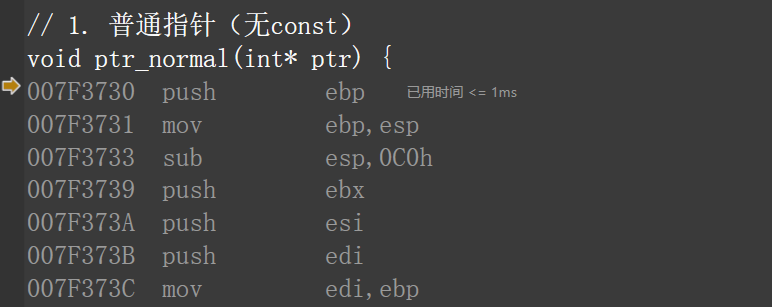
因为 const 是 “编译期检查”,不是 “运行期指令”:一旦代码通过编译(比如你只访问内容、不改指向),生成的汇编指令里不会有任何 “const 相关的额外指令” —— 因为 CPU 根本不知道什么是const,它只执行 “读写内存” 的指令。
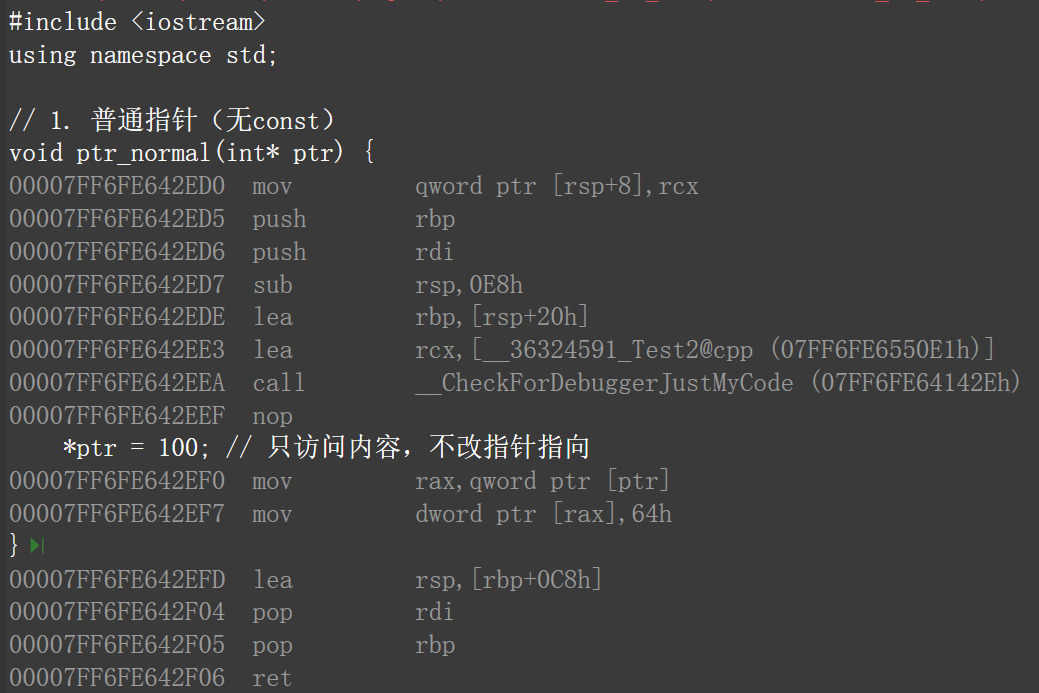
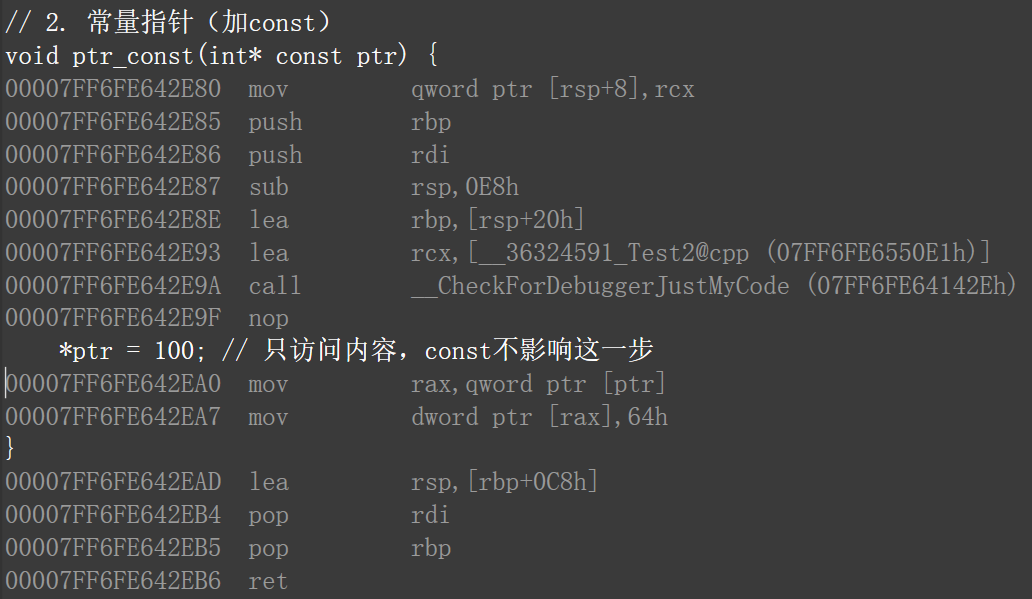
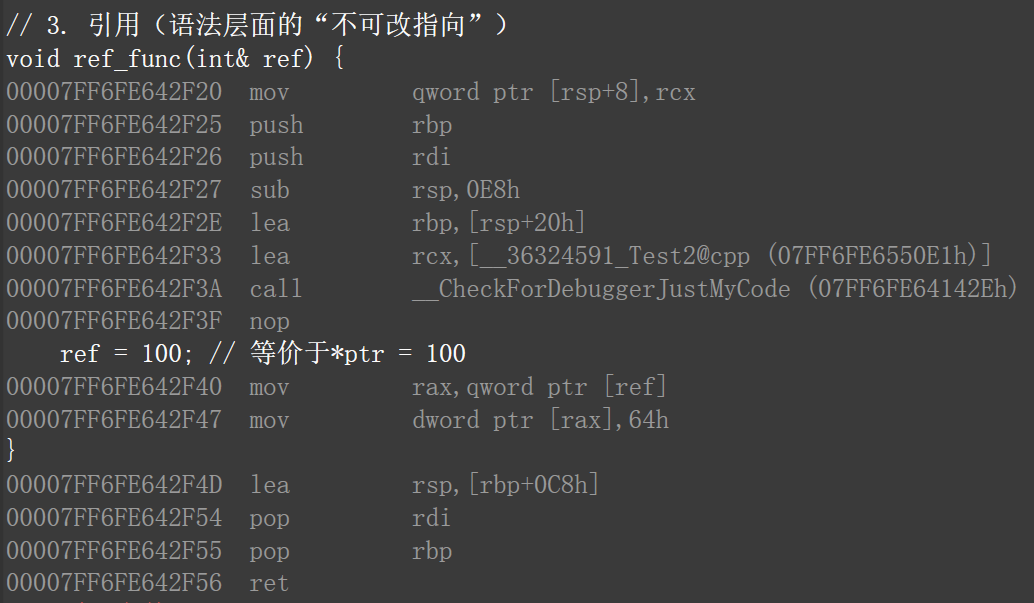
我们直接上代码,然后反编译,可以发现三种写法再汇编层面完全一致。
#include <iostream>
using namespace std;
// 1. 普通指针(无const)
void ptr_normal(int* ptr) {
*ptr = 100; // 只访问内容,不改指针指向
}
// 2. 常量指针(加const)
void ptr_const(int* const ptr) {
*ptr = 100; // 只访问内容,const不影响这一步
}
// 3. 引用(语法层面的“不可改指向”)
void ref_func(int& ref) {
ref = 100; // 等价于*ptr = 100
}
int main() {
int a = 10;
ptr_normal(&a);
ptr_const(&a);
ref_func(a);
return 0;
}
5、代码示例
#include<iostream>
using namespace std;
int main()
{
int a = 0;
// 引⽤:b和c是a的别名
int& b = a;
int& c = a;
// 也可以给别名b取别名,d相当于还是a的别名
int& d = b;
++d;
// 这⾥取地址我们看到是⼀样的
cout << &a << endl;
cout << &b << endl;
cout << &c << endl;
cout << &d << endl;
return 0;
}
(二)引用的特性
1、引用在定义时必须初始化
2、一个变量可以有多个引用
3、引用一旦引用一个实体,再不能引用其他实体,即不可以改变指向。
如果你明白了上面我对引用底层本质的分析,你会发现它们和 T* const 的规则完美一一对应。(这里的 T 是指任意数据类型)
第一条特性:指针常量( const 指针)必须在定义的同时初始化,否则它就成了 “野指针”(不知道指向哪里),编译器直接报错。
第二条特性:指针底层是内存地址,一块内存地址可以被无数个指针指向且互不干扰。
第三条特性:指针常量(const 指针)指向一旦确定,指向就不能改变。虽然底层是指针,但语法层面被封装成了 “别名”,你写 b = 20 是赋值,修改的是指向的那块空间的值,不是改指向。
代码示例:
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
int main()
{
int a = 10;
// 编译报错:“ra”: 必须初始化引⽤
//int& ra;
int& b = a;
int c = 20;
// 这⾥并⾮让b引⽤c,因为C++引⽤不能改变指向,
// 这⾥是⼀个赋值
b = c;
cout << &a << endl;
cout << &b << endl;
cout << &c << endl;
return 0;
}(三)引用的使用
引用在实践中主要是于引用传参和引用做返回值中,减少拷贝提高效率和改变引用对象时同时改变被引用对象。
1、引用传参
// C语言交换函数(需指针,语法繁琐)
void SwapC(int* x, int* y) {
int temp = *x;
*x = *y;
*y = temp;
}
// C++引用传参(语法简洁,类型安全)
void SwapCpp(int& x, int& y) {
int temp = x; // 无需解引用,直接操作别名
x = y;
y = temp;
}
int main() {
int a = 10, b = 20;
SwapC(&a, &b); // 需传地址,易出错
SwapCpp(a, b); // 直接传变量,直观简洁
return 0;
}在 C语言中,我们直接使用传值调用,将实参的值直接赋值给形参,此时形参就是一个副本,对副本操作,根本不会影响实参;只用使用传址调用,才可以实现数据交换函数。
但是在 C++ 中,如果你使用了引用,我们可以通过传值的方式实现,避免了指针解引用的操作,原因还是我在上面讲解的 “关于引用的本质”。
引用本质上等价于不可修改指向的常量指针,尽管语法层面看似是传值调用(为实参创建别名 x、y),但底层仍通过地址操作实现,本质上与 C 语言的传址调用一致。
一些主要用 C 语言实现的数据结构教材中,使用 C++ 引用替代指针传参,目的是简化程序,避开指针,但是很多同学没学过引用,所以看不懂,下面的代码,现在再看,肯定清晰无比。
#include <cstdlib>
#include <iostream>
using namespace std;
// 链表结点定义(带指针别名)
typedef struct ListNode
{
int val;
struct ListNode* next;
} LTNode, *PNode;
// 链表尾插
void ListPushBack(PNode& phead, int x)
{
// 创建新节点
PNode newnode = (PNode)malloc(sizeof(LTNode));
if (!newnode) {
perror("malloc fail"); exit(1);
}
newnode->val = x;
newnode->next = NULL;
// 空链表直接赋值,非空找尾链接
if (!phead)
phead = newnode;
else {
PNode cur = phead;
while (cur->next) {
cur = cur->next;
}
cur->next = newnode;
}
}
// 打印链表
void PrintList(PNode phead) {
for (PNode cur = phead; cur; cur = cur->next)
cout << cur->val << (cur->next ? " -> " : " -> NULL\n");
}
int main() {
PNode plist = NULL;
ListPushBack(plist, 1);
ListPushBack(plist, 2);
ListPushBack(plist, 3);
PrintList(plist); // 输出:1 -> 2 -> 3 -> NULL
return 0;
}这里有两个点都是C语言数据结构教材使用了,但是在C语言中又没有学到的地方。
第一个是重命名结构体中,后面的 *PNode。
它的意思是,将结构体指针重命名为 PNode,实际等于 typedef struct ListNode *PNode。这种设计想法是好的,极大简化了代码,将 LTNode* plist = NULL 简化为 PNode plist = NULL;,但是如果不理解这种重命名,就可能无法看懂。
第二个是引用,完全是C++的知识,目的也是为了简化代码。
因为空链表插入,要改变头指针本身,所以要传二级指针,才可以去修改。但是在这里使用了引用,直接把头指针传入即可,不需要使用二级指针。
大部分人学生因为习惯了前面的指针写法,看这些代码时,就算是了解了这里的重命名与引用,还是会看得很别扭,这是正常现象。可以看我之前文章的关于链表头插的代码去进行比对,多去书写,自然而然就会感受到,这种写法直接了当的便捷性。
2、引用返回
(1)使用“引用返回”的两条规则
引用做函数返回值时:① 不要将局部变量作为返回值;② 函数的返回值可以作为左值存在;我们直接先来看代码与运行结果,然后再从原理的角度分析。
#include <iostream>
using namespace std;
//引用做函数返回值
//1.不要将局部变量作为返回值
int& test01()
{
int a = 10;//局部变量,存在四区中的 栈区
return a;
}
//2.函数的返回值可以作为左值存在
int& test02()
{
static int a = 10;//静态变量,存放在四区中的 全局区
return a;
}
int main()
{
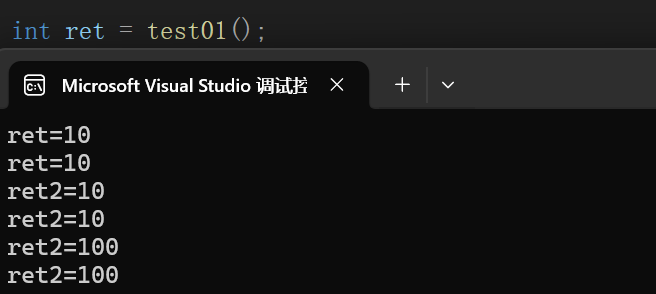
int& ret = test01();
cout << "ret=" << ret << endl;//第一次结果正确,是因为编译器做了保留;
cout << "ret=" << ret << endl;//第二次结果错误,是因为局部变量a被释放了;
int& ret2 = test02();
cout << "ret2=" << ret2 << endl;
cout << "ret2=" << ret2 << endl;
test02() = 100;//如果函数的返回值作为左值,必须使用引用;
cout << "ret2=" << ret2 << endl;
cout << "ret2=" << ret2 << endl;
return 0;
}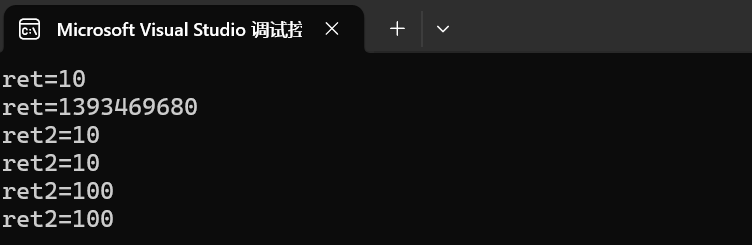
首先第一点就是:不要将局部变量作为返回值。因为局部变量 a 在函数执行结束后,栈空间会被系统回收,变量 a 的生命周期结束,而第一次打印,结果正确,仅仅是编译器做了保留。
我们可以返回静态变量 / 全局变量,因为它们是在全局区的,这里使用了 static 修饰,使其从局部变量变为静态变量,static 变量在程序启动时分配,程序结束时才释放,所以引用始终有效。
这里将静态 a 作一个引用,返回给 ret2,这个 ret2 是 static int a 的别名,所以 a 的值变化时,ret2 的值也会同步变化。
然后第二点就是:函数的返回值可以作为左值存在。其实 test02() = 100; 本质是 a = 100;,只有返回引用时才能这样写。如果返回int,这行代码会编译报错。
那这两条规则是为什么呢?我们依旧是结合上文 “引用的本质” 去看。
(2)两条规则的原理
解释一:② 函数的返回值可以作为左值存在;
先解释一下左值与右值:左值就是可以取地址的,可以被修改的;右值就是不可以取地址的,就像被 const 修饰一样,不能被修改的。
函数返回引用时,“调用表达式” 本身就是原变量的别名,它本身就是别名,它和原变量共享同一块内存地址,也就是上面的 test01()、test02() 本身就是别名。
然后 int& ret2 = test01();,其实就是为 test01() 再找了一个别名,叫作 ret1,因为它是 a 的别名,所以其实 test01() 就是 a ,a 作为一个可以修改的左值,自然可以被赋值。
所以既然 a 是左值,那么 test01() 作为它的别名,也是左值,自然可以被修改、赋值。
总结一下:test () 本身就是 a 的别名。别名 = 就是变量本身 = 是左值。左值 = 能被赋值。所以,test02() = 100;合法。
而普通值返回,这里返回的不是别名,而是 a 的一个临时拷贝值、一个右值,所以不能被赋值。你可以理解成,返回了一个数字 10,而不是变量。
解释二:① 不要将局部变量作为返回值
前面我们说到因为局部变量是存在栈里面,所以函数周期结束的时候,变量被销毁,以至于函数的返回值也被销毁了。
那为什么平时正常 “值返回”,而不是 “引用返回” 的的时候,我使用的也是局部变量呀,但这个时候却可以做到正常地赋值,这是为什么呢?
首先,为什么值返回局部变量是安全的?
当函数返回值时,编译器会做这两步操作:
① 函数执行到 return a; 时,先把局部变量 a 的值(比如 10)拷贝到一块函数调用约定的临时内存区,较小的话,是在寄存器;较大的话,会在其他地方开辟空间存起来。
② 局部变量 a 随函数结束销毁,但临时拷贝的值还在,会被赋值给调用方的变量。
简单说:调用方拿到的是值的副本,和原局部变量已经没关系了,原变量销毁不影响副本。
那么,为什么引用返回局部变量是致命的?
当函数返回引用时,编译器的行为完全不同:
① 函数执行到 return a; 时,不会拷贝值,而是返回 a 的别名(本质是 a 的内存地址);
② 函数结束后,局部变量 a 被销毁,对应的栈内存会被系统回收。虽然 test01() 依旧是 a 的引用(别名),但是这个引用底层对应的指针就会指向无效内存,即悬空引用,等价于野指针。
③ 调用方 main 函数,用 ret 这个变量拿到一个别名 test01(),但是指向的是已被释放的内存,从而形成悬空引用。访问它会读取到随机垃圾数据,导致程序出现未定义行为,甚至崩溃。
总结:
引用返回,我 test01() 本身就是别名,所以可以作为左值修改。
我 test01() 底层是指针,如果它的原变量 a 被释放了,那么它将指向无效内容,从而导致悬空引用,即我是一个无效值的别名,此时再使用这个别名,它出现的就是随机读取的垃圾数据。
举一反三:
所以,此时上面的代码,我只需要做出一个小小的改动,就可以使结果完全不一样。
既然 test01() 本身是别名,那我为什么要在 main 函数里面,还给它一个别名呢,如下图所示,我直接把它赋值给正常变量。
因为第一次赋值,编译器对值作了保留,那么此时 a 的值就赋值给 ret 了,下面再打印,打印的就是 ret 本身 10,而与局部变量 a 无关,与别名 tets01() 也无关。
(四)const 引用
1、具体规则
(1)可以引用一个 const 对象,但是必须用 const 引用。const 引用也可以引用普通对象,因为对象的访问权限在引用过程中可以缩小,但是不能放大。
#define _CRT_SECURE_NO_WARNINGS
int main()
{
const int a = 10;
/*
int& ra = a;
编译报错:error C2440: “初始化”: ⽆法从“const int”转换为“int &”
这⾥的引⽤是对a访问权限的放⼤
*/
//这样才可以
const int& ra = a;
/*
ra++;
编译报错:error C3892: “ra”: 不能给常量赋值
*/
//这⾥的引⽤是对b访问权限的缩⼩
int b = 20;
const int& rb = b;
/*
rb++;
编译报错:error C3892: “rb”: 不能给常量赋值
*/
return 0;
}(2)关于临时对象产生,从而需要 const 引用
int a = 10;
int& rb = a * 3; // ❌ 编译报错
double d = 12.34;
int& rd = d; // ❌ 编译报错
int a = 10;
const int& rb = a * 3; // ✅ 合法
double d = 12.34;
const int& rd = d; // ✅ 合法a * 3 是一个表达式计算,计算结果 30 并不是一个有名字的变量,而是保存在一个临时对象中,它只存在于当前表达式的生命周期内。
d 是 double 类型,要绑定到 int& 引用上,编译器需要先对 d 做隐式类型转换(double → int),转换后得到的整数值(如 12)会被存储在一个临时对象中,而非直接绑定到原变量 d 上。
所谓临时对象就是:编译器需要一个空间,暂存表达式的求值结果时,临时创建的一个未命名的对象。C++中把这个未命名对象叫做临时对象。一般小一点的就在寄存器中,大一点的则会被分配到内存区域中。
而造成临时对象,最典型的就这三种情况:函数传值返回、表达式运算、类型转换。
C++ 规定:临时对象是常量(具有 const 属性),不允许被修改。
你试图用 int&(可读写的普通引用)去绑定一个 const 临时对象时,临时对象为只读权限,int& 为读写权限,这就造成了权限放大,违反了 C++ 的权限规则,所以编译器直接报错。
2、规则理解
我们先要清楚三个概念:指针常量、常量指针、常量指针常量。
指针常量(T* const):指针本身是常量(地址不能改),但指向的内容可以改。比如 int a=10; int* const p = &a; ,p 永远指向 a,但 *p=20 合法。(普通引用的底层实现)
常量指针(const T*):指针指向的内容是常量(内容不能改),但指针本身可以改指向。比如 const int a=10; const int* p = &a; ,*p=20 非法,但 p=&b 合法。
常量指针常量(const T* const):指针本身是常量,指向的内容也是常量,地址和内容都不能改。
简单点可以这样区分,我们用 const 去修饰指针:如果 const 在 * 右边就是指针常量,因为显然先是 * 再是 const;const 在 * 左边就是常量指针,* 左右都有 const 就是常量指针常量。
所以常量变量本身只读,不可被修改,若用普通引用(底层指针常量)引用,会试图获得写权限,属于权限放大,编译器直接禁止。
给引用加 const 后,底层变成 const T* const(常量指针常量),既锁死指向、又锁死内容修改,权限和常量变量完全匹配,无放大问题。
C++ 的权限规则核心是只能缩,不能放,const 引用是实现这一规则的关键语法,底层靠常量指针常量支撑。
一句话总结:无论是上面 “被 const 修饰的变量”,还是 “临时对象”,都是常量。常量如果需要被引用,就需要使用 const 引用,否则就会造成权限的放大。
(五)指针与引用的关系
1、在语法层,引用是一个变量的取别名不开空间,指针是存储一个变量地址,要开空间。
2、使用差异
① 引用在定义时必须初始化,指针建议初始化,但是语法上不是必须的。
② 引用在初始化时引用一个对象后,就不能再引用其他对象;指针可以在不断地改变指向对象。
③ 引用可以直接访问指向对象,指针需要解引用才是访问指向对象。
3、sizeof 中含义不同,引用结果为引用类型的大小,但指针始终是地址空间所占字节个数,32位平台下占 4 个字节,6 4位下是 8byte
4、指针很容易出现空指针和野指针的问题,引用很少出现,引用使用起来相对更安全一些。
所以:在C++中能用引用就用引用,不用指针;在链表、树这些里面不能用引用的,才使用指针。
六、inline(内联)
(一)什么是内联
1、宏定义
因为 C++ 的设计内容是为了弥补 C 语言的不足,所以我们先从 C 语言讲起。
有些函数要被频繁调用,函数调用要建立栈帧,就会有较大的开销。C 语言为了减少函数的栈帧开销,使用了宏函数去处理。
因为实现宏函数会在预处理时替换展开,替换之后它就不是函数了,而是一个具体的表达式,是普通的表达式的话就直接运算。
所以宏函数的优点是:预处理直接替换、没有函数调用、建立栈帧等开销、效率变高。 但是也有确定,宏函数实现复杂、容易出错,且不方便调试。
下面是宏函数的常见问题与正确写法:
#include<iostream>
using namespace std;
// 实现⼀个ADD宏函数的常⻅问题
//#define ADD(int a, int b) return a + b;
//#define ADD(a, b) a + b;
//#define ADD(a, b) (a + b)
// 正确的宏实现
#define ADD(a, b) ((a) + (b))
// 为什么不能加分号?
// 为什么要加外面的括号?
// 为什么要加里面的括号?
int main()
{
int ret = ADD(1, 2);
cout << ADD(1, 2) << endl;
cout << ADD(1, 2) * 5 << endl;
int x = 1, y = 2;
ADD(x & y, x | y); // -> (x&y+x|y)
return 0;
}为什么不能外加分号?
比如这里,int ret = ADD(1, 2);,作为替换会变成 int ret = ( (1) + (2) );;,仅仅是多了一个 ; 而已,这样子就是多了一条空语句,没有任何问题。
但是如果是在 cout << ADD(1, 2) << endl; 中进行替换,变成 cout << ( (1) + (2) ); << endl; 就会出现问题,导致程序的报错。
为什么要加外面的括号?
比如这里,cout << ADD(1, 2) * 5 << endl;,如果不加外括号,展开之后就会变成 cout << (1) + (2) * 5 << endl;,运算符的优先级就会出现问题。原本是先加法再乘法,现在是先乘法再加法。
为什么要加里面的括号?
比如这里,ADD(x & y, x | y);,如果不加内括号,展开之后就会变成 ( x & y + x | y)。原本是希望先与或运算,再相加;现在就变成先相加,再去与,再去或,这样语法运算逻辑就改变了。
2、inline(内联)
正是因为它容易出错,而且在预处理阶段就替换了,导致调试也不方便,所以 C++ 设计了 inline 目的就是替代C的宏函数。
用 inline 修饰的函数叫做内联函数,编译时 C++ 编译器会在调用的地方展开内联函数,这样调用内联函数就不需要建立栈帧了,就可以提高效率。
内联函数就是一个函数,是函数就可以调试;同时既然是一个函数,那么就优先调用函数,然后调用的结果再去进行其他计算,这样就不涉及优先级。
而且它还保留了宏函数的性质,不需要建立栈帧,直接去调用的地方展开。
写的时候当函数去写,也可以正常调试,正常优先调用,这样不容易出错;与此同时保留了宏定义不需要建立栈帧,直接到调用的地方展开的特性,更加高效,这就是内联函数。保留了宏函数的优点,却没有它的缺点。
Tip:inline 替代宏函数;const/enum替代宏常量
(二)内联的书写形式
在函数前面书写 inline 即可,此时该函数为内联函数。
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
inline int Add(int x, int y)
{
int ret = x + y;
ret += 1;
ret += 1;
ret += 1;
return ret;
}
int main()
{
// 可以通过汇编观察程序是否展开
// 有call Add语句就是没有展开,没有就是展开了
int ret = Add(1, 2);
cout << Add(1, 2) * 5 << endl;
return 0;
}(三)内联展开的条件
我们先来讲解一下,展开与不展开的区别是什么。
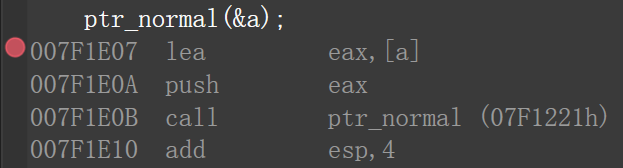
首先,函数编译好后,是一串指令,函数的地址是第一句指令的地址;调用函数的代码,在汇编的层面看它,会有一行 “call(地址)” ,其本质就是跳转过去执行函数的指令,而函数开始的指令就是在为调用的函数建立栈帧。
Tip:下面内容,通过进入代码调试之后,进入反汇编窗口得到。

我们现在假设,函数编译好以后,有10行指令,我们现在调用10000次。
如果函数展开,即关键字 inline 修饰的函数展开,那么就会有 10000*10 行指令,把 10000 个调用的地方替换成这 10 行指令。
如果函数不展开,就有 10000 + 10 行指令,10000 行的 call 和 10 行指令。
所以 inline 的问题是,一定程度上会让编译后的可执行程序变大,可执行程序变大会有一定的缺点。比如我们下载 APP,我们安装的就是可执行程序的压缩包,占用更多的设备内存。
由此可知道,如果是一个很小的频繁调用的函数,内联展开之后,增加的内存还行;但是如果是一个很大的频繁调用的内联函数,这样子内存付出的代价就会比较大,安装包大小上升,导致用户体验可能下降。
所以当时本贾尼博士在设计 inline 的时候,觉得如果任由程序员去控制内联函数是否展开,一旦展开的是一些代码很多的函数、递归函数,那这个时候就会导致程序变得很大,所以大的函数就不太定义为适合。
基于这样一些原因,设计的时候,就让编译器不要去信程序员,要信自己,一个函数定义为内联之后,到底要不要展开,我编译器自己决定,不同的编译器对这个标准的定义不同,一般是10行上下,你超过了这个标准,加了内联,内联也不会展开。
再其次,默认情况下,debug 版本下,内联也不会展开,因为内联展开了就不方便调试了。
展不展开的判断依据是,汇编代码中,调用函数时有没有“call(地址)”。如果有就是不展开,说明还是跳转过去执行指令;如果没有,就是展开了。
我们现在将其归纳为三句话:
① inline 对于编译器而言只是一个建议,也就是说,你加了 inline,编译器也可以选择在调用的地方不展开,不同编译器关于 inline 什么情况展开各不相同,因为 C++ 标准没有规定这个。
② inline 适用于频繁调用的短小函数,对于递归函数,代码相对多一些的函数,加上 inline 也会被编译器忽略。
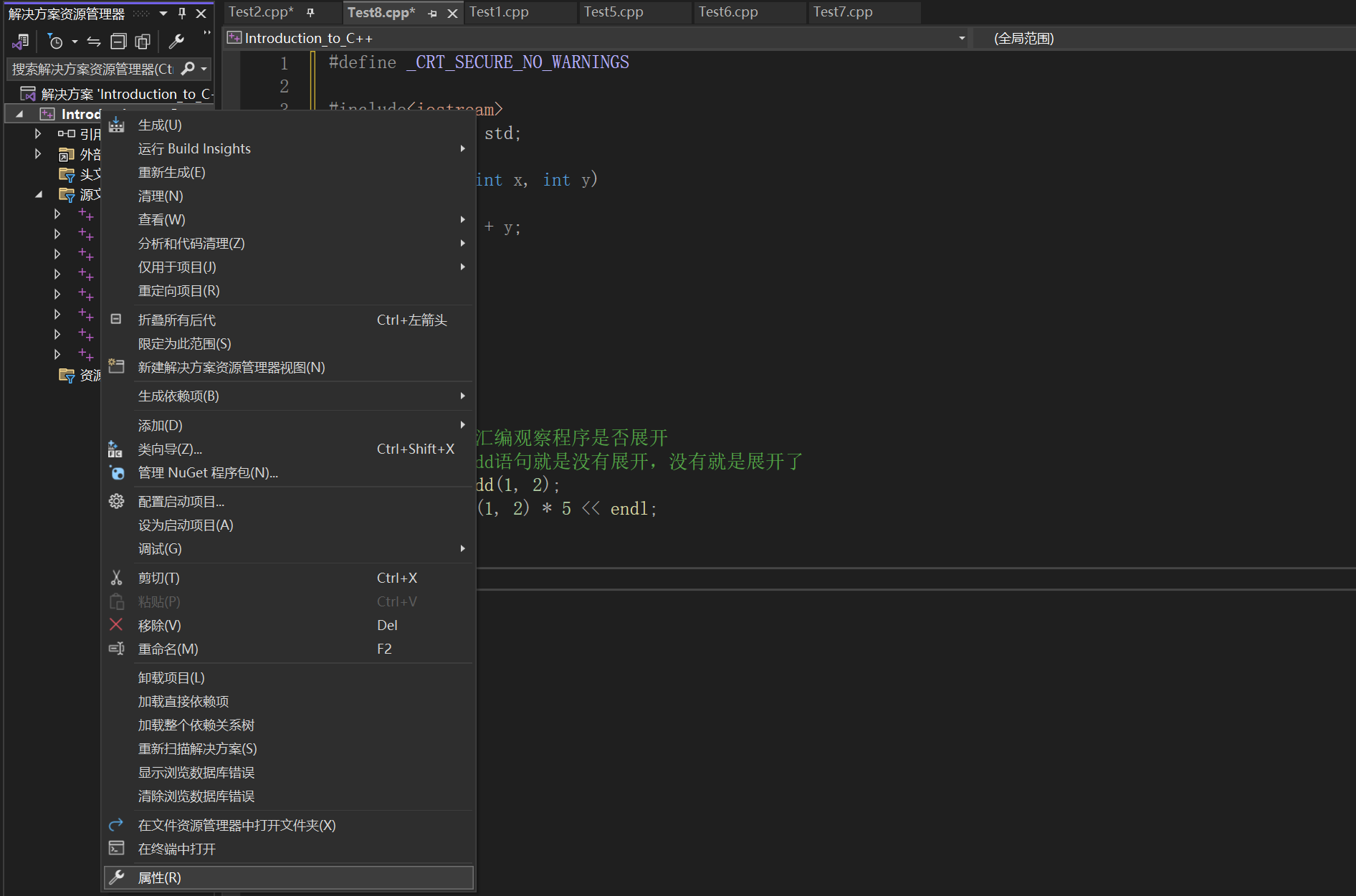
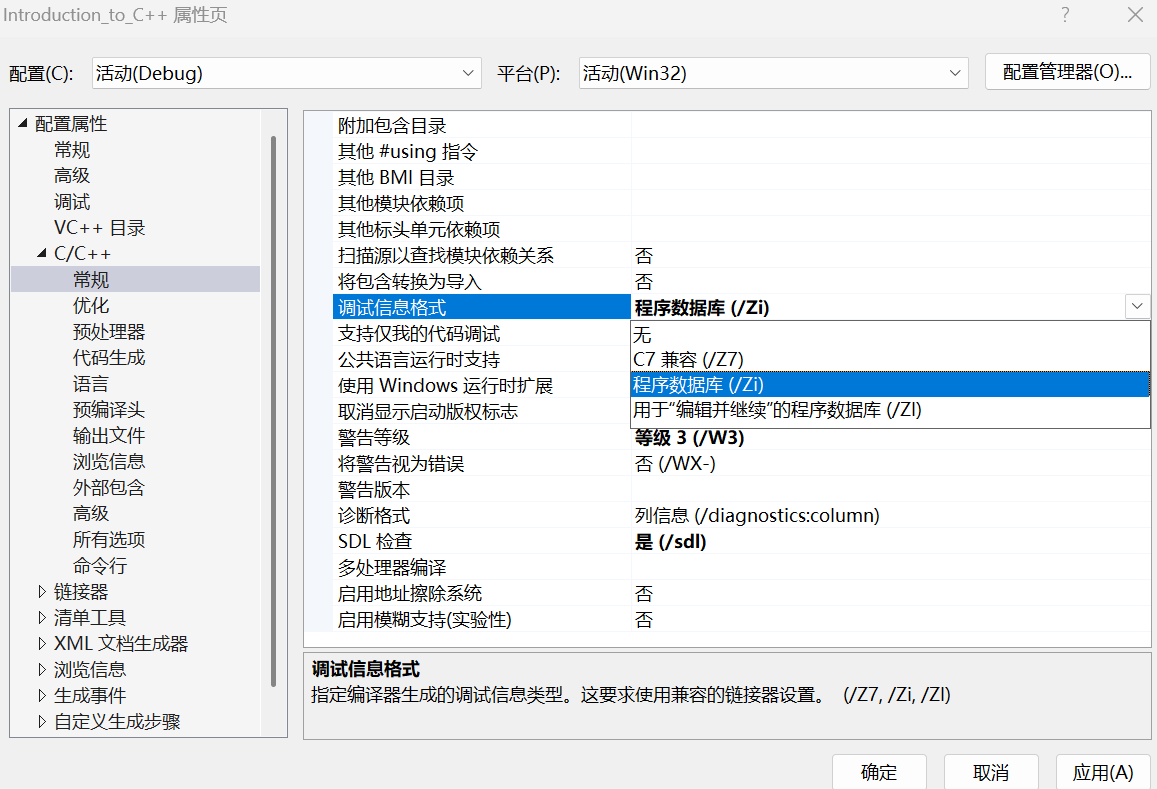
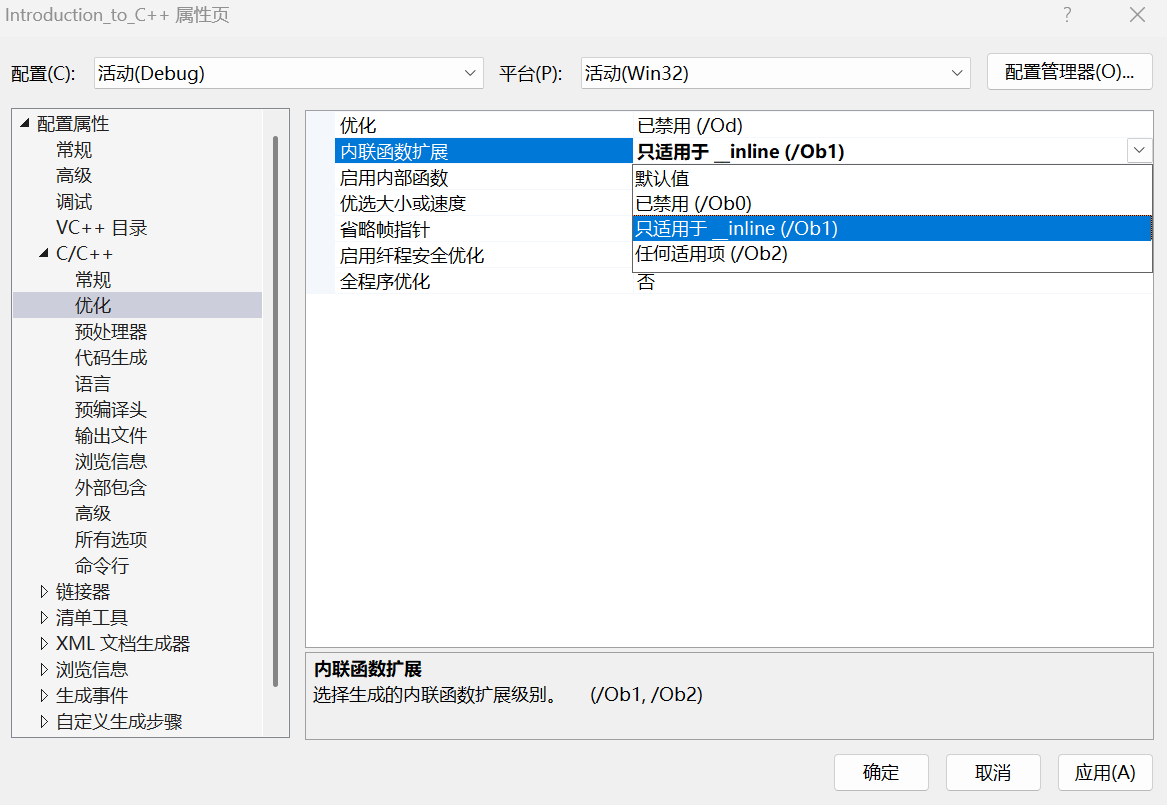
③ vs 编译器 debug 版本下面默认是不展开 inline 的,这样方便调试,debug 版本想展开需要设置一下以下两个地方。按下面的步骤依次操作即可。
(四)内联不能声明与定义分离
为了讲解内联为什么不能声明与定义分离,我们将按以下逻辑进行讲解。
先讲明白,全局函数定义在.h文件,而这个.h文件包含在多个 .cpp 文件,从而导致报错的原因;然后分析这个问题的三种解决方法:使用 static 修饰、声明与定义分离、使用 inline 修饰;最后,分析为什么 inline 修饰时,为什么声明与定义不能分离。
1、全局函数报错案例
我们先来看一个例子,以下是一个 C++ 头文件重复包含导致的函数重定义错误:
// 1、Comcon.h
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
// 2、Stack.h
#pragma once
struct Stack
{
// ...
};
// 3、Stack.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "Comcon.h"
#include "Stack.h"
// 4、Test.cpp
#include "Comcon.h"
#include <iostream>
using namespace std;
int main()
{
return 0;
}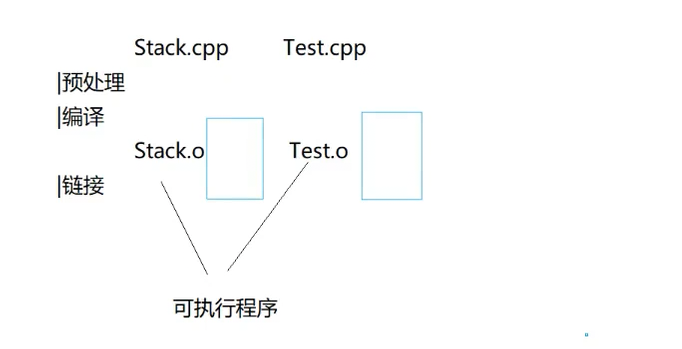
Stack.cpp 包含了 #include "Comcon.h",Test.cpp 也包含了 #include "Comcon.h"。
当编译器编译这两个 .cpp 文件时,Swap 函数的实现会被复制粘贴到两个编译单元里,然后在汇编阶段生成 .obj(Windows)或 .o(Linux)文件。
(1)什么是符号表
.obj 文件里有一个叫做符号表的东西,里面存储:函数名、全局变量名、静态变量名、以及它们在文件里的地址 / 偏移。
整体形式以函数举例就是 “函数名+地址”。
(2)有函数定义才有符号表
如果一个文件里面有函数的定义,那么这个函数就会进入这个文件的符号表,因为符号表的本质就是函数名加它的地址;而函数的地址就是,编译完了之后,一串指令中第一句指令的地址,所以只有定义的地方才会有地址。
只有声明的话,这个函数是不会进入符号表的,没有编译生成的指令,就没有地址;没有地址的话,就不可能进入符号表。
(3)符号表的分类
符号表又分为全局符号表和局部符号表,普通函数和全局变量存储在全局符号表,static 函数、static 变量就存储在局部符号表。(普通函数就是定义在全局的,也可以叫全局函数)
(4)符号表在链接的作用
最后链接时,链接的时候,多个 .obj 文件拼在一起,链接器就是靠符号表找到函数在哪。调用函数时,本来是没有地址的,是 “call Swap(...)”,但我会拿着我的符号,去所有 .obj 的符号表里挨个查,查到了就把地址填进去。从而就实现了函数的调用。
(5)符号表的规则
① 全局符号表中的符号不能重复。多个 .obj 里如果有同名全局符号,报重复定义错误。
② 每个 .obj 自己的局部符号表内部也不能重复。同一个文件里,不能定义两个同名 static 函数 /static 变量,这是编译器直接报错,还没到链接阶段。
③ 不同 .obj 的局部符号之间,可以重名。完全没问题,互不干扰。
(6)报错原因
在 Stack.obj 与 Test.obj 的全局符号表中,有相同函数,各自都有一个 Swap 函数,所以最终链接时就会报 “函数重复定义”。
但是一个 .h 文件在多个 .cpp 文件包含是一件很正常的事情,我们应该怎么解决呢?
2、三种解决方法
(1)第一种解决方法
我们可以通过 static 修饰解决这个问题,因为 static 修饰的内容,只在当前文件可见。
这是静态变量与全局变量、静态函数与全局函数最大的区别,链接属性不同;static 只有内部链接属性,仅在当前文件可见,从某种程度说,可以理解为它不会进入全局符号表。
上面重复的原因是因为,在全局符号表中发现了相同函数,现在两者都不在全局符号表,仅在各自的局部符号表,不发生冲突,自然就可以解决函数重复定义的问题。
static void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}(2)第二种解决方法
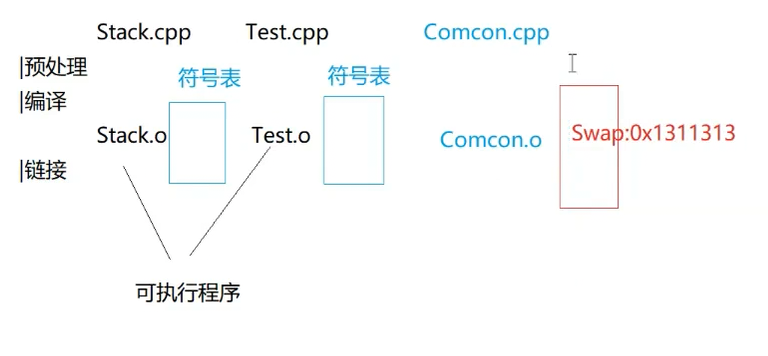
只需声明与定义分离即可,声明写在 Comcon.h,定义写在 Comcon.cpp 中即可解决。
此时,因为 .h 文件中书写的是声明,所以 Stack.cpp 与 Test.cpp 中没有它的定义,自然而然后续就不会进入它们 .obj 文件的符号表。
因为 Swap 函数定义有且仅有一次书写在 Comcom.cpp 中,所以也只会进入一次全局符号表,所以不会造成全局符号表中出现相同内容,从而导致重复定义的问题。
但是只要调用了函数,在链接阶段就会去符号表中去找到地址,从而实现调用。
(3)第三种解决方法
可以通过关键字 inline 修饰解决 “多文件重复定义” 这个问题。
如果编译器成功内联展开,函数不进入符号表;因为调用处直接替换代码,无需通过符号表找函数地址。
如果编译器无法内联展开,函数进入符号表;因为递归调用、取函数地址、编译器认为展开不划算时,会退化为普通函数调用。
但是即便生成符号表,inline 函数也默认是弱符号。多个编译单元定义相同的 inline 函数不会报 “多重定义” 错误,而普通函数是强符号,重复定义会报错。
注意:inline 函数,只有在同一个 .cpp 文件中,同时定义和调用,才会按需生成弱符号。而对于普通函数,只要定义了,就会产生强符号。
总结就是:如果内联展开,不进入符号表,无冲突;如果内联未展开,进入符号表也只是弱符号,多少个弱符号共存不会冲突。
inline void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}3、inline 修饰时,声明与定义不能分离
// 1、Comcon.h
#pragma once
inline void Swap(int& a, int& b);
// 2、Comcon.cpp
#include "Comcon.h"
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
// 3、Stack.h
#pragma once
struct Stack
{
// ...
};
// 4、Stack.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "Comcon.h"
#include "Stack.h"
// 5、Test.cpp
#include "Comcon.h"
#include <iostream>
using namespace std;
int main()
{
int x = 1, y = 2;
Swap(x, y);
cout << x << " " << y << endl;
return 0;
}现在的情况是,inline 函数声明与定义分离,声明在头文件,定义在另一个 .cpp。
即使该函数符合内联展开的标准,但编译调用文件时,编译器只能看到函数声明、看不到函数体,无法完成内联展开,而内联展开需要编译阶段直接嵌入函数体代码,无代码则无法执行。
如果该函数不符合内联展开的标准,本应退化为普通函数调用,但弱符号的生成需要 “当前 .cpp 能看到定义 + 有调用”,才会按需生成。
最终的结果就是:
① 调用文件编译时:看不到函数体,无法生成弱符号;
② 定义文件编译时:若没有内部调用,也不会生成弱符号;
③ 最终链接阶段:“call Swap(...)” 指令需要的函数地址无法从任何 .obj 的符号表中找到。
综上:无论该 inline 函数是否符合展开标准,最终要么因无函数体无法内联,要么因无弱符号无法完成普通函数调用,都会导致链接失败。
4、总结
这就是为什么使用 inline 时,声明与定义不能分离,如果要完全透彻理解,我们要有全局变量和全局函数、static 变量与 static 函数、编译链接、符号表、符号等全方面的知识,才能对这个概念有一个自圆其说的深刻理解。
如果你不关注这些底层,只要记住一句话即可:inline 不可以声明和定义分离到两个文件,分离会导致链接错误。
七、nullptr
(一)空指针与 NULL 的本质
1、什么是空指针与NULL
空指针并非 “无效地址”,它指向内存地址编号为 0 的字节,系统默认将该地址预留为 “未使用状态”,用于指针初始化;若直接访问此地址,程序会触发报错。
NULL 是一个宏定义,在传统C 头文件 stddef.h 中,其定义如下:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif2、空指针与NULL的关系
空指针是一个概念,而 NULL 是 C/C++ 中用来表示空指针的一种实现方式。
空指针本质是 “一个不指向任何有效内存地址的指针”,是编程中对 “无指向” 状态的逻辑描述。就像你有一个地址本,空指针就是地址本里写了 “无地址”,目的是避免指针指向随机内存,即避免野指针。
NULL 是 C/C++ 为了表示 “空指针” 定义的宏常量,但它的底层定义在不同语言中不一样:
C++ 中,NULL 被定义为字面常量 0(整数类型);C 语言中,NULL 被定义为无类型指针常量 (void*)0。
简单来说:空指针是 “想表达的意思”,NULL 是 “表达这个意思的工具”,但这个工具在 C++ 里不好用。
(二)NULL 在函数重载中的类型匹配问题
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
void f(int x)
{
cout << "f(int x)" << endl;
}
void f(int* ptr)
{
cout << "f(int* ptr)" << endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
// 编译报错:error C2665: “f”: 没有重载函数可以转换所有参数类型
// f((void*)NULL);
f(nullptr);
return 0;
}
1、C++ 中的情况
当存在 void f(int) 和 void f(int*) 重载函数时,NULL 的定义会导致类型错配,与预期行为不符,即上面的 f(NULL)。
在 C++ 情况下,NULL 被替换为 0,编译器会优先匹配 f(int) 版本,而非预期的指针版本 f(int*)。若直接使用 f((void*)NULL),会因 void* 到 int* 无法隐式转换而编译报错。
C++中,所以我们唯一的解决方案是:f((int*)NULL)
2、C 语言中的情况
但是如果是C 语言情况下,NULL 被替换为 (void*)0,但 void* 到 int* 是可以隐式转换的,此时可以调用,也就是 C 语言的 NULL 应该是无实质缺陷。
所以在C语言中,接受 malloc 的返回值,甚至都可以不强转,因为会隐式转化,代码我试过了,完全可以跑,至于要求强转,是历史原因与兼容 C++ 编译器,这点就不多做展开了。
3、C++ 不复用 C 语言中 NULL 的逻辑的原因
那既然 C 语言 的 NULL 没有明显缺陷,那为什么 C++ 不复用这套逻辑呢?
首先,C++ 为了提升类型安全性,禁止 void* 隐式转换为其他具体指针类型。
这与 C 语言 NULL=(void*)0 依赖的隐式转换规则完全冲突。如果 C++ 直接沿用 (void*)0 作为 NULL,那么 NULL 将无法正常赋值给 int*、char* 等指针,除非每次都强制转换,这既不便捷也不符合语言设计目标。
其次,函数重载会让 void* 类型的 NULL 产生严重的匹配歧义。
当存在多个指针类型的重载函数时,如有 void f(int*) 和 void f(char*) 两个重载时,f(NULL) 会同时匹配两个版本,编译器无法判断应该调用哪一个,直接导致编译失败。
相比之下,将 NULL 定义为整数 0,虽然会在重载时优先匹配整型参数,但至少能保证编译通过,属于一种兼容性妥协。
4、C++ 的解决方案
为了在保证类型安全的前提下,重新赋予空指针合规的隐式转换能力,同时彻底规避因整数 0作为空指针标识导致的类型匹配错误,C++11 专门引入了关键字 nullptr,作为 C++ 中空指针的标准表示形式。
(三)nullptr
为解决 NULL 的类型歧义问题,以及重新赋予空指针合规的隐式转换能力,C++11 引入了新关键字 nullptr。
1、类型特性
nullptr 是特殊指针类型字面量,它的特性是 “可以隐式转换为任意指针类型(如 int* / char* / float* 等),但本身不属于任何一种具体指针类型。
使用 nullptr 定义空指针可以彻底避免类型转换问题:它只能被隐式转换为指针类型,而无法转换为整数类型,从根源上杜绝了 NULL 被当作整数 0 参与重载匹配的风险。
2、重载匹配
(1)在 f(int) 和 f(int*) 重载中,f(nullptr) 会精准匹配 f(int*),完全符合空指针调用的预期,不会像 NULL 那样误匹配到 f(int) 版本。
(2)错误匹配问题
但在 f(int* ptr) 和 f(char* ptr) 这类 “多指针类型重载” 中,f(nullptr) 会直接编译报错 —— 提示 “对重载函数的调用不明确”。
这是因为 nullptr 转换为 int* 或 char* 的匹配优先级完全相同,编译器没有任何依据选择其中一个,因此会主动暴露歧义而非静默出错,这正是 C++ 类型安全设计的体现。
3、使用建议
在 C++ 开发中,空指针初始化应优先使用 nullptr,彻底规避 NULL 带来的类型歧义与重载匹配问题;C 语言因无此关键字,仍需依赖 NULL 宏。
同时,在存在不同指针类型重载的函数中,若需传入空指针,应显式指定目标指针类型。
如 f((int*)nullptr),避免因 nullptr 转换优先级相同而导致的编译歧义,保证代码意图清晰、行为可预期。
C++ 初步入门小结
以上便是我们进行 C++ 学习的初步入门阶段,但这还并非完整意义上的入门 —— 真正踏入 C++ 大门 ,要等到要到学完下一个核心章节的 “类和对象”。
初步入门阶段的内容较多且深入,需要扎实的底层认知与充足的代码实践,才能彻底掌握。
计算机学习是一环扣一环的,上一环节的知识和想法,直接影响到下一环节的知识和想法,任何环节都不能囫囵吞枣或降低要求,必须深刻掌握,否则越往下学习会越困难。
反之,若在初始阶段多下些功夫,搞明白原理,捋清楚关系,看似进度不快,却能为后面学习的加速打下坚实的基础。越到后面,越能体会到 C++ 的方便与高效。
贯穿这些初步入门知识的核心思路,其实就是对 C 语言短不足系统性弥补。
1、命名空间:解决了全局作用域下的命名冲突问题;
2、 C++ 输入 & 输出:让数据交互更简洁、类型更安全;
3、缺省参数:让函数调用更灵活,支持默认参数值;
4、函数重载:让同一个函数名适配不同参数,调用时不用记多个名字,接口更统一;
5、引用:既规避了指针传参的绕圈与风险,又实现了高效传参与实参直接修改;
6、内联函数:替代了易出错、难调试的宏函数,兼顾了性能与可读性;
7、nullptr:彻底解决了空指针的类型歧义问题,让指针语义更严谨、重载匹配更可靠。
以上即是 一篇文章入门 C++(三万字长文,从用法到底层原理,全面分析) 的全部内容,创作不易,麻烦三连支持一下呗 ~


葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐

 50
50 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)