Hermes Agent 一个多月使用心得:一个可以持续进化的 AI 代理
它不是替代你的工具,而是放大你能力的杠杆。你不必学一套新的命令语法——直接说人话就好。你不必担心记住学过的技巧——Hermes 的 Skill 和 Memory 替你记。你不必被某个模型或平台绑定——随时可以换。对于一个技术工作者来说,Hermes 的工作流非常自然:你来决策(做什么),它来执行(怎么做);你做一次,它记住重复做;你趟过的坑,它帮你写成文档。当然它也有不完美的地方——Skill 的
从"什么都能干"到"越用越顺手"——我的 Hermes 使用之旅
一、初识 Hermes
最早听说 Hermes Agent,是看到 Nous Research 开源的一个终端 AI 代理。当时想着"这不就是又一个 Claude Code 的竞品吗"——直到真正用起来才发现,它走的完全是另一条路。
Hermes 的定位可以这么理解:它不是帮你写代码的工具,而是一个能接管你终端的智能代理。你在终端里能做的一切——查文件、跑脚本、调用 API、操作数据库、管理服务器——Hermes 都能做,而且它能记住你在做什么,能从错误中学习,还能把你的工作流固化成可复用的"技能"。
安装只需一行命令:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
然后 hermes 回车,就进入了一个对话式的终端工作环境。
二、架构概览:不只是"调 API"
Hermes 的核心架构可以用一张图概括: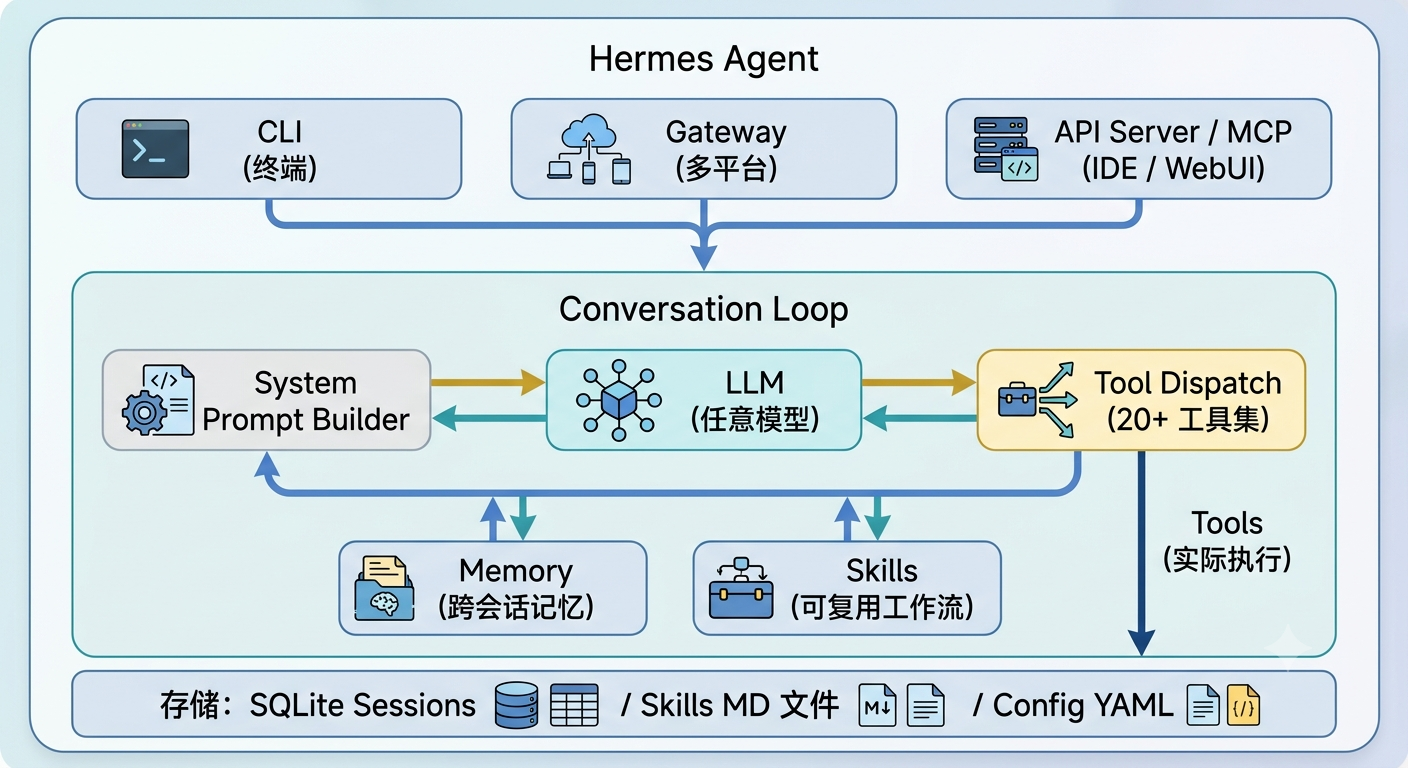
关键组件的理解
1. Provider 无关性
Hermes 最让我惊讶的一点是,它完全不绑定某个模型。我用 hermes model 可以随时在 DeepSeek、OpenRouter、Anthropic 之间切换,甚至同一个会话中途换模型都行。这意味着可以针对不同任务选择最合适的模型——日常用便宜的,复杂推理切到更强的。
2. 20+ 工具集,按需启用
工具集是 Hermes 的能力单元,通过 hermes tools 可以精细控制:
- 💻 terminal — 执行 Shell 命令(核心中的核心)
- 📂 file — 读写、搜索、编辑文件
- 🌐 web / browser — 网页搜索和浏览器自动化
- 🧠 memory — 跨会话持久记忆
- 🧩 skills — 技能管理和自动加载
- 🤝 delegation — 子代理任务委派
- 📅 cronjob — 定时任务
- 🔍 session_search — 回顾历史会话
每个工具集都可以按平台单独启用/禁用,这在 Telegram/Discord 等消息平台上尤其重要。
3. Skills:把经验固化成代码
这是 Hermes 最独特的设计。当一个工作流经过验证后,可以保存为一个 Skill(Markdown 格式的规范文档)。下次遇到类似任务,Hermes 会自动加载对应的 Skill,按照其中记录的步骤执行。Skill 会持续积累,并且可以随时修补——用过一次发现缺了步骤?skill_manage(action='patch') 更新即可。
三、实际使用场景
场景 1:集成企业内部 API
Hermes 的 Skill 机制让我能封装公司内部的各种 API 为可复用的"能力"。我目前运行着 5 个自定义 Skill:
| Skill | 能力 | 底层 API |
|---|---|---|
| room-booking | 会议室查询、预约、取消、我的会议列表 | 会议室管理系统 API |
| dinner-booking | 餐食订购、余额查询、配送地址管理 | 餐食订购系统 API |
| iot-control | 设备查询/控制、产品查询、设备模型查询、指令下发 | 物联网控制中心 API |
| scene-power | 定时任务规则查询与执行 | 场景控制 API |
| sport-query | 运动场地查询(按 ID 递归查子孙/按名称模糊搜) | 空间 API |
每个 Skill 都是一个 Python 脚本 + Markdown 文档的组合。以会议室预约为例,使用体验是这样的:
我:"下午2点到3点帮我预约1号会议室"
Hermes (加载 room-booking Skill):
→ 调用 book_room.py book --name "1号会议室" --start "14:00" --end "15:00"
→ 返回预约成功
背后涉及的 API 调用细节、认证逻辑、错误处理全部由 Skill 封装,我只需要说人话。
场景 2:多平台接入
Hermes 的 Gateway 支持将同一个代理接入到 Telegram、Discord、Slack、企业微信、钉钉等十多个平台。配置方式很简单:
hermes gateway setup # 交互式配置
hermes gateway start # 启动后台服务
我在 Telegram 上也能用 Hermes 查会议室、订咖啡,和在终端里效果完全一样。这对移动办公场景特别实用——手机上发条消息就能办事。
场景 3:定时任务自动化
cronjob 工具让 Hermes 可以按计划自动执行任务。比如:
- 每天早上 9 点检查服务器磁盘使用率
- 每周一发周报汇总
- 定时查询会议室可用性
这些任务执行完毕后,结果会自动投递回到当前会话或指定平台。
场景 4:子代理并行工作
delegate_task 可以将复杂的任务拆分为多个并行的子任务交给独立的子代理处理。例如需要同时查询设备的在线状态、物模型信息和所属空间时,可以并行下发三个子任务,各自独立执行,结果汇总后一次性返回。
四、与同类工具对比
| 特性 | Hermes Agent | Claude Code | OpenAI Codex CLI |
|---|---|---|---|
| 模型无关 | ✅ 20+ 提供商 | ❌ 仅 Anthropic | ❌ 仅 OpenAI |
| 跨平台网关 | ✅ 10+ 平台 | ❌ 仅终端 | ❌ 仅终端 |
| 持久记忆 | ✅ 内置 + 可插拔 | ❌ 无 | ❌ 无 |
| 技能系统 | ✅ 可积累可修补 | ❌ 无 | ❌ 无 |
| 子代理 | ✅ 支持 | ❌ 无 | ❌ 无 |
| 定时任务 | ✅ 内置 | ❌ 无 | ❌ 无 |
| MCP 协议 | ✅ 服务端 + 客户端 | ✅ 客户端 | ❌ |
| 开源 | ✅ MIT | ❌ 专有 | ⚠️ 部分开源 |
| 个人资料 | ✅ 多 Profile 隔离 | ❌ | ❌ |
Hermes 最大的差异化优势在于:
- Provider 无关——不会被单一模型锁定,可以按成本/能力灵活选择
- 技能积累——越用越聪明,每次解决问题都是在为未来的自己铺路
- 全平台覆盖——终端、手机、IDE 同一个人工智能代理
五、遇到的一些坑和经验
1. Skill 需要写到位
Skill 文档的好坏直接决定了 Hermes 能不能正确使用。好的 Skill 应该包含:
- 触发条件(什么时候该用这个 Skill)
- 精确的命令和参数说明
- 已知限制和边界情况
- 完整的示例用例
- 错误处理方案
一开始我写的 Skill 太简略,Hermes 经常猜错参数用法。后来把记忆中的约束条件写进 SKILL.md 里(比如"app-id 是必填参数"、“recommend 有时段限制需要直约”),准确率大幅提升。
2. 配置项要合理
Hermes 的 config.yaml 有大量配置项。最值得注意的几个:
approvals.mode— 命令审批模式。smart模式最均衡:低风险命令自动放行,高风险命令询问确认delegation— 子代理的模型和参数配置,复杂任务可以让子代理用更强的模型compression— 上下文压缩策略,长会话下自动压缩历史,保持模型在最佳上下文窗口内
3. 记忆 vs 技能如何取舍
刚开始我经常困惑"这东西该存 Memory 还是该写成 Skill"。用久了总结出一个原则:
- Memory → 事实性信息:用户偏好、环境细节、API 端点、项目背景
- Skill → 流程性知识:复杂任务的执行步骤、多工具组合的工作流、踩过的坑
它的判断标准很简单——下次另一个完全相同的情况下,你需要的是"知道某个事实"还是"知道怎么做"?前者归 Memory,后者归 Skill。
Memory 还应该保持精简,只保存那些"未来还会用到"的事实。任务进度、临时状态这种东西应该交给 session_search 去历史对话中查找,塞进 Memory 只会污染记忆。
六、总结
用 Hermes 几个月最深的感受是:它不是替代你的工具,而是放大你能力的杠杆。
你不必学一套新的命令语法——直接说人话就好。你不必担心记住学过的技巧——Hermes 的 Skill 和 Memory 替你记。你不必被某个模型或平台绑定——随时可以换。
对于一个技术工作者来说,Hermes 的工作流非常自然:你来决策(做什么),它来执行(怎么做);你做一次,它记住重复做;你趟过的坑,它帮你写成文档。
当然它也有不完美的地方——Skill 的编写有一定门槛,自动加载的准确性还有提升空间,长会话下的 Token 消耗也比较大。但它确实是目前我见过最接近"通用 AI 代理"这个理念的开源实现。
如果你还在犹豫要不要试,我的建议是:装一个,给它喂一个你日常要做 3 步以上的任务,看看它能不能自己搞定。很有可能,你就回不去了。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)