如何使用缓存把大模型薅出白菜价
摘要: 大模型应用中,重复计算系统提示词导致成本激增。某团队因每次请求都重新处理相同的5,000 token提示词,月账单高达$5,000;接入Prompt Cache后,成本骤降至$800,降幅84%。主流模型厂商(如DeepSeek、OpenAI、Claude)的缓存价格仅为普通输入的1/10至1/50,但需开发者优化请求结构以命中缓存。 核心机制:Prompt Cache复用Prefill阶
先说一个让人有点坐不住的账单。
一个用 Claude Code 的开发团队,某个月一对账:$5,000。不是因为他们用得多,是因为每次请求都在重复一件很蠢的事情——把同一份 5,000 token 的系统提示词,一遍遍塞给模型重新算。用户问了个新问题,模型却要把它早就"见过"的那堆内容重新过一遍,过完才给答案。然后下一次,继续。
接入 Prompt Cache 之后,同样的工作量,账单变成了 $800。
足足降了 84%。代码没改,需求没变,只是不再做那些没必要的重复计算而已。
先看价格,再聊技术
既然讲的是成本问题,在展开技术细节之前,先看看主流大模型厂商的定价结构是什么样的。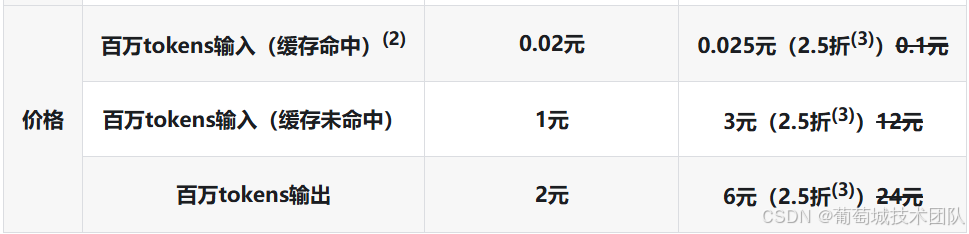
(DeepSeek 截至 2026/05/13 定价截图 两列分别为 V4-flash V4-Pro价格)
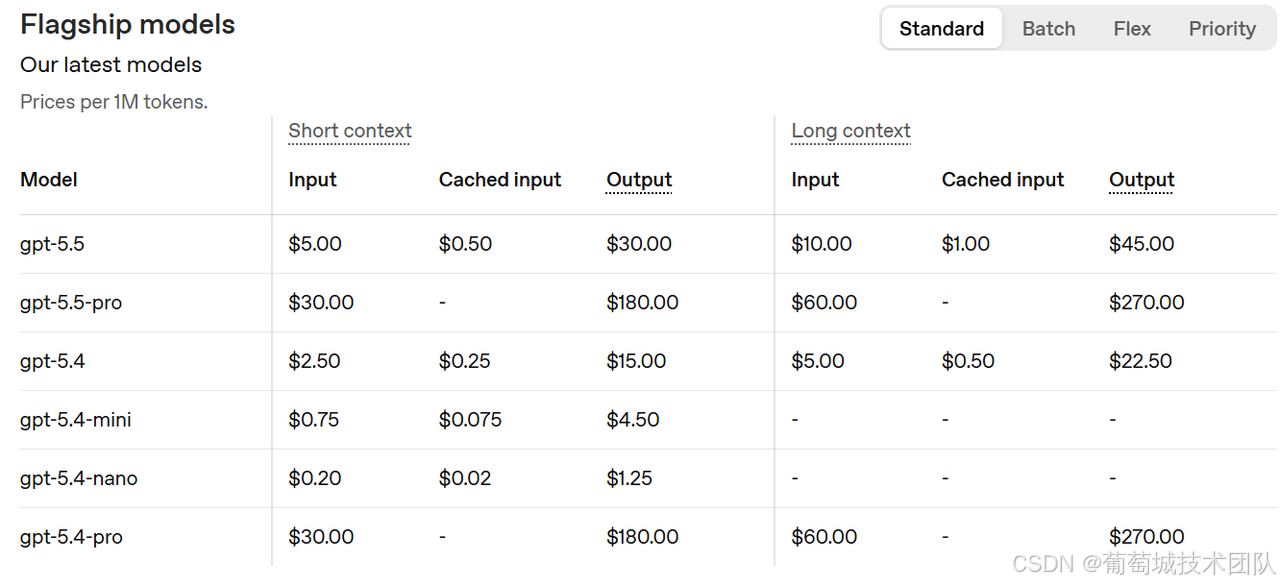
(OpenAI 截至 2026/05/13 定价截图)
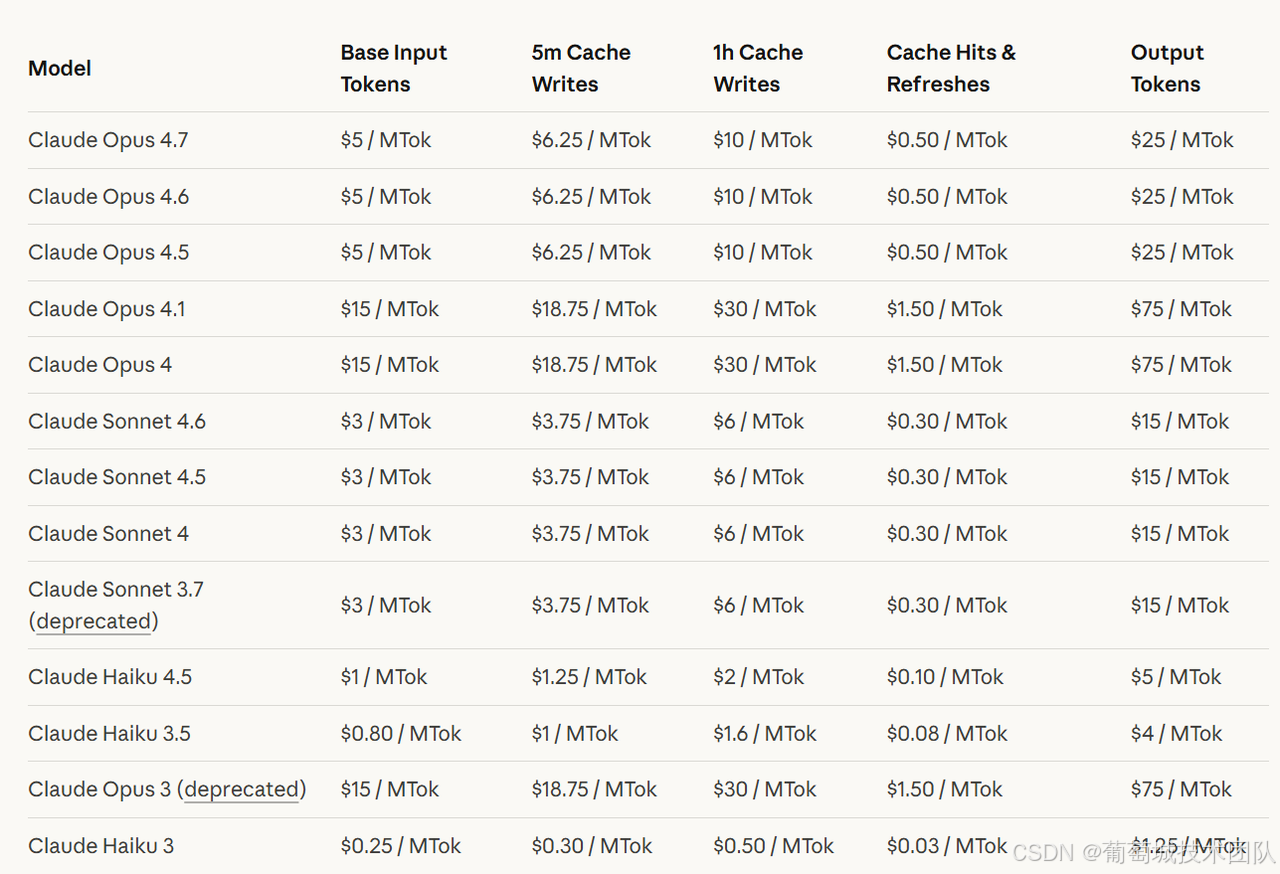
(Claude 截至 2026/05/13 定价截图)
除了常规的输入/输出定价之外,各家都提供了缓存价格。比例相当夸张:DeepSeek 的普通输入价格与缓存命中价格之比能到 50:1,OpenAI 和 Anthropic 是 10:1。换句话说,同一套应用,全走缓存的成本,是完全不走缓存的十分之一。
但缓存能不能命中,厂商不会替你保证,得开发者自己操心——就像数据库索引,建了归建了,写法不对,查询照样走全表扫描。真正懂行的开发者会针对缓存原理对智能体平台做定向改造,这是在成本上拉开竞品差距的核心手段之一。
两种缓存
在 AI 智能体场景里,"缓存"这个词其实在描述两件完全不同的事,很容易混在一起搞错。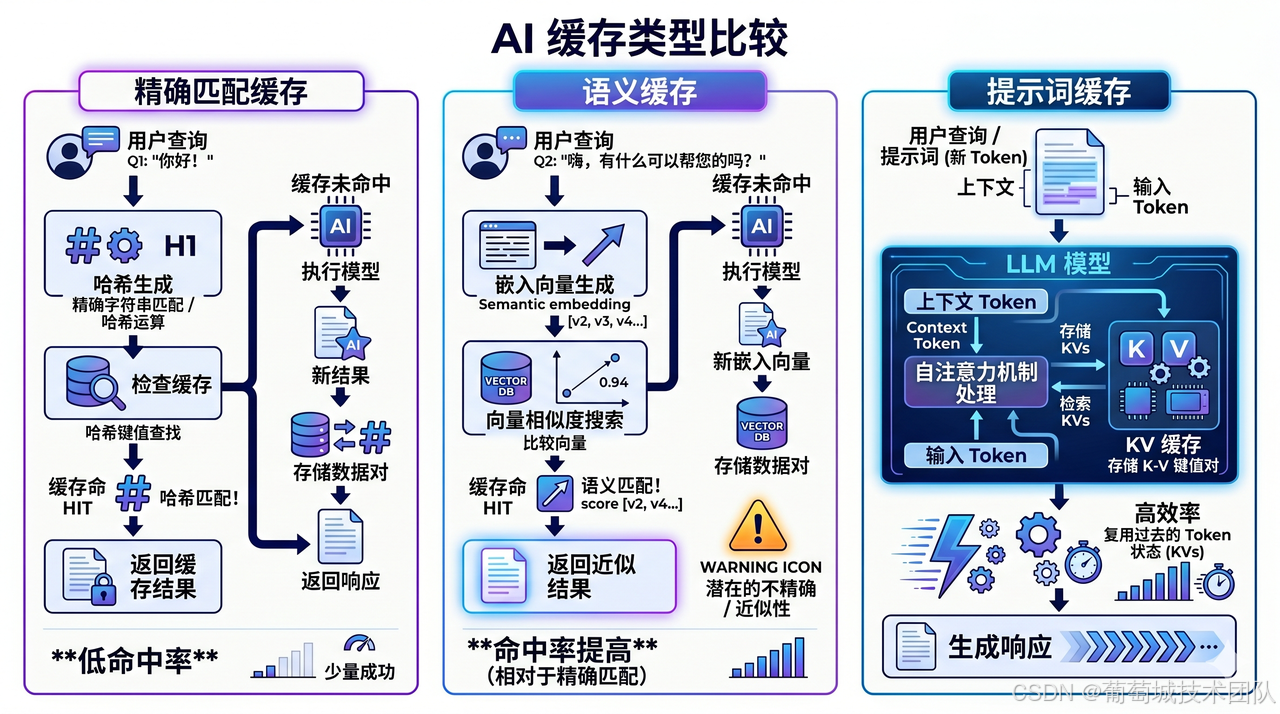
智能体缓存,是应用层的缓存策略,分两类:
精确匹配缓存,做法是把完整的提示词字符串哈希之后存进 Redis 或 SQLite,下次请求只要字节级完全一致就直接返回存好的回复,不调用任何模型。问题是在动态 Agent 环境里,提示词往往夹着实时时间戳、会话 ID、动态追加的历史对话,真正完全一致的概率几乎为零,命中率基本趋近于零。
语义缓存,把用户输入转成向量,计算和历史查询的余弦相似度,超过阈值就返回历史回复。对"换个说法问同一个问题"的场景挺好用,输入输出两端的成本都能省。但有个致命伤:遇到需要多步推理或生成代码的 Agent,它直接截断了模型结合最新上下文动态思考的路径,很容易导致逻辑断层或者上下文幻觉。
提示词缓存,才是本文真正的主角,维度完全不同。它不在应用层,而是深度嵌入模型提供商的基础设施层。它缓存的不是最终的输出文本,而是模型内部处理稳定提示词前缀时产生的中间计算状态——KV 矩阵。命中缓存时,模型依然会针对新的用户指令动态推理、生成全新的回复,只是大幅跳过了重复处理那一大截前置提示词的物理计算开销。
在成熟的企业级架构里,最好的做法是两层叠在一起用:应用层用语义缓存拦截那些高频、同质的短查询,模型层用 Prompt Cache 给复杂的 Agent 长线决策提供低成本的算力底座。
Prompt Cache 的工作原理
大模型推理流程
想搞懂 Prompt Cache 的价值,得先知道大模型推理分两个阶段:
Prefill:模型收到一大坨 token 序列,里面包含系统指令、历史对话、用户查询。它要把这些 token 并行塞进深层的 Transformer 网络,通过多头注意力机制为每个 token 算出键张量(Key Tensors)和值张量(Value Tensors),合称 KV Cache。这个阶段是典型的计算密集型任务,复杂度随输入长度呈二次方(O(N²))爆炸式增长——输入越长,计算量越可怕,这也是长上下文任务里首字延迟容易飙升的根本原因。
Decode:预填充完成后,模型拿着刚才算好的 KV Cache 当记忆底座,一个 token 一个 token 地自回归生成输出。这个阶段是内存带宽的活儿(逐步访存 GEMV),GPU 利用率反而偏低——很多人以为瓶颈在 Prefill,其实真正的延迟瓶颈往往藏在这里。
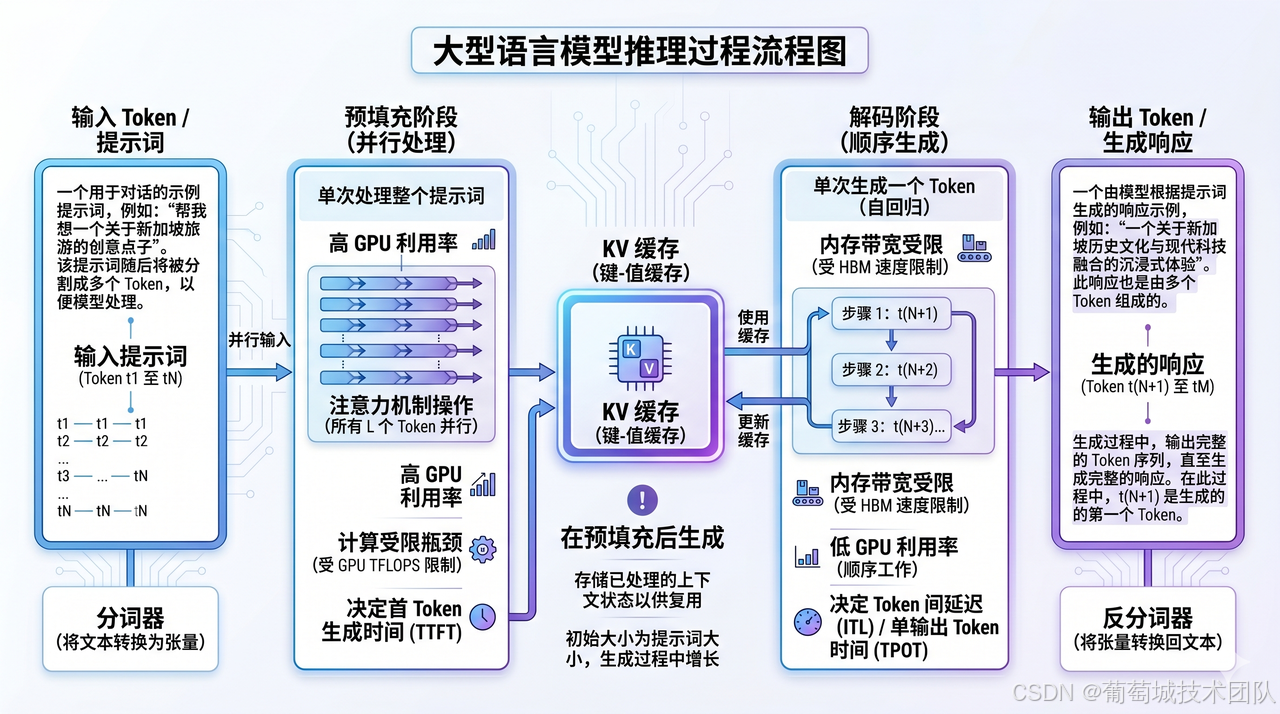
缓存跨请求复用
提示词缓存的核心机制,说白了就一件事:把 Prefill 阶段产生的 KV Cache 张量保存下来,下次请求直接拿来复用。
你的系统提示词今天和昨天一样,明天还一样。但每次请求一来,模型都要从头算一遍,算出完全相同的 KV 矩阵。这不是慢的问题,是纯粹的浪费。提示词缓存解决的不是"prefill 太慢",而是"为什么要重复算同一件事"。
其实 Decode 阶段早就有 KV Cache 了——模型每生成一个新 token,都需要访问前面所有 token 的 K/V 矩阵,如果每步都重算,效率极差,所以直接把这些矩阵缓存在显存里,Decode 时直接读取。但正常情况下,这个缓存撑不过单次请求。请求结束就清空,下次哪怕是完全相同的系统提示词,也得从头算。
Prompt Cache 做的事,是把这份 KV 矩阵跨请求保存下来。
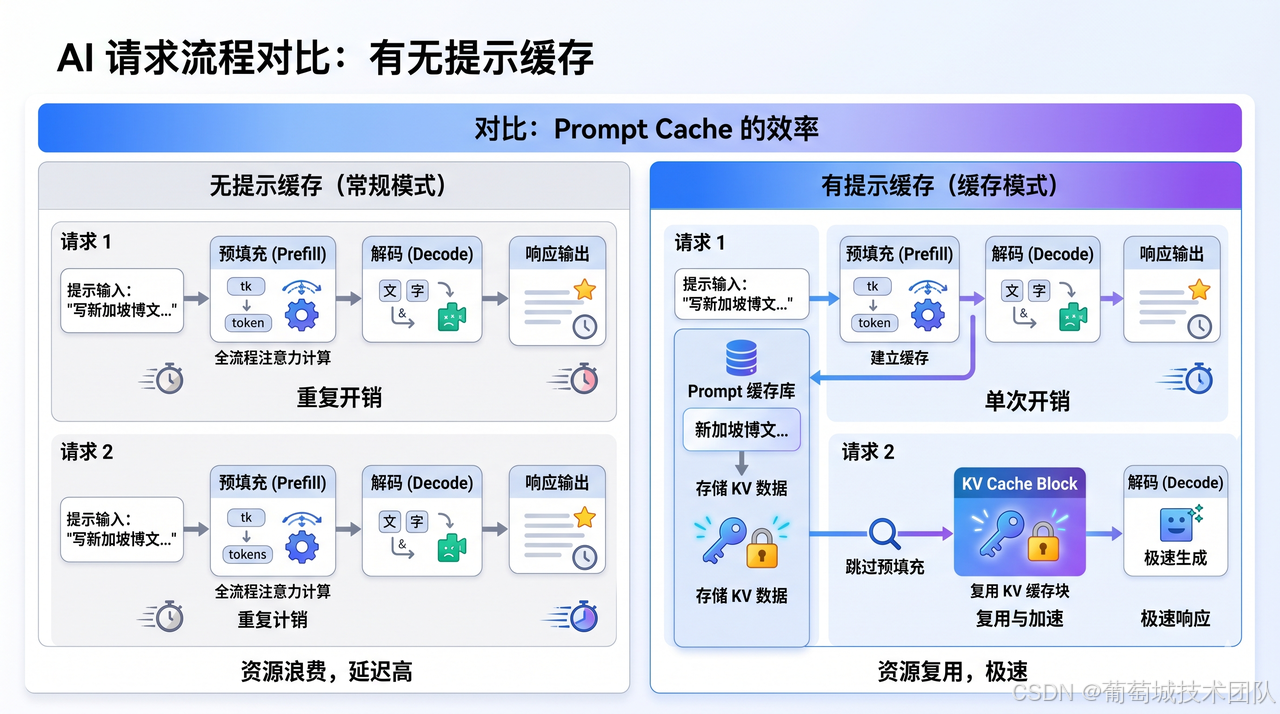
各家厂商的实现路径差别不小,没有统一标准,这里不深挖细节。但有一点挺有意思:Anthropic、OpenAI 这类厂商目前仍然用显存存储 KV 矩阵;而 DeepSeek 通过底层自研,在保证低延迟的前提下,把 KV 矩阵下放到了 NVMe 硬盘阵列,彻底绕开了显存的容量瓶颈——相比昂贵的显存,硬盘层级的存储成本几乎可以忽略不计。这也能解释文章开头定价图里那个问题,为何 DeepSeek 相比国外几个厂商在价格方面会如此慷慨。(还有 MoE 等黑科技因素,不得不说,作为幻方量化子公司,DeepSeek 团队真的非常擅长压榨硬件成本。)
作为用户,我们最终看到的缓存成本差距大概是:十分之一。这不是调参意义上的"优化",这是量级上的差别。
命中缓存的关键:严格前缀匹配
搞清楚原理,接下来最关键的问题是:怎么让缓存真正命中?
对于绝大多数平台来说,缓存遵循严格的前缀匹配。 在推理过程中,每个 token 的 K/V 值由它之前所有 token 共同决定,这就意味着:
如果系统提示词的第 500 个字符被动了,第 501 个字符起的所有 KV 值,全部作废。
哪怕就是多了一个空格。哪怕只是把逗号改成了句号。
举个具体的反例:同样的系统提示词,A 版本把当前时间的时分秒时间戳放在第一行,B 版本把它放在最后一行。跑同样的一万次请求,两个版本的成本可以相差十倍——A 版本第一行每次都在变,后面所有内容的缓存每次全部作废,命中率归零;B 版本前面的内容稳定不动,每次都能命中。
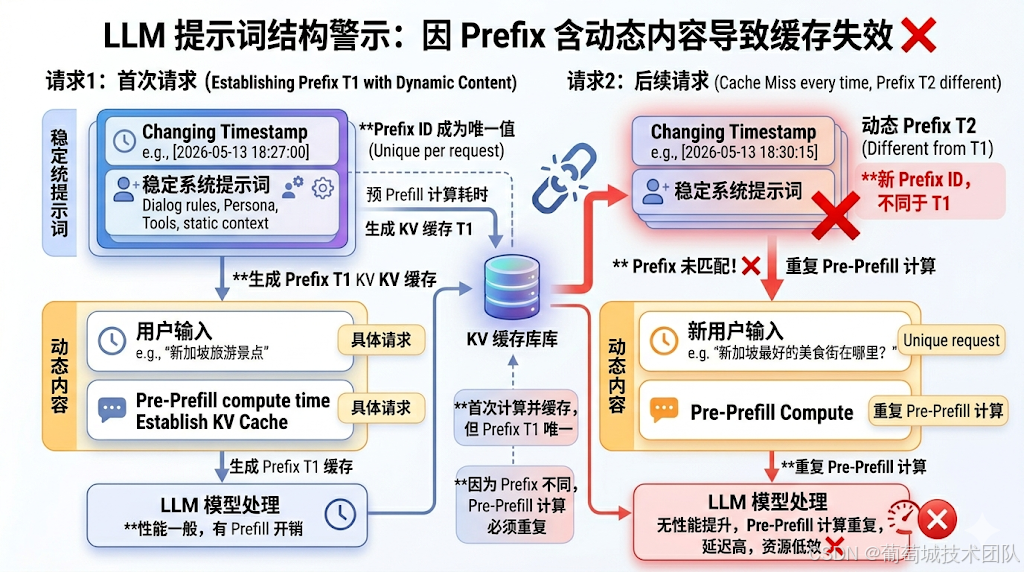
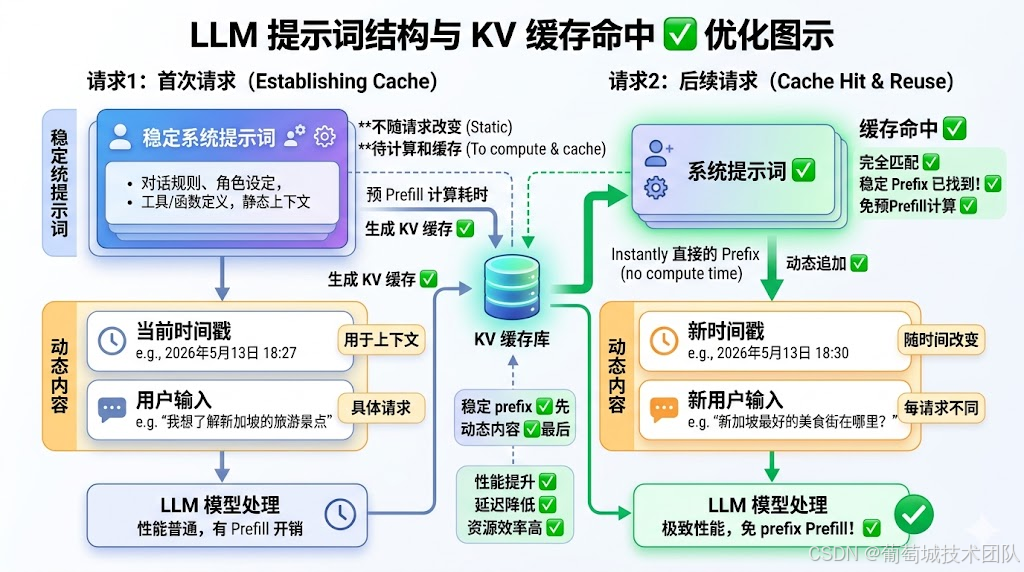
所以原则就一条:变化的内容,永远放在最后。
┌─────────────────────────────────┐
│ 系统提示词(角色、规则、背景) │ ← 稳定,参与缓存
│ Few-shot 示例 │ ← 稳定,参与缓存
│ Tool schema 定义 │ ← 稳定,参与缓存
│ 固定参考文档 │ ← 稳定,参与缓存
├─────────────────────────────────┤ ← 缓存断点
│ 用户当前输入 │ ← 每次不同,不缓存
│ Tool 调用结果 │ ← 每次不同,不缓存
│ 实时状态 │ ← 每次不同,不缓存
└─────────────────────────────────┘
创建缓存:显式 vs 隐式
各家创建缓存的机制不一样。OpenAI 是隐式的——提示词超过一定 token 阈值后,平台自动帮你建好缓存,开发者什么都不需要做。Anthropic 是显式的——要主动调用缓存接口,还需要额外付 1.25x 的写入费用(没错,建缓存本身要花钱)。
以 Anthropic 为例,显式创建缓存的方式是在请求里加 cache_control 标记:
response = client.messages.create(
model="claude-opus-4-5",
max_tokens=1024,
system=[{"type": "text","text": "你是一个专业的代码审查助手,精通 Python、Go 和 Rust...",},{"type": "text","text": "<tools>...大量工具定义...</tools>","cache_control": {"type": "ephemeral"} # 在这里打断点}],
messages=[{"role": "user", "content": user_input}])
断点之前的所有内容会被缓存,之后的不会。Anthropic 目前最多允许 4 个断点,要合理分配给系统提示词、示例、文档、tool schema 这几个层级,超出的标记会被直接忽略——很多人踩坑了才后知后觉。
这个差异背后有其道理:Anthropic 和 OpenAI 的 KV Cache 住在昂贵的 GPU 显存里,如果随便让用户创建长时间缓存,算力压力会相当恐怖。DeepSeek 通过技术优化把 KV Cache 下放到了 NVMe SSD,存储成本大幅压缩,所以他们的缓存定价可以做到接近免费。选型时这几点差异得放在心上。
用对 Prompt Cache 的五件事
前面讲的是原理,真正落到工程里,关键不是"知道缓存很便宜",而是把请求组织成真的能命中缓存的样子。可以按下面五件事改。
1.把 Prompt 当成分层结构,而不是一整坨字符串
很多团队的问题不是没有用缓存,而是把系统提示词、用户输入、实时状态、工具结果混在一个模板里拼。这样看起来代码很简单,缓存却很难命中。
更好的做法是先把提示词拆成四层:
stable_system = """
你是一个企业知识库助手。
回答必须引用资料来源。
如果资料不足,明确说不知道。
"""
stable_examples = """
<examples>
<example>用户问产品价格时,必须优先引用 pricing.md。</example>
<example>用户问合同条款时,必须引用 legal.md。</example>
</examples>
"""
stable_tools = render_tool_schema(tools) # 工具定义,稳定
stable_docs = render_fixed_docs(doc_version) # 固定参考文档,稳定
dynamic_state = {"user_id": user.id,"now": current_time,"locale": user.locale,}
然后组装请求时,稳定层永远放前面,变化层永远放最后:
system = [{"type": "text", "text": stable_system},{"type": "text", "text": stable_examples},{"type": "text", "text": stable_tools},{"type": "text","text": stable_docs,"cache_control": {"type": "ephemeral"},},]
messages = [{"role": "user","content": f"""
当前用户状态:
{json.dumps(dynamic_state, ensure_ascii=False)}
用户问题:
{user_input}
""",}]
这个结构的好处是,后面要加时间戳、会话 ID、AB 实验分组,都只会污染最后一小段动态内容,不会把前面几千甚至几万 token 的缓存一起打碎。
实操里还有一个小细节:稳定层最好由代码生成,不要由多个模块临时拼接。比如 tool schema 的字段顺序、JSON 缩进、换行符如果每次都不一样,也会造成看不见的缓存抖动。最稳的方式是对稳定块做一次规范化序列化:
def canonical_json(value: dict) -> str:return json.dumps(
value,
ensure_ascii=False,
sort_keys=True,
separators=(",", ":"),)
缓存不是语义匹配,它很小气。你觉得"意思一样"没用,token 序列一样才有用。
2.高并发:一万用户共享一份 KV
大多数讲 Prompt Cache 的文章都只有单用户视角:同一个应用的多次请求复用同一份系统提示词。但高并发场景下,还有一个更夸张的收益,很多人没意识到。
想象一万个用户同时在用你的产品。没有 Prompt Cache 的话,服务端要为每个并发请求单独算一遍系统提示词的 KV——一万次完全相同的计算同时发生,算力就这么烧掉了。有了在服务端自动识别公共前缀的机制(OpenAI、vLLM 都是这个思路),服务端只需要维护一份 KV 矩阵,一万个用户共用。
第一个请求的成本,大家一起摊。这才是企业级部署里 Prompt Cache 真正的杀手级场景,命中率的提升幅度比单用户视角大一个数量级。如果你在做 C 端产品,这一点可能是最值得优先关注的地方。
这里的工程重点不是"大家都用同一个 prompt"这么粗,而是把租户、实验、权限这些维度放对位置:
shared_prefix = [
stable_system,
stable_policy,
stable_tool_schema,]
tenant_suffix = f"""
当前租户:{tenant.name}
可访问知识库版本:{tenant.kb_version}
权限范围:{tenant.permission_scope}
"""
如果把租户信息放在最前面,每个租户都会形成一份独立前缀,跨用户共享就被切碎了。更合理的顺序是:全站公共规则在前,租户差异在后,用户输入最后。这样至少同租户内部可以共享,公共规则还可以在更大范围里复用。
对延迟敏感的业务,还可以做预热:发布新版本后,用典型请求提前打一次稳定前缀,让第一批真实用户不要承担冷启动成本。
def warmup_prompt_cache():
client.messages.create(
model=MODEL,
max_tokens=16,
system=build_stable_system_blocks(),
messages=[{"role": "user", "content": "请回复 OK,用于缓存预热。"}],)
预热请求的输出不重要,重要的是把稳定前缀的 KV 先建起来。
3.Tool Use:schema 和结果要切开
Agent 应用里有个特别容易忽视的地方:工具调用里,哪些部分该缓存,哪些不该?
答案很直接:Tool schema 定义(工具名称、参数描述、返回格式)是静态的,每次请求完全相同,适合缓存;Tool 的实际调用结果是动态的,每次不同,不该缓存。
system=[{"type": "text", "text": "系统提示词..."},{"type": "text","text": """
<tools>
<tool name="search_docs">...</tool>
<tool name="run_code">...</tool>
<!-- 几十个工具定义 -->
</tools>
""","cache_control": {"type": "ephemeral"} # schema 在断点前,结果在断点后}],
messages=[# tool 调用结果放在 messages 里,不参与缓存{"role": "user", "content": user_input},{"role": "assistant", "content": [{"type": "tool_use", "...": "..."}]},{"role": "user", "content": [{"type": "tool_result", "...": "..."}]},]
Agent 应用工具往往很多,这些 schema 定义加起来可能占系统提示词相当大的比例,分对了,命中率的差距会很明显。几十个工具的参数说明、枚举值、返回格式加起来可能有几千 token,如果每轮都重新 prefill,一边烧钱,一边增加首字延迟。
反过来,如果把 tool result 塞进系统提示词或者固定文档块里,缓存命中率会立刻变差。因为搜索结果、数据库返回、代码执行输出天然每次不同,它们应该作为消息历史的一部分追加在后面。
4.缓存安全分叉:上下文压缩的正确姿势
用户和 Agent 聊了很长一段,希望 Agent 能自动压缩上下文。一个容易想到的做法是,发起一个全新的请求让大模型做总结:
# 错误做法:新起一个请求做总结
response = client.messages.create(
system="你是一个助手,请结合以下上下文信息来提取摘要并返回", # 提示词从头变了
messages=[{"role": "user", "content": f"[对话上下文]\n{history}"}])
这份新提示词从第一个字就变了,完全享受不到任何缓存红利,全按新生成价格算。更麻烦的是,你把原本已经稳定的系统提示词和历史上下文重新包成了一个新字符串,模型还要重新理解一遍任务边界。
正确做法是缓存安全分叉——执行辅助任务时,故意保持上下文前缀完全不动,只在最后追加一条新消息:
# 正确做法:保持前缀不动,追加压缩指令
response = client.messages.create(
system=original_system, # 完全不变,命中已有缓存
messages=[*original_history, # 完全不变,命中已有缓存{ # 只在最后加一条新消息"role": "user","content": "请基于以上所有对话内容,生成一份简洁的压缩摘要,保留关键决策和上下文。"}])
前缀完全一致,已有的 KV Cache 全部复用,只有最后那条新消息需要重新计算。压缩任务完成后,用摘要替换掉原来的历史对话,缓存又能继续正常工作。
compressed_history = [{"role": "user","content": f"""
以下是此前对话的压缩摘要,后续回答必须视为上下文事实:
{summary}
""",}]
这里有两个注意点。第一,摘要本身会成为新的稳定前缀的一部分,所以摘要格式也要稳定。不要今天输出 Markdown,明天输出 JSON,后天又换成自然语言。格式一变,后面的缓存又要重建。
第二,别轻易为了压缩切换模型。提示词缓存是模型专有的,主链路从高价模型切到低价模型,原来的 KV Cache 通常不能复用。多轮对话里如果只是想做摘要,可以把压缩任务委派给 subAgent 或后台任务,但主链路的系统提示词和消息前缀尽量保持稳定。
5.先算账,再看命中率
缓存写入本身不是免费的。以 Anthropic 为例,写入价格是普通输入的 1.25 倍,还有持续的存储费用。如果缓存的内容没被重复用几次,不省钱,反而更亏。
什么时候才合算?有个临界点可以算一下:
重用次数 × (1 - 缓存命中价格比) > 写入额外开销
以 Anthropic 为例(写入 1.25x,命中 0.1x):
重用次数 × 0.9 > 0.25
重用次数 > 0.28
也就是说,在 Anthropic 的定价下,同一段内容只要被用超过一次,缓存就基本合算了,门槛相当低。
但这个公式有个前提:缓存真的会被命中。如果 TTL 很短、内容更新频繁,实际的重用次数可能远低于你的预期。
所以生产环境里至少要记录三组指标:
cache_creation_input_tokens 本次写入缓存的 token 数
cache_read_input_tokens 本次命中缓存的 token 数
input_tokens 本次仍按普通输入计费的 token 数
然后按接口、租户、模型版本、prompt 版本分别聚合。只看总体命中率很容易误判:一个热门接口命中很好,可能掩盖掉十个低频接口一直在亏钱。
实操建议是:先让系统以自然方式运行一段时间,观察哪些稳定块真的会被复用,再决定要不要显式标记缓存。不要一上来就把所有内容都打上缓存标记,尤其是长尾知识库文档、用户级配置、实验性 prompt,这些东西看起来稳定,实际复用次数可能很低。
生产环境会踩的坑
缓存内容和文档状态不同步。 文档改了,缓存没更新,模型继续拿着过期内容回答用户。产品价格变了、政策更新了,这类场景下直接出错。版本号写进缓存 key,是最省事的解法。
多租户数据隔离问题。 多个租户的请求可能命中同一份缓存。如果系统提示词里含有租户特定的敏感信息,设计稍有不慎就可能出现跨用户数据泄露。包含用户特定数据的内容不要缓存,或者缓存 key 里必须带用户强标识。
模型升级导致全量失效。 版本切换后,已有的 KV Cache 全部作废——不同版本内部维度表示不同,没法复用。大规模部署下,升级当天的成本和延迟会同时飙升,需要提前做好预热方案,别等到出问题才想起来。
冷启动抖动。 服务重启、缓存过期、新版本上线——第一批请求全部无法命中缓存,延迟和成本同时拉高。对延迟敏感的应用,真实流量进来之前一定要主动预热,不能等着用户替你把缓存建起来。
显存是有上限的。 除了 DeepSeek 这类做了 NVMe offload 的,传统 KV Cache 直接吃显存。大规模多租户场景下,必须设计好缓存分层和淘汰策略(LRU/LFU),别以为缓存是无限的。
主流厂商怎么选
定价和功能细节更新频繁,决策前建议查阅各家最新文档。
讲完实现细节,再看厂商选择就不突兀了:你选的不是"哪家便宜",而是选一套缓存控制模型。核心差异有三个:缓存由谁创建、命中是否可控、缓存生命周期怎么管理。
海外三家:
| 厂商 | 控制方式 | 成本折扣 | 特点 |
|---|---|---|---|
| Anthropic | 显式 cache_control | 约 90% | 完全控制;写入 1.25x;最多 4 个断点 |
| OpenAI | 自动,无需标记 | 最高约 90% | 接入最简单;超过阈值后自动记录 cached_tokens |
| Google Gemini | 隐式 + 显式 cachedContents API | 约 90% | 支持多模态缓存和 TTL 管理 |
Anthropic 适合那些愿意精细管理 prompt 结构的团队。你知道哪些块稳定,知道断点应该打在哪里,也愿意为第一次写入多付一点钱,换来后续更确定的命中。复杂 Agent、长系统提示词、代码助手、带大量工具定义的平台,通常更吃这一套。
OpenAI 的优势是省心。它把缓存做成基础设施能力,超过阈值后自动处理,并在 usage 里返回 cached_tokens,应用侧不用显式标记。代价是控制感弱一些:你能通过 prompt 排序提高命中概率,但不能像 Anthropic 那样明确指定每个断点。对大多数产品团队来说,这种模式反而更友好,尤其适合调用量大、请求形态相对统一的在线应用。
Gemini 同时有隐式和显式两种缓存。它的 cachedContents 更像资源管理:你显式创建一份可复用内容,设置 TTL,再在后续请求里引用它。它的优势在多模态和长上下文场景,比如把一份长 PDF、视频帧说明或大型资料包缓存起来,后续围绕同一份资料连续提问。
国内厂商也可以按同一套逻辑看:
DeepSeek 是"基础设施降本"路线。它把 KV Cache offload 到 NVMe 阵列,绕开显存容量限制,所以缓存命中价格可以压得很低。对开发者来说,最大的价值是不用为显式缓存设计付出太多心智成本,先把稳定内容放前面,就能吃到相当一部分红利。
阿里云百炼更偏"生产控制"路线,隐式和显式两种模式都支持。普通业务可以先用隐式缓存,等接口调用量和 prompt 结构稳定后,再把高频、长前缀的部分改成显式缓存。这个路径适合企业内部系统:先低成本接入,再逐步治理。
月之暗面把缓存做成了更明确的租赁商品,按创建费、存储分钟费和调用费组合计价。它对工程团队的要求更高:你需要真的知道 TTL 设多长、哪些缓存值得保留、哪些过期就该删。好处是账算得细,坏处是没算清楚就容易把缓存当成另一个成本黑洞。
百度、字节这类平台通常更强调自动化和平台集成,适合已经在对应云或模型生态里的团队。选择它们时,重点不是单看缓存折扣,而是看日志里能不能拿到足够清楚的缓存命中指标。拿不到指标,后面优化就只能靠猜。
怎么选: 普通业务、成本敏感、不想折腾:优先选自动隐式,先把 prompt 顺序写对。系统提示词很长、有大量 Agent 工具定义、需要确定性命中:选显式或双轨制,把控制权握在自己手里。长文档、多模态资料包、多轮围绕同一材料提问:优先看资源型缓存能力。真正到了大规模 C 端,别只看单次调用价格,要看高并发公共前缀能不能稳定共享。
未来会发生什么
Prompt Cache 现在看起来像一个计费优惠,往后看,它更像大模型基础设施的一部分。
第一,缓存会从"单次请求优化"变成"会话级内存管理"。今天开发者还要自己想办法压缩上下文、控制断点、决定哪些历史要保留。未来更可能出现模型侧或网关侧的会话管理器:它知道哪些 token 是长期规则,哪些是短期状态,哪些只是工具噪声,然后自动把它们分层、压缩、淘汰。到那时候,写 prompt 的方式会更像写内存布局。
第二,缓存会和路由系统绑在一起。现在很多团队做模型路由,只看"这个请求该用贵模型还是便宜模型"。但缓存加入以后,路由决策会复杂得多:便宜模型如果没有缓存,未必真的便宜;贵模型如果已经有一大段热缓存,可能反而成本更低、延迟更稳。未来的模型网关会同时考虑价格、延迟、缓存热度、上下文长度和命中概率。
第三,缓存命中会变成 Agent 平台的核心指标。今天大家看 token 用量、平均延迟、成功率,往后还要看稳定前缀占比、缓存复用次数、冷启动成本、prompt 版本导致的失效率。一个 Agent 平台做得好不好,不只看模型回答聪不聪明,还要看它有没有把重复计算管理好。
所以 Prompt Cache 不只是"省点输入 token 钱"。它会逼着应用开发者重新理解 prompt:prompt 不是一段文本,而是一份会被反复执行、反复计费、反复复用的计算计划。
最后
Prompt Cache 的逻辑说到底只有一句话:相同的东西,算一遍就够了。
落地的关键只需要想清楚一件事:什么内容是稳定的,什么内容是变化的,把边界划清楚,稳定的放前面。 其他的——tool schema 和 tool 结果分开、ROI 算清楚再开缓存、监控命中率、冷启动预热——都是在这个基础上的补充细化。
高并发场景下那个容易被低估的收益值得再强调一次:跨用户的前缀共享,一万个用户共享一份 KV 矩阵,效果比单用户视角大一个数量级。很多团队把 Prompt Cache 当成单机优化来看,其实它在 C 端规模下才真正发挥出量级上的威力。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐


 2
2 0
0- 0



 已为社区贡献601条内容
已为社区贡献601条内容

所有评论(0)