别一上来就RAG:企业及AI到底应该走哪条数据工程路线?
企业AI落地困境:从Demo到上线的关键挑战 文章揭示了企业AI应用从概念验证到实际部署过程中普遍存在的"Demo能答,上线就炸"现象。通过分析脚本式RAG方案的局限性,作者指出企业AI的核心挑战不在于模型智能度,而在于数据治理、权限控制、工具调用等工程化环节的缺失。文章提出了八层目标架构(从数据源到治理发布),强调企业AI需要建立完整的工程链而非单纯优化模型效果。特别指出智能
这一讲不比谁的提示词更会写,也不讲哪种检索更高级。他只做一件事,把你从功能演示拉到路线能上线
企业AI的主问题从来不是模型够不够聪明,而是你有没有走对从数据,边界,工具到治理的那条路线
Demo能答,上线就炸
我们会从四个事故来看一下这个问题
-
规则更新了,答案还在讲旧版本:知识库文档已经更新,但所以没有重建系统继续把旧政策说得很自信
-
同名术语跨部门口径不一致:冻结挂起限制,在客服风控运营里的定义不一样,系统却把它当成一个意思回答
-
低权限用户看到了高敏SOP:你以为自己在做问答,实际上已经碰到了权限分层、PII 和动作边界
-
坏例出现后根本没法复现:回答错了,但你说不清是解析、切片、召回、重排还是 Prompt 变了
如果你从一开始就把企业 AI 理解成“Prompt + 向量库 + LLM”,你迟早会在真实数据、权限、工具调用和治理环节撞墙。
为什么大家总会先写脚本式RAG?
先承认一件事:大多数团队第一反应写脚本式 RAG,并不荒唐。 因为从“想法”到“可演示结果”,它确实是最短路径。
为什么它会成为团队直觉
-
依赖少,几天就能做出演示
-
业务方很容易看到“它会答”
-
团队会误以为“离上线已经不远”
-
真正昂贵的治理工作被延迟支付
脚本式 RAG 的问题不是“不能做”,而是很多团队把它误当成了正式路线。
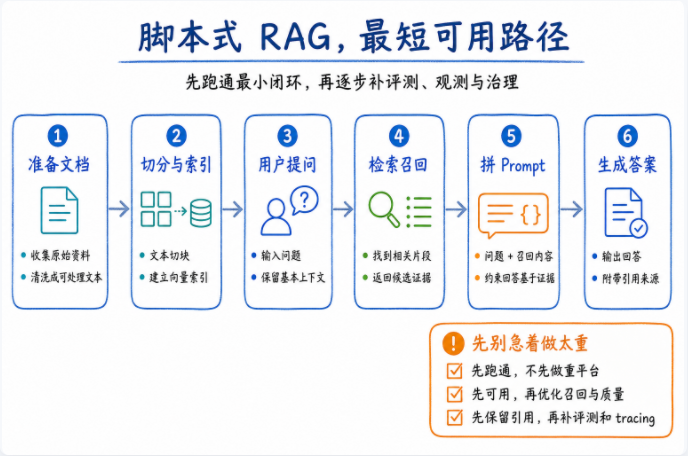
你不是在选技术栈,而是在选后果
下面这三条路线没有谁天然更高级。 真正重要的是:什么阶段能停,什么信号一出现就必须升级路线。
脚本式 RAG
PoC / 内部演示
最快做出能演示的链路。适合 PoC(可运行实例),不适合把复杂度继续拖到上线后。
-
你今天能快,是因为数据契约、权限边界、回放能力和发布治理还没真正进场。
-
它最适合回答“这件事值不值得做”,不适合回答“这套系统能不能上线”。
-
一旦进入真实用户、真实权限、真实动作链,复杂度会集中爆发。
该停在这里 :PoC、概念验证、演示链路。
必须切路线的信号: 出现真实用户、坏例回放、跨部门口径、权限分层、工具动作。
服务化 RAG
试点 / 小范围开放
比脚本更稳定,有 API、有缓存、有日志,但还远没到平台化治理。
-
API、缓存、日志让系统比脚本更像服务,但这不等于你已经有了统一数据底座。
-
你可以支撑试点,却未必能支撑多团队协作、持续回归和版本治理。
-
它解决的是应用层稳定性,不自动解决数据资产、证据边界和治理闭环。
该停在这里: 小范围试点、受控用户群、有限动作范围。
必须切路线的信号 :开始需要统一契约、统一评测、统一回滚和统一发布口径。
企业级 AI 数据工程平台
正式上线 / 多团队协作
目标不是“一上来做大平台”,而是清楚知道最终必须补齐哪些层。
-
真正上线后的贵,不是首版功能,而是跨团队维护、事故定位、回滚与责任边界。
-
平台化路线把这些能力前置成一条工程链,而不是继续让每次事故都临时补洞。
-
它不是让你 Day 1 做完全部,而是让你 Day 1 就知道最终要补齐到哪里。
核心价值: 可追溯、可观测、可治理、可持续迭代。
最容易误解的点 :不是“大而全”,而是“方向一开始就别走偏”。
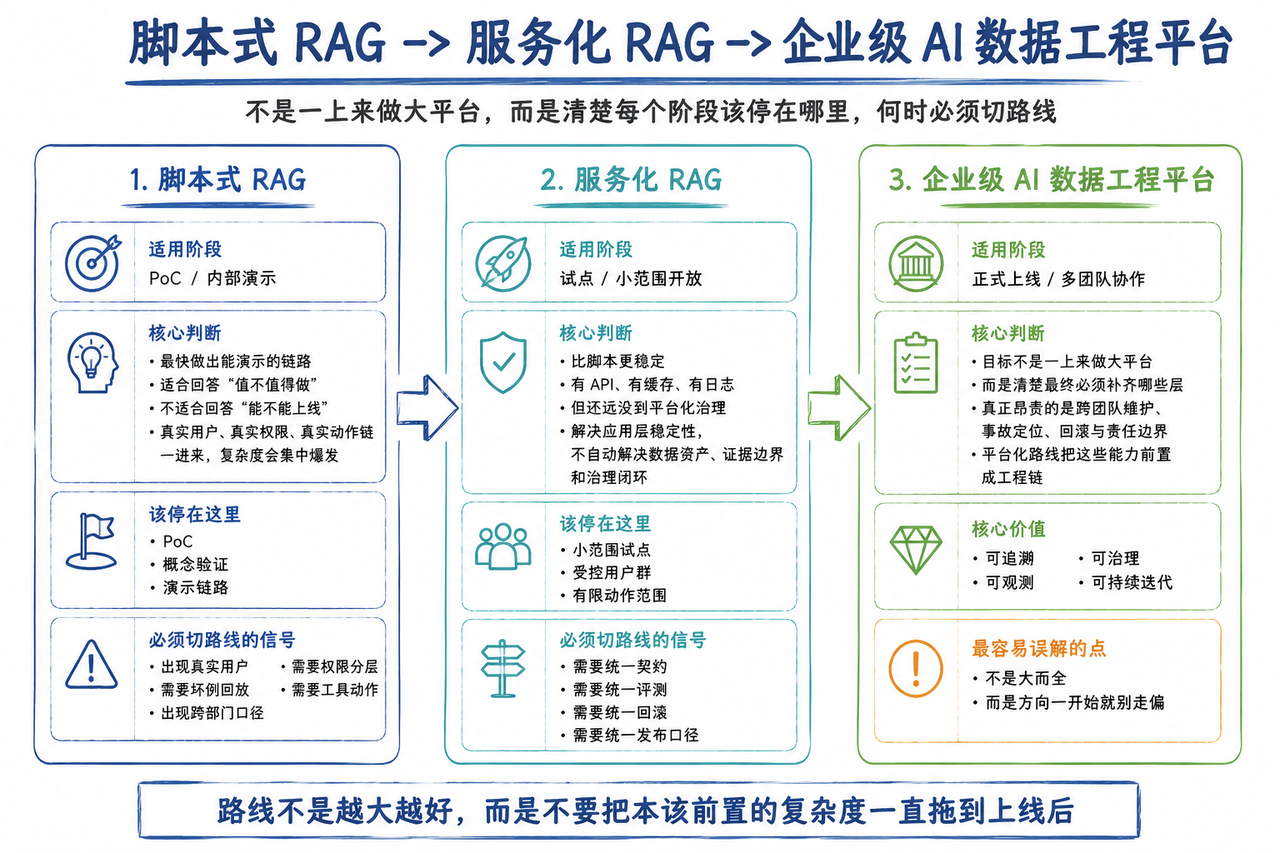
为什么脚本式RAG那么快,但是后面就开跪
脚本式RAG的最大风险,不是效果差,而是它会让团队误认为"剩下只是再调一调模型"
快在什么地方:
-
路径短,依赖少,反馈快
-
先用最少的数据工程把“会答”做出来
-
现场 Demo 看上去通常会很顺
-
对团队来说,启动成本极低
脆在什么地方
-
复杂度被延迟支付,问题集中在上线前爆发
-
版本、权限、坏例回放、发布边界都不清楚
-
一旦数据换批、规则更新、工具链变化,就很难复盘
-
你以为自己缺模型技巧,实际上缺的是工程链
服务化RAG已经更近一步,但是为什么还不够
服务化 RAG 解决的是调用稳定性,不自动解决数据契约、证据边界、动作分级和治理闭环。
已经解决的是
-
把脚本收成服务
-
有接口、有缓存、有基本日志
-
更容易支持一小批真实用户
它还没自动解决的事
-
数据是否有统一底座和版本语义
-
索引是不是资产,而不是一堆临时产物
-
评测、回滚、发布是否可绑定
最常见误判
“我们已经 API 化了,所以已经工程化了。”
真实情况是:你只是把应用层做厚了,底层资产和治理未必跟上。
真正的目标对象:不是一个 RAG 系统,而是一条企业 AI 数据工程链
数据 把输入做成可追溯资产,而不是临时喂给模型的原料。
检索与生成 让回答不仅像样,还要带证据、能回归、可校验。
工具与行为 让系统从“会答”进入“能办”,但动作权限必须前置设计。
治理与发布 把评测、Tracing、版本、回滚和责任边界收成上线能力。
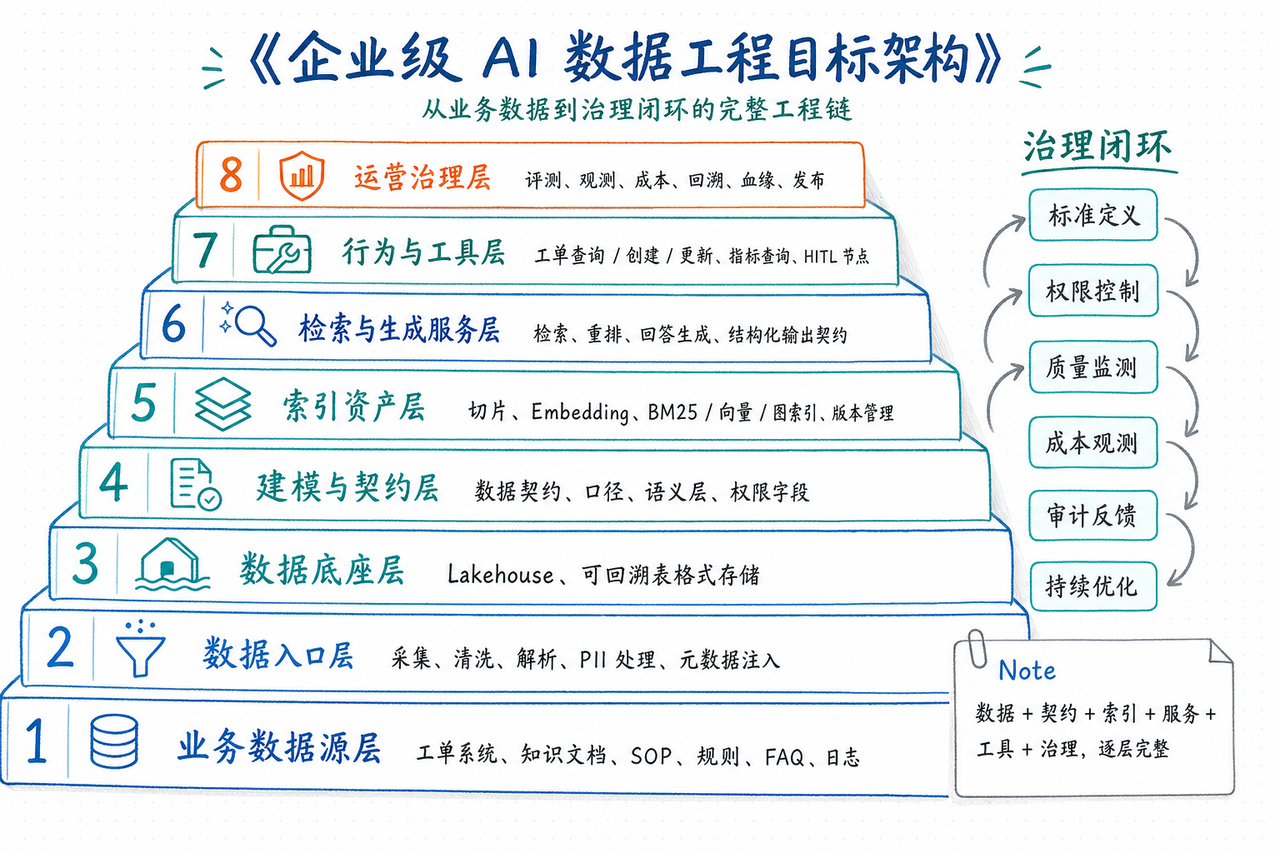
这张图不是装饰。以后遇到任何问题,都回到这里问三句。 我们卡在哪一层?我们缺的是能力还是顺序?我们是在补模型技巧,还是在补上线链路?
八层目标架构

-
数据源层
-
缺了会怎样: 你根本说不清系统到底建立在什么数据之上,后面也谈不上 owner、版本和责任。
-
最小抓手: 数据源清单、owner、刷新频率、使用边界。
-
在 CustomerAI 里: FAQ、SOP、工单系统、规则文档先要登记成可管理资产。
-
数据入口层
-
缺了会怎样: 文档解析错了、PII 没处理、元数据没注入,后面所有链路都会带着脏输入运行。
-
最小抓手:
source_fingerprint、pii_redaction_flag、parse_quality_score。 -
在 CustomerAI 里: 同一份业务规则从 PDF、邮件和后台导出进入系统时,要能留下一致的进入记录。
-
数据底座层
-
缺了会怎样: 出事故后你没有地方做 time travel、回放和回滚,只能靠猜。
-
最小抓手:
snapshot_id、ingest_batch_id、可回溯存储。 -
在 CustomerAI 里: 新旧业务规则、FAQ 和案例库要能按快照回看,而不是互相覆盖。
-
契约语义层
-
缺了会怎样: 同名术语在不同部门口径不一致,权限字段也没人真正定义。
-
最小抓手: 契约版本、标准术语表、访问等级字段。
-
在 CustomerAI 里: “冻结”“限制”“挂起”必须先统一语义,再谈检索和回答。
-
索引资产层
-
缺了会怎样: 你只有一个“向量库”,却不知道切片策略、Embedding 版本和索引发布时间。
-
最小抓手:
chunk_policy_id、embedding_version、index_release_id。 -
在 CustomerAI 里: FAQ、SOP、工单经验不能全塞进一个黑盒索引里,要按资产分类管理。
-
检索生成层
-
缺了会怎样: 结果看起来会答,但证据不稳、结构不可验、坏例难复现。
-
最小抓手: 检索 trace、重排理由、输出 schema 校验。
-
在 CustomerAI 里: 回答不仅要给结论,还要能说清引用了什么证据、为什么这么说。
-
行为工具层
-
缺了会怎样: 系统只能答,不能办;或者更糟,答完就越权去办。
-
最小抓手: 工具契约、动作分级、HITL 节点、幂等约束。
-
在 CustomerAI 里: “建议建单”和“自动建单”必须分层,不是一个开关。
-
治理发布层
-
缺了会怎样: 评测、Tracing、版本、发布记录互相断开,事故一来没人说得清该回退哪里。
-
最小抓手:
release_id、eval_run_id、trace_id、回滚 Runbook。 -
在 CustomerAI 里: 每次上线都要能绑定到具体评测基线、索引版本和工具策略。
把 CustomerAI 映射回这张总图
| 架构层 | 在 智能客服 里具体承担什么 | 如果这一层缺了,最先爆什么问题 |
| 数据源 + 入口 | 接 FAQ、SOP、业务规则、工单数据,并完成解析、清洗、PII 处理 | 规则更新不一致,解析错误直接进索引 |
| 底座 + 契约 | 保留快照、统一术语、定义权限字段和业务口径 | 同名术语冲突、旧版本无法回看、责任边界不清 |
| 索引 + 检索生成 | 管理 FAQ / SOP / 工单经验索引,输出带证据的结构化回答 | 召回不可解释、证据不稳定、坏例难复现 |
| 工具行为 | 查询工单、建议建单、升级人工、审批节点 | 一旦动作边界不清,就会从“会答”滑向“越权执行” |
| 治理发布 | 评测、Tracing、变更记录、回滚和 Runbook | 事故无法定位,试点永远不敢真正上线 |
CustomerAI 的价值,不是把所有内容都绑进一个项目,而是让你每学一层,都能在同一个业务世界观里验证它到底为什么必要。
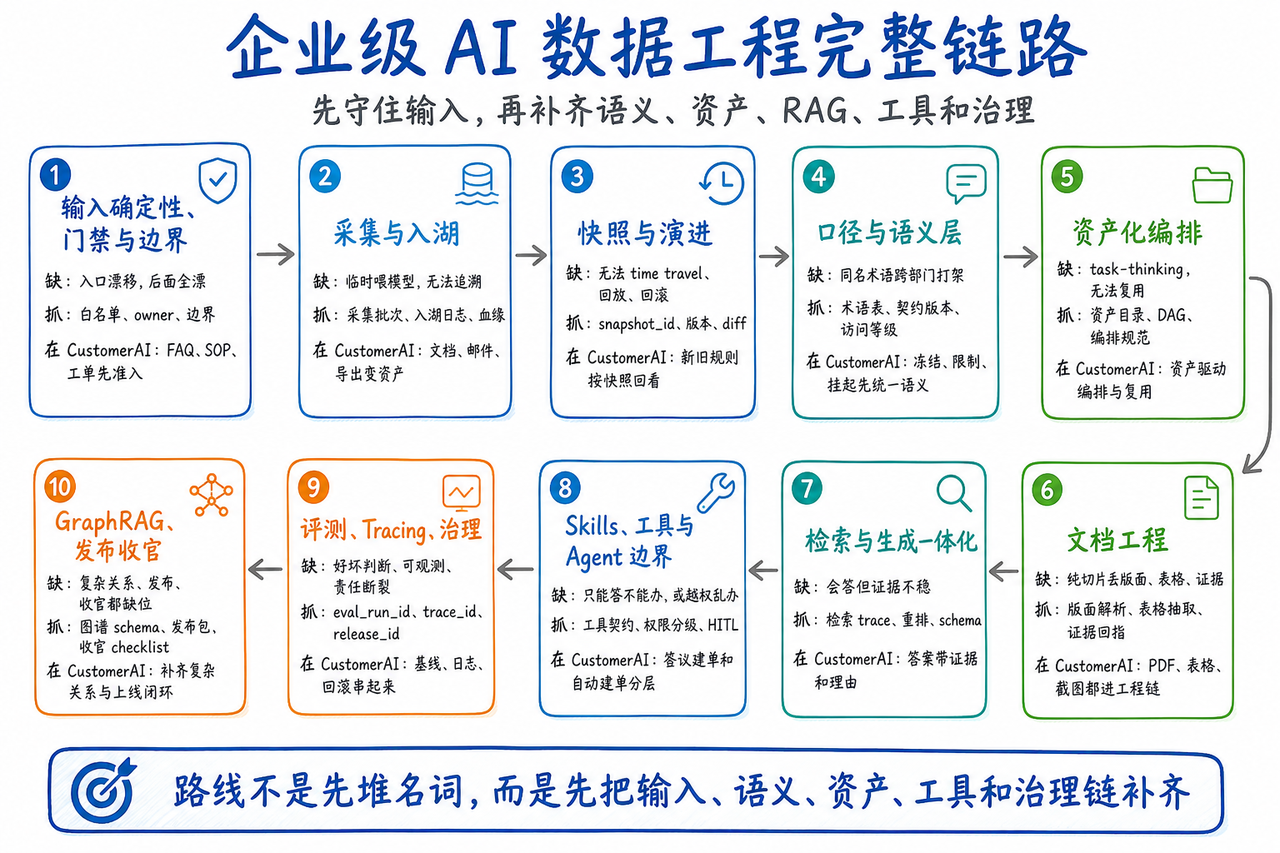
链路补充
-
输入确定性、门禁与边界:先守住输入端。因为如果入口就不稳,后面的索引、评测和治理全部建立在漂移数据上。
-
采集与入湖:把数据从“临时拿来喂模型”升级成“可追溯进入底座的资产”。
-
快照与演进:让时间维度进入系统,后面才谈得上 time travel、回放和回滚。
-
口径与语义层:统一术语、字段和契约,不然后面检索再强也会答在错误口径上。
-
资产化编排:从 task-thinking 走向 asset-thinking,让数据工程路线能稳定地被编排和复用。
-
文档工程:企业文档不是“纯文本切片”就够,版面、表格、证据回指都会影响后续检索质量。
-
检索与生成一体化:这时才真正进入 RAG 核心层,但它已经建立在前面几层的输入和资产稳定性之上。
-
Skills、工具与 Agent 行为边界:从“会答”走到“能办”,但前提是工具契约、权限分级和监督节点全部进场。
-
评测、Tracing、治理:把好坏判断、可观测性和发布责任正式收束成上线能力,而不是留给事后补救。
-
GraphRAG、发布与上线收官:在已有总图上把复杂关系、发布和收官能力补齐。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)