登录社区云,与社区用户共同成长
邀请您加入社区
报告目的: 本报告基于78+权威来源的220+数据点,系统呈现2026年AI Agent市场全景。涵盖市场规模、企业采用率、行业分布、投资趋势、ROI指标、应用场景、技术生态、挑战障碍、成本分析和人才格局十大维度,为企业决策者提供战略参考。
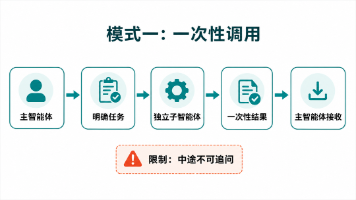
命令行Agent,高度自主,适合复杂任务。
这篇面向具备 Python 基础、想上手 AI 应用开发的开发者,但不会把“LangChain 实战指南:调用模型到构建 AI 应用,把工具链跑成稳定流程”写成概念清单。我会按保姆级实战教程的思路,把它放到真实开发、学习路线和求职准备里看,顺便讲几个容易忽略的取舍。这次我会从“从团队落地角度切入,重点写协作、日志和可维护性”展开,换一组场景和例子来讲。回到“LangChain 实战指南:调用模型到
这篇文章介绍了如何开发一个基于DeepSeek AI的Git提交信息生成工具。主要内容包括: 环境准备 创建Python虚拟环境并安装OpenAI依赖 建立项目目录结构 配置DeepSeek API密钥 核心模块实现 通过pyproject.toml配置项目元信息 定义专业化的System Prompt模板 封装Git操作工具类 实现DeepSeek API客户端(兼容OpenAI格式)
NMS 开发环境完整搭建指南(WSL + Docker 版)
文章摘要:本文针对AI模型在代码Bug修复中的实际应用展开测评,以100个真实开发场景的Bug任务为样本,重点评估ClaudeOpus4.7在"定位-修复-验证"全流程的表现。测试显示该模型在复杂任务中展现三大优势:工程化的排障路径推理、注重稳定性的最小化修复方案、以及符合团队规范的可复用表达。研究发现模型对空值边界、异步竞态等典型问题处理较好,但需配合日志、数据契约等上下文信
开发一个AI Agent的核心技术并不复杂,重点在于理解三个关键概念:提示词工程、上下文记忆和任务编排。通过分析开源项目AutoGLM可以发现,其核心逻辑是一个简单的循环结构,将复杂的操作流程转化为自然语言规则,交给大模型处理。提示词工程通过精心设计的规则引导模型行为;上下文记忆通过循环传递历史对话实现;任务编排则依靠模型自主判断和纠错。虽然高级Agent可能涉及更复杂的技术,但掌握这三个基础组件
我在一线科技企业深耕十二载,见证过太多因技术更迭而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。✅AI大模型学习路线图✅Agent行业报告✅100集大模型视频教程✅大模型书籍PDF✅DeepSeek教程✅AI产品经理入门资料完整的大模型学习和面试资料已经上传带到CSDN的
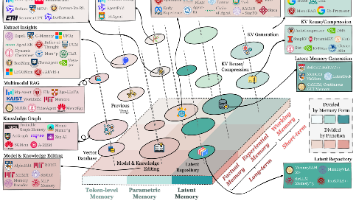
本文系统梳理了AI Agent记忆机制的研究进展,基于《Memory in the Age of AI Agents》论文提出的三维分类框架(记忆形式、功能与动态),分析了当前主流技术方案与挑战。记忆对Agent实现连续性、效率性和适应性至关重要,现有方案包括Token级(向量数据库)、参数级(LoRA)和潜在状态记忆三类,各具优缺点。论文还探讨了记忆功能分类(情节/语义/程序记忆)及动态演化机制
OpenClaw v2.7.9 本地AI自动化工具安装指南 OpenClaw是一款离线运行的AI智能体,支持Windows/macOS系统,可自主执行文件整理、检索、系统管理等任务。安装步骤: 关闭安全软件(如360、Defender等),避免误拦截。 下载对应系统压缩包(45.7MB),使用WinRAR/7-Zip解压(Win11需注意权限)。 运行一键启动程序,遇系统拦截时选择“仍要运行”。