一文搞懂数据清洗的6大关键步骤
数据清洗不仅是技术层面的操作,更是提升数据价值、保障业务决策科学性的关键。从缺失值处理到格式统一,每个环节都在为数据资产的价值转化奠定基础。通过解决数据缺失、冗余、不一致等问题,清洗后的数据能够更精准地支撑分析、降低成本并加速业务响应。然而,面对复杂的数据场景,手动清洗往往耗时费力,借助低代码ETL工具,可以大大简化清洗流程,实现自动化与规范化管理。但核心逻辑仍需回归业务本质——让每一份数据都能准
目录
你是否遇到过这样的尴尬
——分析数据时发现大量缺失、重复,甚至字段乱码?
辛辛苦苦跑出的结果,却因为“脏数据”出现漏洞?
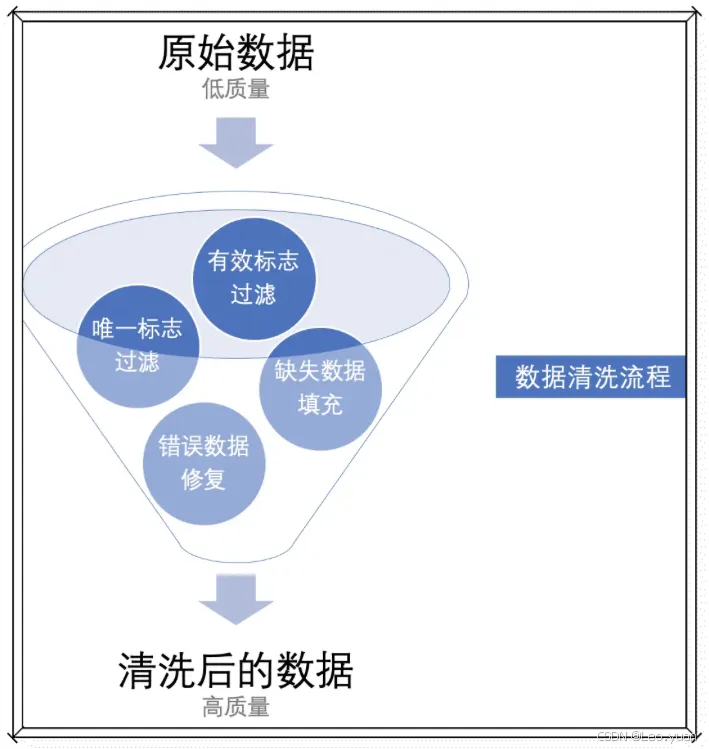
数据清洗,就是解决这些问题的关键!它可以帮你剔除重复、补全缺失、纠正错误,把原始数据变成干净可用的“好数据”。但具体该怎么做呢?这篇文章就用最直白的方式,拆解数据清洗的6大核心难题:从缺失值处理到字段格式统一,从重复数据判定到无用信息取舍,一步步带你扫清障碍,让数据真正为业务赋能。
一、什么是数据清洗
数据清洗通过将重复、多余的数据筛选清除,将缺失的数据补充完整,将错误的数据纠正或去除,从而提升数据质量,提供给上层应用调用。它可以有效处理数据的常见问题:数据缺少值、数据值不匹配、数据重复、数据不合理、数据字段格式不统一、数据无用。
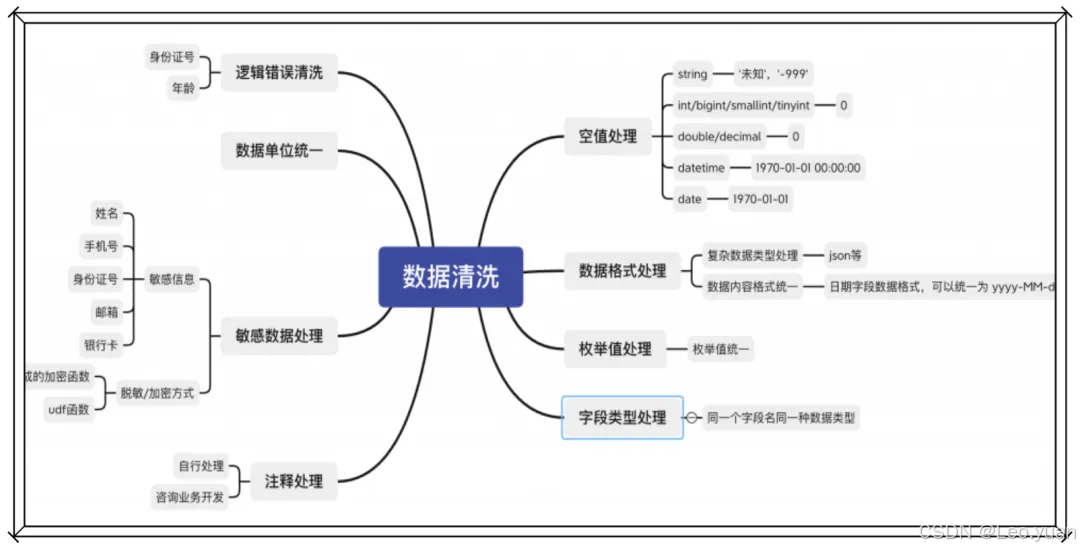
二、数据清洗的步骤
如何做好数据清洗,从而提高数据价值和利用效率?前面我们已经谈到了数据处理的六大问题:数据缺失值、数据值不匹配、数据重复、数据不合理、数据字段格式不统一、数据无用。
我们从第一个问题开始讲起:
1. 数据缺失值
(1)对每个字段计算其缺失值比例,然后按照缺失比例和字段重要性,进行分别制定战略
(2)不重要的,或者缺失率过高的数据直接去除字段
(3)重要的数据,或者缺失率尚可的数据,可以进行补全。以下是几个补全数据的方法:
①通过业务知识或者过往经验进行推测填充
②用同一指标数据计算结果(均值、中位数等)填充
③用不同指标数据计算结果填充(如年龄可用身份证信息推测)
④数据填充情况很复杂,数据填充的方式有很多,可以参考一些统计方法的工具数据。
(4)对某些缺失率高,数据缺失值多但又很重要的数据,需要和业务人员了解,是否可以通过其他渠道重新取数。
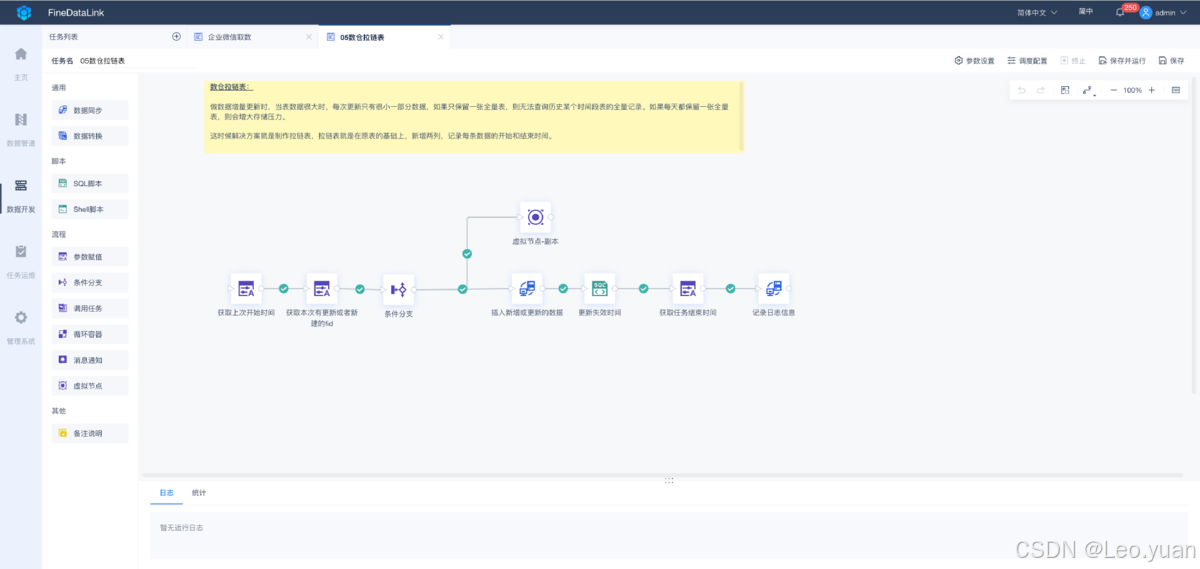
从这个过程中可以看到数据清洗的人力成本是比较高的,在真实场景中,数据情况往往会更错综复杂,如果不想经历上述复杂的数据清洗过程,可以使用ETL工具来帮助简化数据处理流程,我平时工作中用的比较省时省力的工具是FineDataLink(FDL)。FDL是一款专门做数据集成的低代码工具,可以接入并整合各种类型的数据,集中进行管理。通过简单拖拽交互即可实现数据抽取、数据清洗、数据到目标数据库的全过程。它的链接我就放在下面了,大家可以自己动手试用一下,点击文末“阅读原文”即可申请试用:FDL激活
2.数据值不匹配
(1)清洗内容中有不合逻辑的字符
最典型的就是头、尾、中间的空格,也可能出现姓名中存在数字符号、出现汉字等问题。这种情况下,需要以半自动校验半人工方式来找出可能存在的问题,并去除不需要的字符。
(2)内容和该字段应有内容不符
经常在处理埋点数据时会发现某个字段内容乱码等,通常过滤掉,但该问题特殊性在于:并不能简单的以删除来处理,因为成因有可能是数据解析错误,也有可能是在数据在记录到客户本地时就发生了错误(平台),因此要详细识别、分类处理问题。
这部分的内容往往需要人工处理,尽量细致地检查,不要遗漏。
3.数据重复
数据集中的重复值包括以下两种情况:
(1)数据值完全相同的多条数据记录,这是最常见的数据重复情况。
(2)数据主体相同,但一个属性匹配到不同的多个值。
去重的主要目的是保留能显示特征的唯一数据记录,但当遇到以下几种情况时,不建议去重。
①重复记录用于分析演变规律,例如因为系统迭代更新,某些属性被分配了不同值。
②重复的记录用于样本不均衡处理,通过简单复制来增加少数类样本。
③重复的记录用于检测业务规则问题,代表业务规则可能存在漏洞。
4.数据不合理
这类数据通常利用分箱、聚类、回归等方式发现离群值,然后进行人工处理。
5.数据字段格式不统一
整合多种来源数据时,往往存在数据字段格式不一致的情况,将其处理成一致的格式利于后期统一数据分析。
6.数据无用
由于主观因素影响,往往无法判断数据的价值,故若非必须,则不进行非需求数据清洗。
三、数据清洗的目标
通过上述详细的数据清洗步骤,我们逐步解决数据处理过程中存在的各类问题,得到符合标准、能充分发挥价值的数据。具体而言,得到的数据需要达到以下几个目标:
1.提高数据质量
数据质量是数据分析和决策的基础。通过数据清洗,可以解决数据缺失、重复、不合理以及格式不统一等问题,从而大大提升数据的准确性和可信度。
2.提升分析的准确性
根据清洗后准确的数据能够提高分析结果的可靠性,减少决策错误。
3.支持业务决策
清洗后的数据能更加直观地反映业务情况,更加容易进行数据可视化的分析。
4.减少存储成本
通过删除重复和无关的数据,有效减少存储空间的浪费。
5.数据时效性
及时清洗数据可以确保数据的时效性,能够基于最新的数据做出及时的业务调整。
借助数据集成工具FineDataLink,可以为定时任务设置执行频率,实现分钟级别的数据定时调度,还能定期自动运行定时任务,以保证数据能够及时更新。并且FineDataLink可以秒级别响应数据管道任务,支持对数据源进行单表、多表、整库、多对一数据的实时全量和增量同步,能够根据数据源适配情况,配置源端到目标端的实时同步任务。
四、总结
数据清洗不仅是技术层面的操作,更是提升数据价值、保障业务决策科学性的关键。从缺失值处理到格式统一,每个环节都在为数据资产的价值转化奠定基础。通过解决数据缺失、冗余、不一致等问题,清洗后的数据能够更精准地支撑分析、降低成本并加速业务响应。然而,面对复杂的数据场景,手动清洗往往耗时费力,借助低代码ETL工具,可以大大简化清洗流程,实现自动化与规范化管理。但核心逻辑仍需回归业务本质——让每一份数据都能准确释放价值。不妨立即行动,从清洗开始,让每一份数据都物尽其用。

全面兼容主流 AI 模型,支持本地及云端双模式
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)