【解决Linux下载cuda和cudnn后还是无法使用GPU加速的问题】
最好按照相应的tensflow下载对应的cuda和cudnn版本,不确认问ai,因为兼容性问题很麻烦,我继续下这两个版本是因为在之前的服务器上摸索cuda和cudnn下载的时候误打误撞下了,可以运行成功也没碰到这么多问题,所以重新布署的时候我就继续沿用之前的方法了。显示正确的版本即为安装成功,按理应该显示11.8,但是我的却显示了11.5也就是之前的版本,我也出现了跟博主一样的问题,即安装了新的c
解决Linux下载cuda和cudnn后还是无法使用GPU加速的问题
一、下载cuda
连上服务器后输入nvidia-smi,可以查看支持的cuda的最高的版本,如图所示,我的最高支持12.8。
由于我的Python版本是3.9,tensflow版本是2.5.0,我下载的cuda版本是11.8.89,cudnn版本是8.9.7。如果不清楚自己需要下载什么版本的可以把自己的环境和各种包依赖发给ai,尽量没冲突的情况下下载支持的版本,当然如果源代码有说明什么版本就更好啦。
cuda和cudnn的下载参考的是这篇博客https://blog.csdn.net/weixin_45819759/article/details/140034554?spm=1001.2014.3001.5502,按照教程选择local版的,其他版本的操作更麻烦点还容易出错。
cuda的下载链接:cuda下载
下载cuda时我还是采取之前的方法,没有wget,而是先下载到本地,再在终端进入安装目录下,执行下述命令:
sudo sh cuda_11.8.0_520.61.05_linux.run
根据博客中的提示信息安装,continue->手动输入accept->取消安装驱动(Driver及其下拉列表),install->Upgrade all,出现下述信息: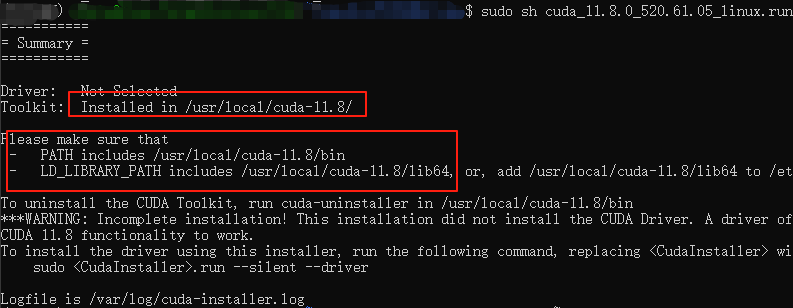
再根据上述make sure that的信息添加环境,我用的是它的法二:
sudo vim ~/.bashrc
点i进入编辑模式,在最后一行输入
export PATH=$PATH:/usr/local/cuda-11.8/bin
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64
保存好后退出,再更新一下bashrc文件:
source ~/.bashrc
使用nvcc -V查看cuda的版本
nvcc -V
显示正确的版本即为安装成功,按理应该显示11.8,但是我的却显示了11.5也就是之前的版本,我也出现了跟博主一样的问题,即安装了新的cuda后nvcc -V依然显示旧版本。
我也按照博主的方法多次检查环境路径,均显示无误,但是博主驱动那步看起来比较麻烦我不敢轻易尝试(配环境真的很怕一步错步步错呀呜呜呜),故寻找其他解决办法。
echo $PATH
echo $LD_LIBRARY_PATH


解决办法:
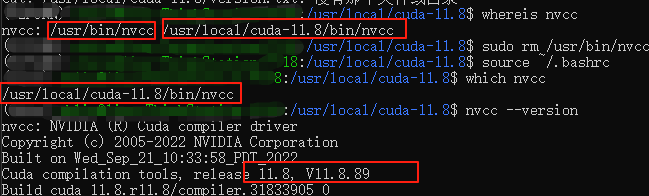
1、首先检查nvcc路径,输入whereis nvcc,
whereis nvcc
如下图所示,根据 whereis nvcc 的输出,系统中有两个 nvcc 可执行文件:
/usr/bin/nvcc
/usr/local/cuda-11.8/bin/nvcc
问题在于系统优先使用了 /usr/bin/nvcc(很可能是旧版本),而不是我安装的 CUDA 11.8 版本。
2、删除/usr/bin/nvcc 的旧版本链接
sudo rm /usr/bin/nvcc
更新配置文件:
source ~/.bashrc
再查看nvcc路径可以发现只有我们需要的11.8了
which nvcc
此时再输入nvcc --version即显示正确的版本了V11.8.89
nvcc --version
二、下载cudnn
cudnn的下载链接:cudnn下载
上述两个链接也可直接在网页搜,如下图第一个点进去就是了,再选择对应的版本

我下载的cudnn-linux-x86_64-8.9.7.29_cuda11-archive.tar.xz,跟下载cuda步骤差不多,我是先进入该文件所在路径再解压cudnn文件
tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda11-archive.tar.xz
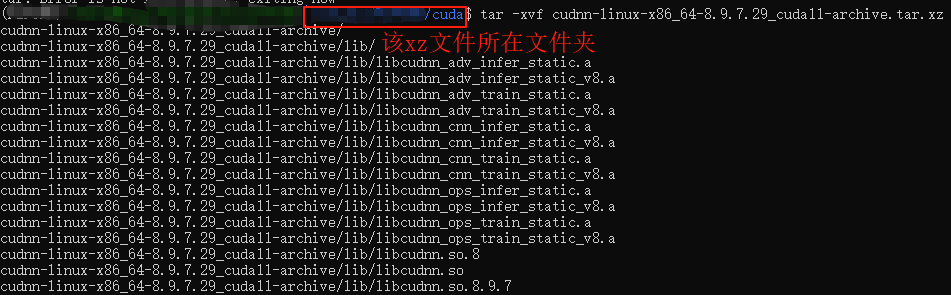
进入解压出的文件夹,拷贝文件到/usr/local/cuda-11.8中
cd cudnn-linux-x86_64-8.9.7.29_cuda11-archive
sudo cp lib/* /usr/local/cuda-11.8/lib64/
sudo cp include/* /usr/local/cuda-11.8/include/
sudo chmod a+r /usr/local/cuda-11.8/lib64/*
sudo chmod a+r /usr/local/cuda-11.8/include/*

最后查看cudnn版本,如下图所示cudnn版本号为8.9.7
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

上述已经安装好了cuda和cudnn。
三、解决Linux下载cuda和cudnn后还是无法使用GPU加速的问题
按理我应该可以直接运行代码了,但是运行代码时出现下述信息:
2025-06-02 13:07:40.455118: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
2025-06-02 13:07:42.082283: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcuda.so.1
2025-06-02 13:07:42.096380: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2025-06-02 13:07:42.096538: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce GTX 1080 computeCapability: 6.1
coreClock: 1.8225GHz coreCount: 20 deviceMemorySize: 7.92GiB deviceMemoryBandwidth: 298.32GiB/s
2025-06-02 13:07:42.096570: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
2025-06-02 13:07:42.113155: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublas.so.11
2025-06-02 13:07:42.113222: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublasLt.so.11
2025-06-02 13:07:42.141531: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcufft.so.10
2025-06-02 13:07:42.143949: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcurand.so.10
2025-06-02 13:07:42.147239: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusolver.so.11
2025-06-02 13:07:42.160772: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusparse.so.11
2025-06-02 13:07:42.160985: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudnn.so.8'; dlerror: libcudnn.so.8: 无法打开共享目标文件: 没有那个文件或目录
2025-06-02 13:07:42.160998: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1766] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices..
TensorFlow 需要 libcudnn.so.8但是我的系统缺少这个库文件,因此 TensorFlow 无法使用 GPU 加速功能:
Could not load dynamic library 'libcudnn.so.8'
dlerror: libcudnn.so.8: 无法打开共享目标文件: 没有那个文件或目录
本人试了以下办法,
创建符号链接:
sudo ln -sf libcudnn.so.8.9.7 libcudnn.so.8

检查cudnn版本也无误
find /usr -name "cudnn_version.h" 2>/dev/null
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

以上都没有解决,我运行了个diagnose_tf.py诊断文件:
import tensorflow as tf
print("TensorFlow版本:", tf.__version__)
# 检查CUDA版本
print("CUDA版本:", tf.sysconfig.get_build_info().get('cuda_version', '未找到'))
# 检查cuDNN版本
print("cuDNN版本:", tf.sysconfig.get_build_info().get('cudnn_version', '未找到'))
# 检查GPU是否可用
print("GPU可用:", tf.config.list_physical_devices('GPU'))
输入以下信息:
2025-06-02 15:41:35.962662: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
TensorFlow版本: 2.5.0
CUDA版本: 11.2
cuDNN版本: 8
2025-06-02 15:41:36.784615: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcuda.so.1
2025-06-02 15:41:36.790206: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2025-06-02 15:41:36.790362: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce GTX 1080 computeCapability: 6.1
coreClock: 1.8225GHz coreCount: 20 deviceMemorySize: 7.92GiB deviceMemoryBandwidth: 298.32GiB/s
2025-06-02 15:41:36.790394: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
2025-06-02 15:41:36.793983: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublas.so.11
2025-06-02 15:41:36.794038: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublasLt.so.11
2025-06-02 15:41:36.817589: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcufft.so.10
2025-06-02 15:41:36.817959: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcurand.so.10
2025-06-02 15:41:36.818566: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusolver.so.11
2025-06-02 15:41:36.820928: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusparse.so.11
2025-06-02 15:41:36.821081: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudnn.so.8'; dlerror: libcudnn.so.8: 无法打开共享目标文件: 没有那个文件或目录
2025-06-02 15:41:36.821093: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1766] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
GPU可用: []
还是不可用,最后的解决办法是关了VScode,重新连接服务器,再运行就可以了,所以我的建议是可以试试创建符号链接+重启应用(感觉主要是重新连接服务器)。困扰了我一天的问题就被重启VScode和重新连接服务器解决了,已经要被配环境逼疯了。
运行代码如下所示:
2025-06-02 21:12:30.974742: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudnn.so.8
...
2025-06-02 21:12:30.975634: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1871] Adding visible gpu devices: 0
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
上述信息说明TensorFlow成功加载了cuDNN库,并且检测到了GPU设备。
再运行diagnose_tf.py诊断文件查看此时的tensorFlow、cuda和cudnn版本如下所示:
2025-06-02 22:14:42.590410: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
TensorFlow版本: 2.5.0
CUDA版本: 11.2
cuDNN版本: 8
2025-06-02 22:14:44.227295: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcuda.so.1
2025-06-02 22:14:44.249270: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2025-06-02 22:14:44.249419: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce GTX 1080 computeCapability: 6.1
coreClock: 1.8225GHz coreCount: 20 deviceMemorySize: 7.92GiB deviceMemoryBandwidth: 298.32GiB/s
2025-06-02 22:14:44.249448: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
2025-06-02 22:14:44.343120: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublas.so.11
2025-06-02 22:14:44.343211: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublasLt.so.11
2025-06-02 22:14:44.353514: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcufft.so.10
2025-06-02 22:14:44.356081: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcurand.so.10
2025-06-02 22:14:44.360603: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusolver.so.11
2025-06-02 22:14:44.367324: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusparse.so.11
2025-06-02 22:14:44.368588: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudnn.so.8
2025-06-02 22:14:44.368788: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2025-06-02 22:14:44.369172: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2025-06-02 22:14:44.369699: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1871] Adding visible gpu devices: 0
GPU可用: [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
我系统上安装的是CUDA 11.8和cuDNN 8.9.7,但是TensorFlow报告的是它构建时所使用的CUDA版本(11.2)和cuDNN版本(8.1)(实际上它正成功运行在CUDA 11.8和cuDNN 8.9.7系统上),而不是系统实际安装的版本。而我之所以能运行,是通过CUDA/cuDNN的向后兼容能力实现的。即:
实际安装:CUDA 11.8 + cuDNN 8.9.7
TensorFlow 报告:CUDA 11.2 + cuDNN 8
工作原因:TensorFlow 与 CUDA 11.8 (兼容11.2) 和 cuDNN 8.9.7 (兼容8.1) 良好配合。
温馨提示:最好按照相应的tensflow下载对应的cuda和cudnn版本,不确认问ai,因为兼容性问题很麻烦,我继续下这两个版本是因为在之前的服务器上摸索cuda和cudnn下载的时候误打误撞下了,可以运行成功也没碰到这么多问题,所以重新布署的时候我就继续沿用之前的方法了。

全面兼容主流 AI 模型,支持本地及云端双模式
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)