【Spring AI】Advisors API—顾问(即拦截器)
Advisors API :: Spring AI 参考在官方的介绍中,Spring AI Advisors API 提供了一种灵活而强大的方式来拦截、修改和增强 Spring 应用程序中的 AI 驱动交互。通过利用 Advisors API,开发人员可以创建更复杂、可重用和可维护的 AI 组件。主要优势包括封装重复出现的生成式 AI 模式、转换与大型语言模型 (LLM) 发送和发送的数据,以及提
目录
大家好,我是jstart,今天给大家讲讲Spring AI中的一个核心特性——Advisors。这个特性是指在帮大家能完成模型调用的基础上,进行对AI功能的定制化增强,Advisors的功能非常强大,几乎所有增强都依靠它来完成。
如果大家还不能正常地在程序接入大模型并完成调用,那么大家可以看看这两篇博客:
【Spring AI Alibaba】接入大模型-CSDN博客
【java】AI内容用SSE流式输出响应给前端,实现打字机效果-CSDN博客
一、介绍
官方文档:Advisors API :: Spring AI 参考
在官方的介绍中,Spring AI Advisors API 提供了一种灵活而强大的方式来拦截、修改和增强 Spring 应用程序中的 AI 驱动交互。 通过利用 Advisors API,开发人员可以创建更复杂、可重用和可维护的 AI 组件。
主要优势包括封装重复出现的生成式 AI 模式、转换与大型语言模型 (LLM) 发送和发送的数据,以及提供跨各种模型和用例的可移植性。
总之,记住一句话就行了:advisor就是一个拦截器,在用户发送问题之后,在调用大模型之前,进行一系列增强。具体是什么增强,就与advisor的类型有关了,下面也会带大家实现advisor。
二、使用示例
advisor的难点在与如何开发advisor,置于advisor的使用是非常简单的,只需要把对应的advisor对象创建出来,然后作为参数进行传递即可。
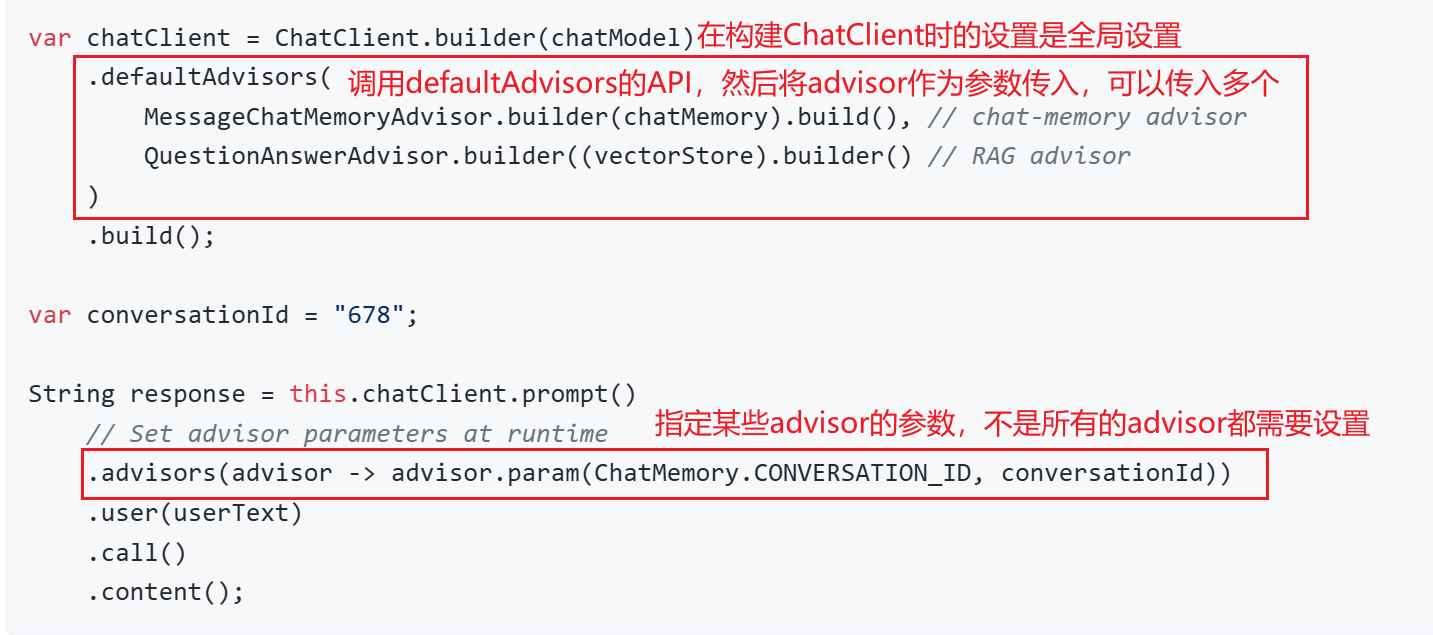
官方示例代码:
var chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build(), // chat-memory advisor
QuestionAnswerAdvisor.builder((vectorStore).builder() // RAG advisor
)
.build();
var conversationId = "678";
String response = this.chatClient.prompt()
// Set advisor parameters at runtime
.advisors(advisor -> advisor.param(ChatMemory.CONVERSATION_ID, conversationId))
.user(userText)
.call()
.content();代码解释:
三、Advisor开发前言
在实际开发中,我们往往需要用到多个拦截器,组合在一起相当于一条拦截链,每个拦截器都是有顺序的,通过实现Order接口,重写getOrder()方法来确定先后顺序,值越小,优先级越高。
advisor有两种模式:流式Streaming和非流式Non-Streaming,二者在用法上没有什么区别,只是返回值不同而已。为了保证通用性,在开发advisor时,两种模式都要实现,其实就是这两个模式的方法都要进行重写。
四、Advisor实践—多轮对话记忆
(1)基于内存存储的对话记忆数据
其实在springAI中,已经内置有了关于对话记忆的advisor,所以当我们需要开发其他advisor时,也可以参考其内置的advisor来开发。
言归正传,虽然说SpringAI已经内置了多轮对话记忆的advisor,也就是MessageChatMemoryAdvisor。但是,对话记忆是要将用户的对话数据存储起来,置于存储在哪里,如何进行存储,就是我们编码的重点了。

SpringAI也提供了一个基于内存来存储的示例,但是基于内存来存储对话记忆的话,只要服务器一重启,会话数据就会丢失,所以我们要自己实现一种可以持久化存储对话记忆的实现类。从上面的截图也可以看到,这里我选择的是使用mysql数据库来实现持久化记忆。这里先看一下基于内存来存储对话记忆的使用,非常简单,直接new出来即可。

查看InMemoryChatMemory的源码:
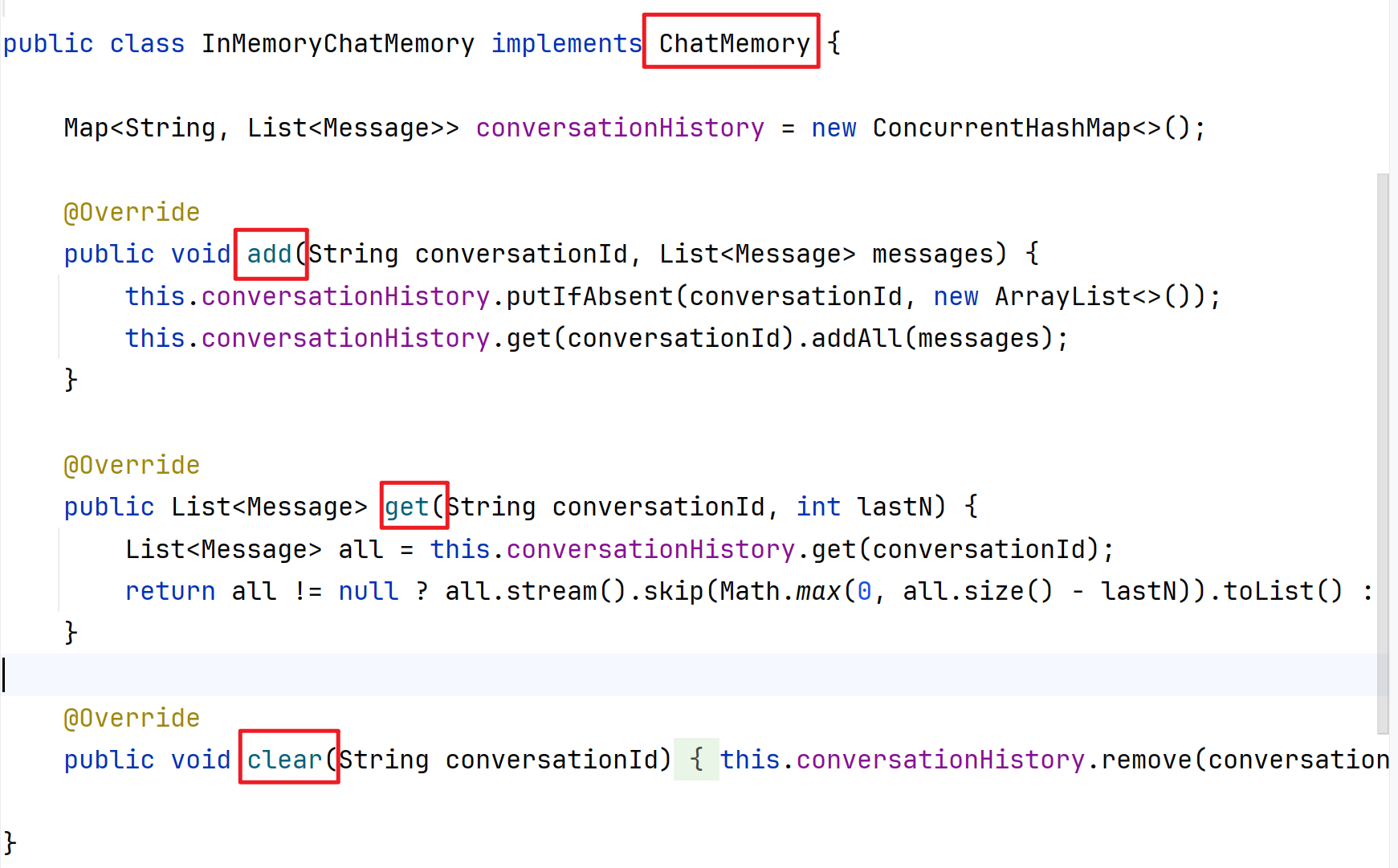
在ChatMemory接口中

在源码中发现,无非就是实现了一个固定的ChatMemory接口,然后重写里面的add、get、clear方法,也就是增删改方法了,非常简单,所以我们要实现使用mysql来持久化时,只需要同样的实现接口—重写方法—实现对数据库的增删改操作即可。
(2)基于mysql实现持久化记忆
难点在于——AI对话记忆中有多种类型,比如用户的消息实体,助手的消息实体(AI的回复)等等,难点在于如何将他们正确的按照对应的实体进行序列化和反序列化。
思路:
- 数据库实体设计:定义好消息类型(type)和消息内容(text)字段
- add方法中,从参数的Message对象中,取出type和text单独封装到数据库对应的实体,然后再保存到数据库
- 定义枚举,String类型记录type属性,Class类型指定对应type的字节码,便于返序列化
private final String value; private final Class<?> clazz; - get方法中:①获取到数据库的数据并封装到该表对应的实体,通过该实体的type属性和刚刚定义的枚举,获取到该条消息的字节码类型;②再通过序列化库(比如gson),将text的json格式数据反序列化成字节码对象;③最后强转成get方法返回值需要的类型。
private Message getMessage(ConversationMemory conversationMemory) { String memory = conversationMemory.getMemory(); Gson gson = new Gson(); return (Message) gson.fromJson(memory, MessageTypeEnum.fromValue(conversationMemory.getMessageType()).getClazz()); }

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)