GPT-5系列文章2——新功能、测试与性能基准全解析
OpenAI于2025年8月发布了GPT-5模型,该版本并非业界预期的AGI突破,而是对现有技术的深度整合与优化。主要创新包括智能路由机制、统一架构设计,以及个性化界面和安全改进等用户体验提升。基准测试显示,GPT-5在编码、数学和科学推理等任务上表现优异,但与Grok 4在多代理协作方面仍有差距。尽管长文本处理能力有所提升,但在处理复杂文档时仍存在局限。开发者可通过精细控制参数优化模型表现。总体
引言
2025年8月,OpenAI正式发布了其新一代旗舰模型GPT-5。与业界此前期待的AGI(人工通用智能)突破不同,GPT-5更像是OpenAI对现有技术的一次深度整合与用户体验优化。本文将全面解析GPT-5的新特性、实际测试表现以及官方发布的基准数据,帮助开发者与普通用户了解这一最新AI模型的真实能力与应用场景。
什么是GPT-5?
GPT-5是OpenAI推出的新一代旗舰模型,它完全取代了GPT-4时代的各种变体模型。与此前用户需要在GPT-4o、GPT-4o-mini、o3等不同版本间手动选择不同,GPT-5采用了智能路由机制,系统会根据任务类型自动决定使用快速响应还是深度推理模式。
模型的核心创新在于其统一架构设计:
- 自动路由:根据输入提示实时决定响应策略
- 统一体验:单一模型名称,一致的行为表现
- 可选模式:仍保留GPT-5 Thinking(深度思考)和GPT-5 Pro(专业研究)等特殊模式
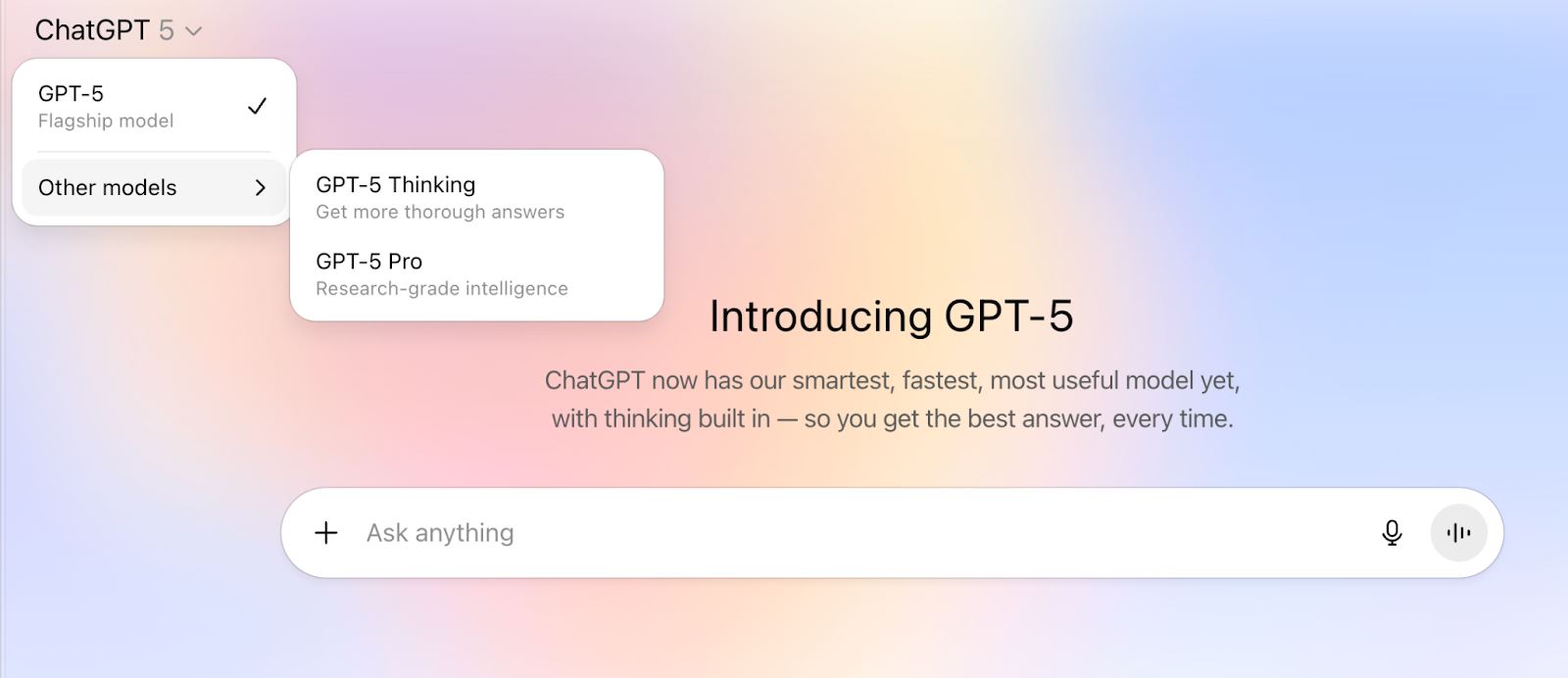
GPT-5的新功能
用户体验优化
-
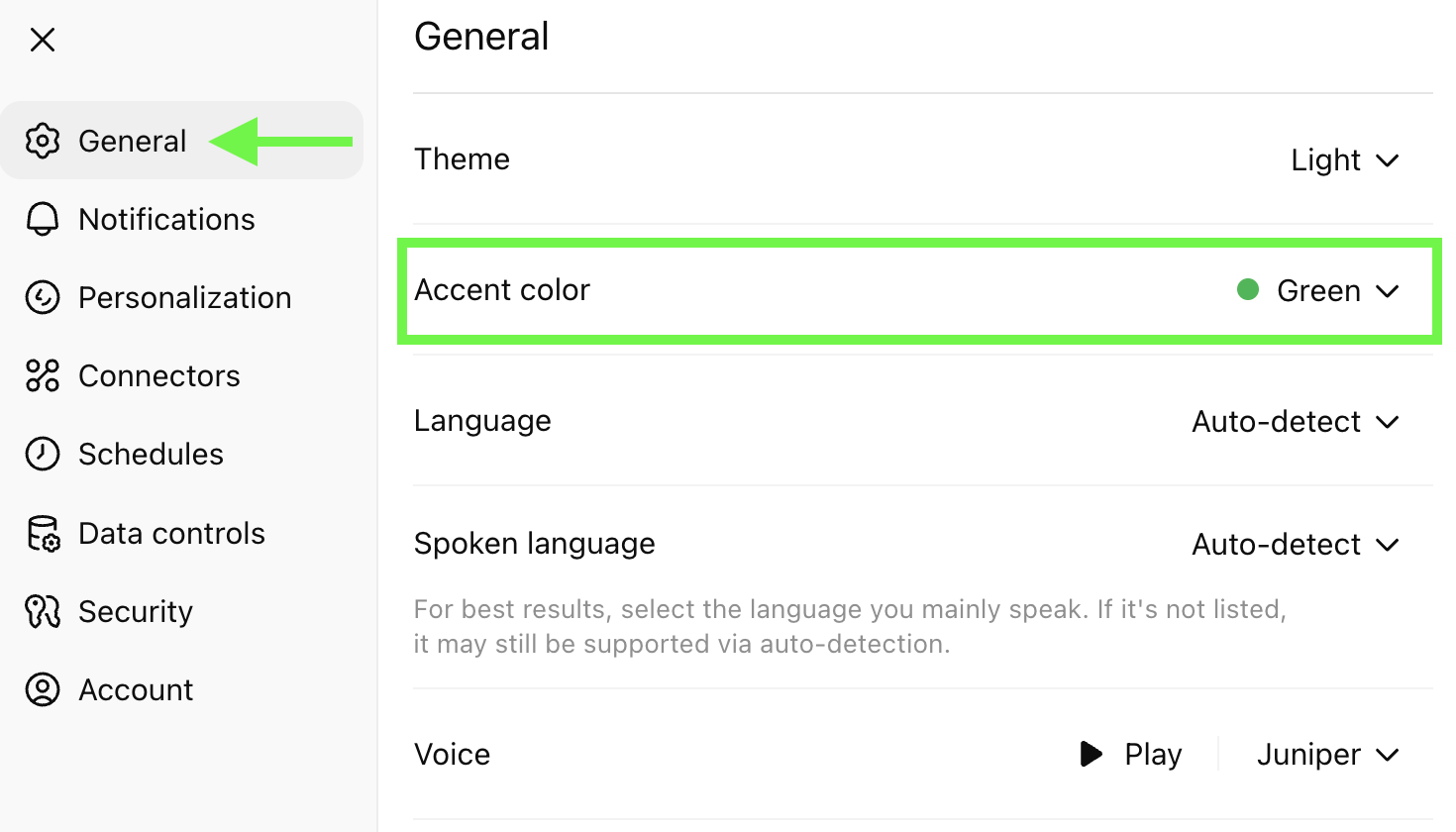
界面个性化:
- 自定义聊天界面颜色主题
-
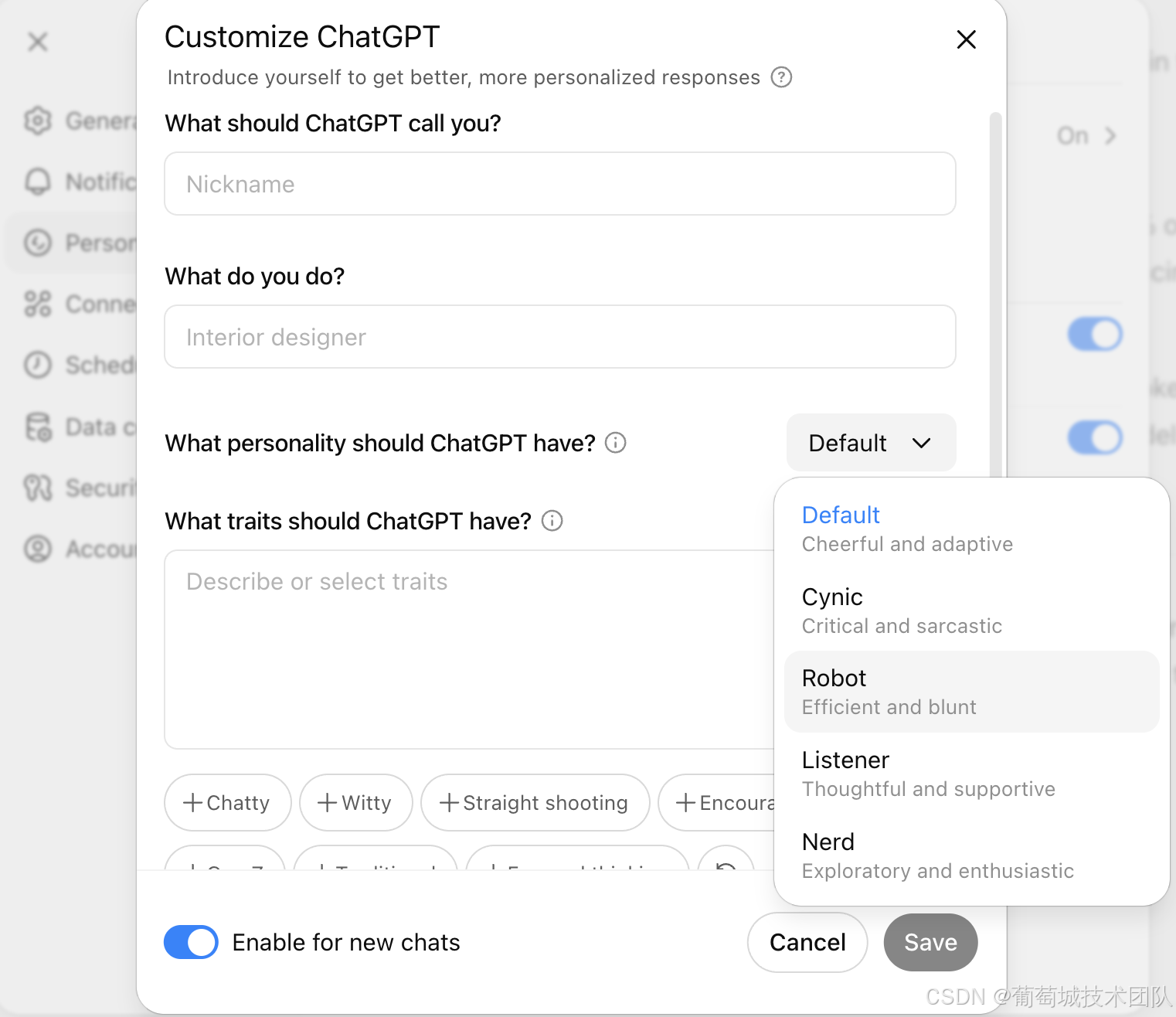
预设个性风格选择(支持型、简洁专业型、轻微讽刺型等)
-
个性风格在整个对话中保持稳定
-
生产力整合:
- Gmail和Google日历深度集成(仅限付费用户)
- 自动日程管理功能
- 邮件草拟与回复建议
-
安全改进:
- 采用"安全完成"机制替代简单拒绝
- 提供最大限度的有用信息同时说明限制
- 减少阿谀奉承式的回答
开发者专项功能
# 示例:使用reasoning_effort参数控制推理深度
response = openai.ChatCompletion.create(
model="gpt-5",
messages=[{"role": "user", "content": "解释量子纠缠现象"}],
reasoning_effort="high", # 可选:minimal/medium/high
verbosity="medium" # 控制回答长度
)
-
精细控制:
reasoning_effort参数控制推理深度verbosity参数调整回答长度
-
工具调用改进:
- 支持纯文本工具调用(替代JSON)
- 自定义工具格式约束(正则/完整语法)
-
长时任务支持:
- 显著提升多步骤代理任务能力
- 支持数十个工具调用的串联/并行
详细信息可以参考这篇文章:《ChatGpt 5系列文章1——编码与智能体》
测试GPT-5的实际表现
数学能力测试
基础算术:
- 9.11 - 9.9 = 0.21 (即时正确解答)
- 采用思维链推理(内部将9.9重写为10-0.1)
复杂问题:
使用0-9所有数字各一次组成x+y=z的三个数字
- 30秒思考后给出两个正确答案
- 内部使用"快速程序"解决排列问题
长上下文多模态测试
欧盟委员会AI报告分析(167页):
- Pro账户(128K tokens)仍出现明显问题
- 免费账户(8K tokens)完全无法处理
- 识别信息图表任务表现不佳
测试结果表明,尽管GPT-5在官方基准测试中长上下文表现有所提升,但在实际复杂文档处理中仍存在显著局限。
GPT-5基准测试数据
编码性能
| 测试项目 | GPT-5得分 | GPT-4.1得分 | 提升幅度 |
|---|---|---|---|
| SWE-bench Verified | 74.9% | 54.6% | +37% |
| Aider Polyglot | 88% | 81% | +8.6% |
效率提升:
- 高推理任务输出token减少22%
- 工具调用减少45%
数学与科学推理
-
竞赛数学:
- AIME 2025: 94.6%(无工具)
- HMMT: 93.3%(无工具)
-
前沿数学:
- FrontierMath: 26.3%(使用Python工具)
-
博士级科学:
- GPQA Diamond: 87.3%(有工具)
多模态推理
-
视觉推理:
- MMMU(大学级): 84.2%
- MMMU-Pro(研究生级): 78.4%
-
视频理解:
- VideoMMMU(256帧): 84.6%
-
专业领域:
- CharXiv Reasoning: 81.1%
- ERQA空间推理: 65.7%
极限测试:Humanity’s Last Exam
这个包含2,500个博士级问题的测试集结果显示:
- GPT-5无工具: 24.8%
- GPT-5 Pro: 42.0%
- Grok 4 Heavy: 50.7%
表明在多代理协作方面,xAI的Grok 4架构仍保持领先。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐
 28
28 0
0- 0



 已为社区贡献593条内容
已为社区贡献593条内容

所有评论(0)