Mem0 记忆架构解析:构建具有可扩展长期记忆的生产级AI Agent
Mem0:突破AI Agent记忆瓶颈的新范式 摘要:当前AI系统依赖大语言模型上下文窗口维持对话连贯性,但存在信息截断、成本高昂等固有缺陷。Mem0通过创新的两阶段记忆流水线(提取+更新)实现了持久化记忆存储,其图增强版本Mem0ᵍ更通过有向标签图建模复杂关系。测试显示,相比传统方法,Mem0在LOCOMO基准上准确率提升26%,延迟降低91%,token消耗减少90%。这套记忆系统支持跨会话个
当前大多数 AI Agent 依赖大语言模型(LLM)的上下文窗口来维持对话连贯性。然而,这种机制存在根本性缺陷:
- 上下文长度有限,历史信息会被截断;
- 成本高昂,每次推理需重传全部历史;
- 效果不佳,关键事实容易被忽略或覆盖;
— 1 为什么 AI Agent 需要真正的持久化记忆?—
定位根本原因
基于上述原因可以明确,AI 系统本身无法在不同会话或上下文溢出后自动持久化信息。这种“记忆缺失”会在人机交互中造成根本性的断层。

无记忆系统(左图):
- 用户首次对话中明确表示:“我是素食者,且避免乳制品。”
- 在后续会话中,当用户再次询问晚餐建议时,系统却推荐了“鸡肉阿尔弗雷多酱”,完全违背了用户已建立的饮食偏好。
- 结果:用户体验被破坏,信任感丧失。

有有效记忆的系统(右图):
- 系统能够跨会话记住用户的“素食、无乳制品”这一关键约束。
- 当用户再次询问时,系统能提供符合其偏好的选项,如“奶油腰果酱意面——纯素且无乳制品!”。
- 结果:交互连贯、个性化、值得信赖。
这个看似简单的例子,深刻揭示了记忆失败如何从根本上损害用户体验和信任。当前主流方法(如单纯扩大 LLM 上下文窗口)只是延迟了问题,而非解决它——模型会变得更慢、更贵,且依然可能忽略关键细节。
正是为了解决这一核心痛点,Mem0 应运而生。
— 2 何为Mem0?—
可构建具备可扩展长期记忆的生产级 AI Agent
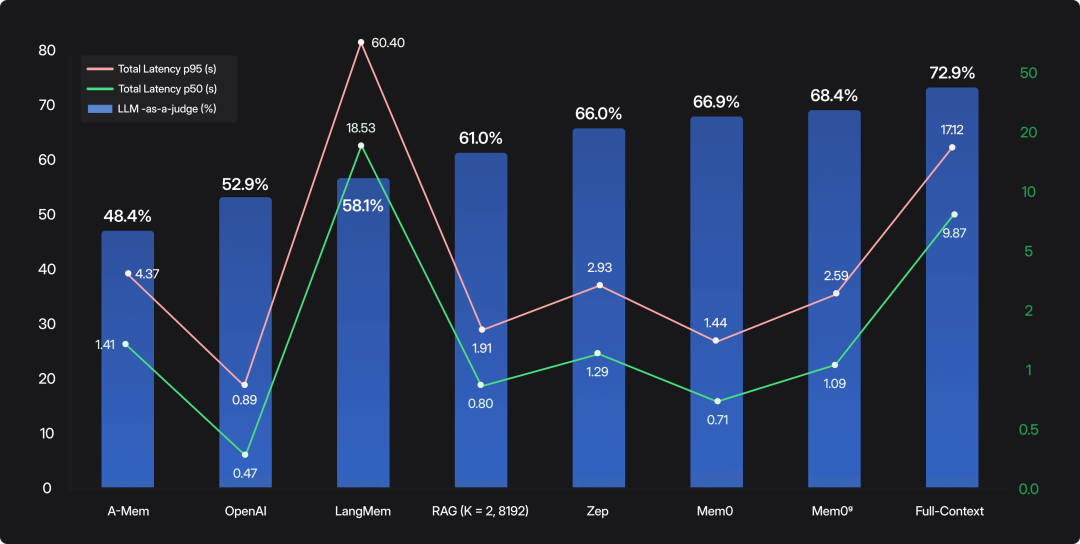
Mem0 是一种面向生产环境的、可扩展的记忆中心化算法,在其发布的论文报告《Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory》中可以看到,它通过动态提取和检索对话中的关键事实,实现了在 LOCOMO 基准测试上比 OpenAI 方法高 26% 的准确率,同时将 p95 延迟降低 91%,并节省 90% 的 token 成本。
其核心机制围绕一个两阶段的记忆流水线构建,并支持两种形态:基础版 Mem0 和图增强版 Mem0ᵍ。
1. 基础版 Mem0的两阶段记忆流水线(Two-Phase Pipeline)
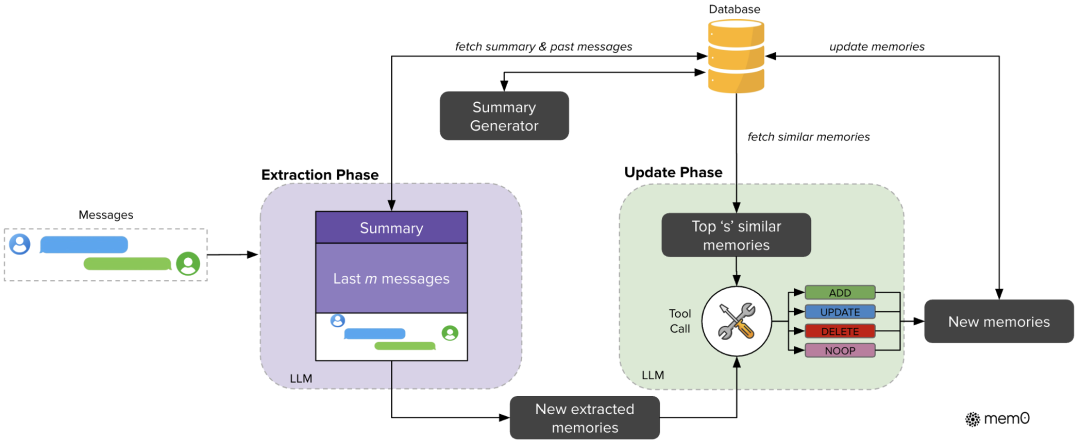
1)提取阶段(Extraction Phase)
系统从三个上下文源中提取候选记忆:
- 最新一轮对话(latest exchange)
- 滚动摘要(rolling summary)
- 最近 m 条消息(most recent messages)
通过一个 LLM,将这些内容压缩为简洁、结构化的候选记忆事实(如“用户偏好咖啡而非茶”)。 同时,一个后台异步模块持续更新长期摘要,避免阻塞主推理流程。
2)更新阶段(Update Phase)
对每个新提取的记忆事实,系统:
- 在向量数据库中检索最相似的 s 个已有记忆条目;
- 由 LLM 判断应执行以下哪种操作:
- - ADD:新增一条记忆;
- - UPDATE:更新已有记忆(如用户更改了偏好);
- - DELETE:删除矛盾或过时信息;
- - NOOP:无需操作(信息已存在且一致)。
该机制确保记忆库连贯、无冗余、实时可用。
2. Mem0ᵍ:图增强记忆(Graph-Enhanced Memory)
Mem0ᵍ 是 Mem0 的升级版,引入有向标签图结构(Directed Labeled Graph)来建模复杂关系。
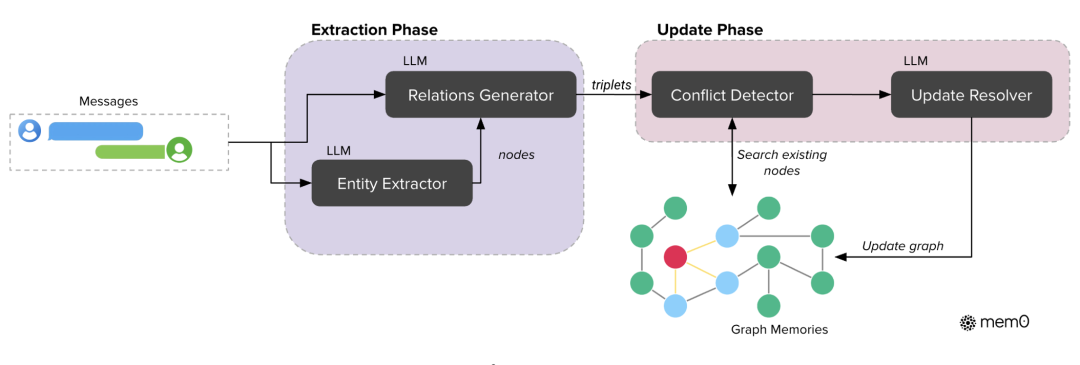
1)提取阶段(Graph Extraction)
- 实体提取器(Entity Extractor):识别对话中的实体(如“用户”、“产品A”)作为图节点;
- 关系生成器(Relations Generator):推断实体间的关系(如“用户 偏好 产品A”)作为带标签的边。
2)更新阶段(Graph Update)
-冲突检测器(Conflict Detector):识别重叠或矛盾的节点/边;
-更新解析器(Update Resolver,基于 LLM):决定对图元素执行:
- 添加(Add)
- 合并(Merge)
- 作废(Invalidate)
- 跳过(Skip)
该图结构支持子图检索和语义三元组匹配,适用于多跳推理、时序推理和开放域复杂任务。
— 3 性能优势 —
基于 LOCOMO 基准测试
比较项:Mem0 vs. OpenAI / Full-context
- 准确性:+26% 相对提升(66.9% vs. 52.9%)
- p95 延迟: 降低 91%(1.44s vs. 17.12s)
- Token 消耗:减少 90%(~1.8K vs. ~26K tokens/对话)
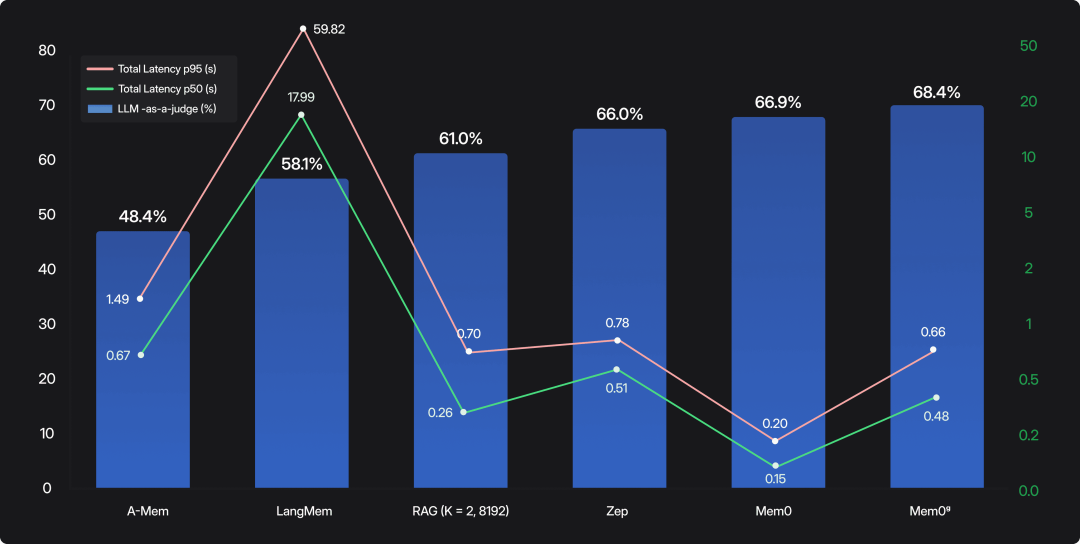
- 搜索延迟:Mem0 中位数仅 0.20 秒,p95 为 0.15 秒;
- 端到端响应:中位数 0.71 秒,p95 1.44 秒;
- Mem0ᵍ 在保持低延迟的同时,将准确率进一步提升至 68.4%。
— 4 总结 —
应用场景与意义
其设计兼顾准确性、实时性与成本效率,是目前少有的可规模化部署的长期记忆解决方案
Mem0 并非简单地“存更多上下文”,而是通过智能提取 + 动态更新 + 结构化存储,构建了一个轻量、精准、可演化的记忆系统。无论是基础向量形式(Mem0)还是图结构形式(Mem0ᵍ),都显著优于传统 RAG 或全上下文方法,为下一代具备“真正记忆能力”的 AI Agent 奠定了技术基础。
Mem0 使 AI Agent 能够:
-
跨会话记住用户偏好(如产品配置、沟通风格);
-
动态适应上下文变化(如项目状态更新);
-
在医疗、教育、企业客服等场景提供个性化、连贯服务;
再回顾图一中那个简单但深刻的“素食者”问题的终极回应:让 AI 不再遗忘,而是真正记住、理解并服务于每一个用户。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。
AI大模型全套学习资料【获取方式】


葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐
 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)