【大语言模型系列】讲人话,带你看懂BERT核心原理
前言:BERT 作为 NLP 领域的里程碑模型,其 “预训练 + 微调” 模式与动态词向量机制影响深远。此篇文章将详细拆解 BERT 结构和计算过程,清晰覆盖 Embedding 层、自注意力等关键模块。而且比起其他博客,直击技术迭代痛点 —— 对比当前主流的 GPT,明确指出多种BERT用到但目前已淘汰的方法,包括后来BERT模型的自行改进,兼具实用性与时效性,是快速理解 BERT 核心与技术趋势的优质参考。
目录
预训练语言模型——BERT
(一) 预训练
在BERT出现前,NLP任务的训练模式效率极低:每次做新任务都要从零训练模型参数,不仅依赖大量标注数据,还无法实现知识迁移。
BERT带来的核心革新是“预训练+微调”模式:
- 先让模型在海量无标注文本中“自学语言”,掌握语法、语义、逻辑关系,打下通用语言基础;
- 针对具体任务,用少量标注数据微调模型参数,快速适配需求。
BERT的预训练方式:Mask Language Model(我叫它Mask)
如下图,依照一定概率,用[mask]掩盖文本中的某个字或词,然后由周围的句子预测[mask],再对比预测的对不对。这是自编码语言模型的一种应用。当时BERT带火了这种预训练方式,不过在如今它已经不流行用于文本生成了,大部分用在需要精准理解语义的场景。
现在流行的是GPT的,给出前面所有词,不断预测下一个词的方式。这种就是自回归语言模型的一种应用。
(二) BERT介绍
BERT的本质是一种文本表征工具,核心作用是将文本转化为计算机能理解的高维数据,如下图。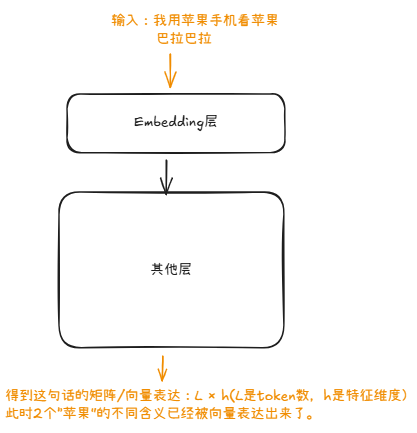
与Word2Vec的核心区别
| 特征 | Word2Vec(静态词向量) | BERT(动态词向量) |
|---|---|---|
| 语义表示 | 一个词对应一个固定向量 | 同一个词在不同语境下向量不同 |
| 示例 | “苹果”在“吃苹果”和“苹果手机”中向量一致 | 两个“苹果”向量不同,精准区分含义 |
| 核心优势 | 简单高效,训练成本低 | 适配语境变化,语义理解更精准 |
BERT可以根据不同作用输出两种不同形式:
- 文本 → 矩阵(max_length × hidden_size):保留每个词的语境化语义信息;
- 文本 → 向量(1 × hidden_size):聚合整个文本的全局语义信息(适用于分类、相似度计算等任务)。
(三) BERT结构
1. BERT的编码器Encoder
BERT的模型主体基于Transformer的编码器结构,就是从Transformer里抽出的一个部分。
Transformer是17年一篇很牛的论文《Attention is all your need》提出的,Transformer是现在主流的语言大模型结构。
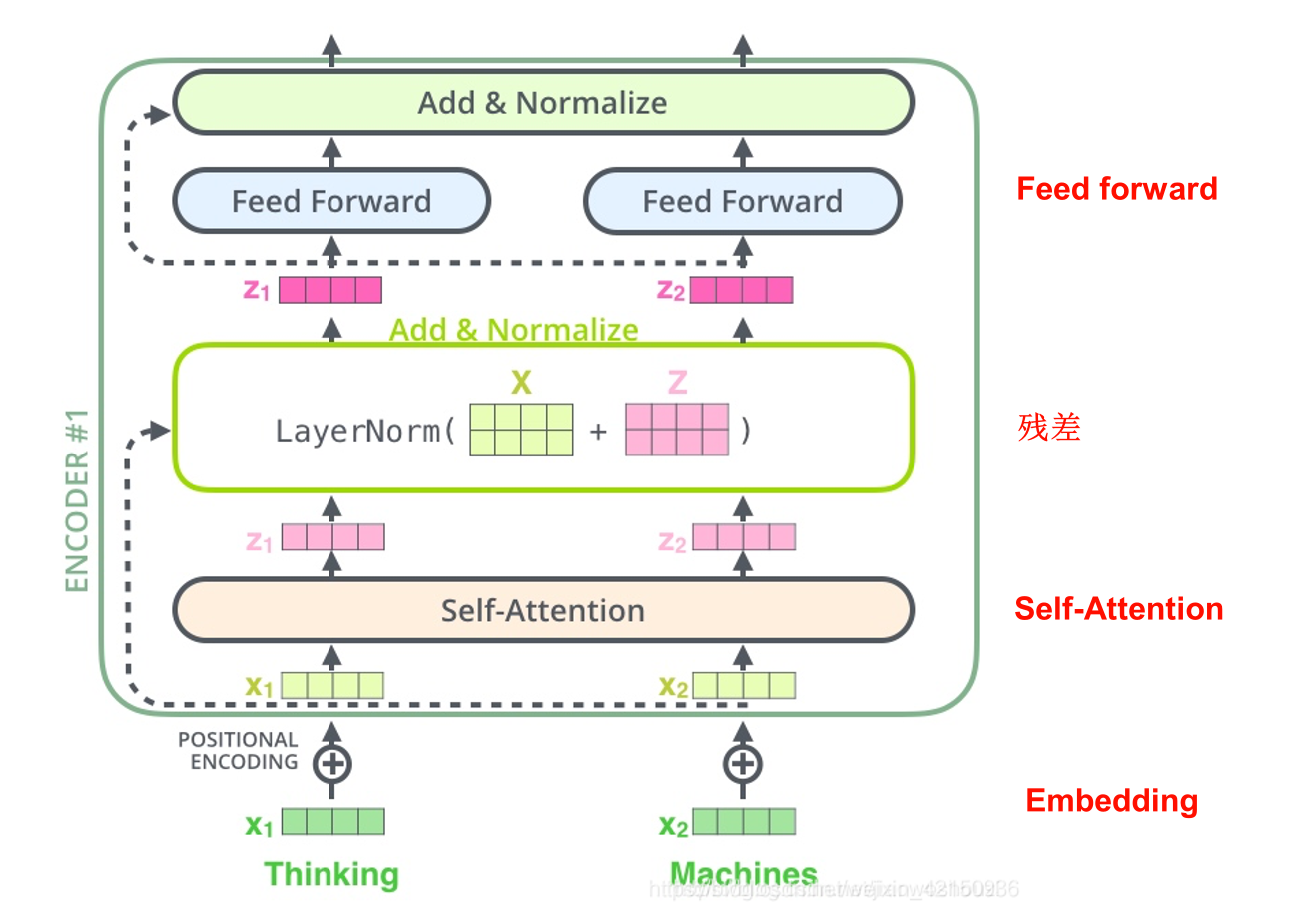
- BERT核心流程:
- 经过一层Embedding层,把文本转成向量。
- 通过n层相同结构的Transformer块。BERT-base为12层,BERT-large为24层(BERT-base就是基础版本的意思)。以下是Transformer块里面的网络层:
- 通过self-attention层,经过自注意力机制处理和多头机制处理
- 残差连接(X+Z)
- 归一化层,输出X1
- 通过Feed forward层,经过线性变换→激活函数→线性变换,输出 F
- 残差连接(X1 + F)
- 归一化层,输出X2
2. BERT的Embedding层
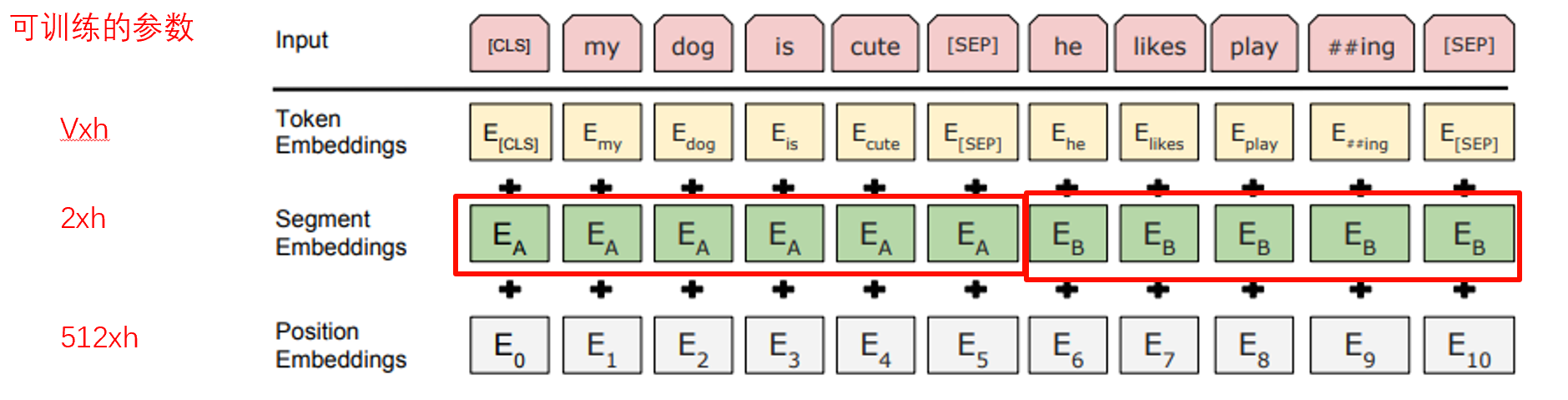
Embedding层的核心作用是给每个词向量注入三类关键信息,最终输出形状为(文本长度L × 向量维度h)的向量矩阵。
- 实现过程如下图所示,这是最初版的embedding层设计,这个结构现在已经被优化了,当时想的是向量必须带有词信息、来源词句信息、语序信息,所以用了三层,后来的研究表明2、3层效果不行。但是bert-base依然有研究意义:
- 词嵌入(Token Embedding):将词映射到高维向量,词表大小V×向量维度h(BERT-base中h=768)。比如图中的“my”单词变成一个Emy向量。
- 段嵌入(Segment Embedding):标记不同句子。
- 位置嵌入(Position Embedding):注入语序信息,标记所有单词的顺序,解决Transformer无法感知文本顺序的问题(最大句子长度固定为512,超过长度就截断成多份)。
- 三层都搞完之后,相加,作为embedding层的输出:Lxh(L是文本长度,比如“my dog”的L是2)。
补充说明:
- 输入文本需添加特殊标记:如图中所示,
[CLS](句子起始)、[SEP](句子分隔); - 三类嵌入向量求和后,会经过Layer Normalization(层归一化)优化训练稳定性。
3. BERT的self-attention自注意力机制
自注意力是Transformer的核心,让模型能捕捉文本中词与词的语义关联,比如“我今天做了无比美味香喷喷的饭”中“做”和“饭”的关系,输入输出形状均为L×h。
- 实现过程如下图所示,重点关注图中手绘的形状变化和公式。
- 生成Q、K、V矩阵:每个X(就是上一步embedding层的输出)分别乘以不同的可学习权重矩阵,得到查询(Q)、键(K)、值(V)。
Q = X × W^Q,K = X × W^K,V = X × W^V; - 计算注意力分数矩阵:通过Q与K^T的乘积除以√d_k(d_k为Q/K的维度),得到词与词的关联程度;
公式:softmax( (Q × K^T) / √d_k ); - 加权求和得到注意力输出:对分数矩阵做Softmax归一化(每行总和为1),再与V矩阵相乘,得到语境化向量Z。
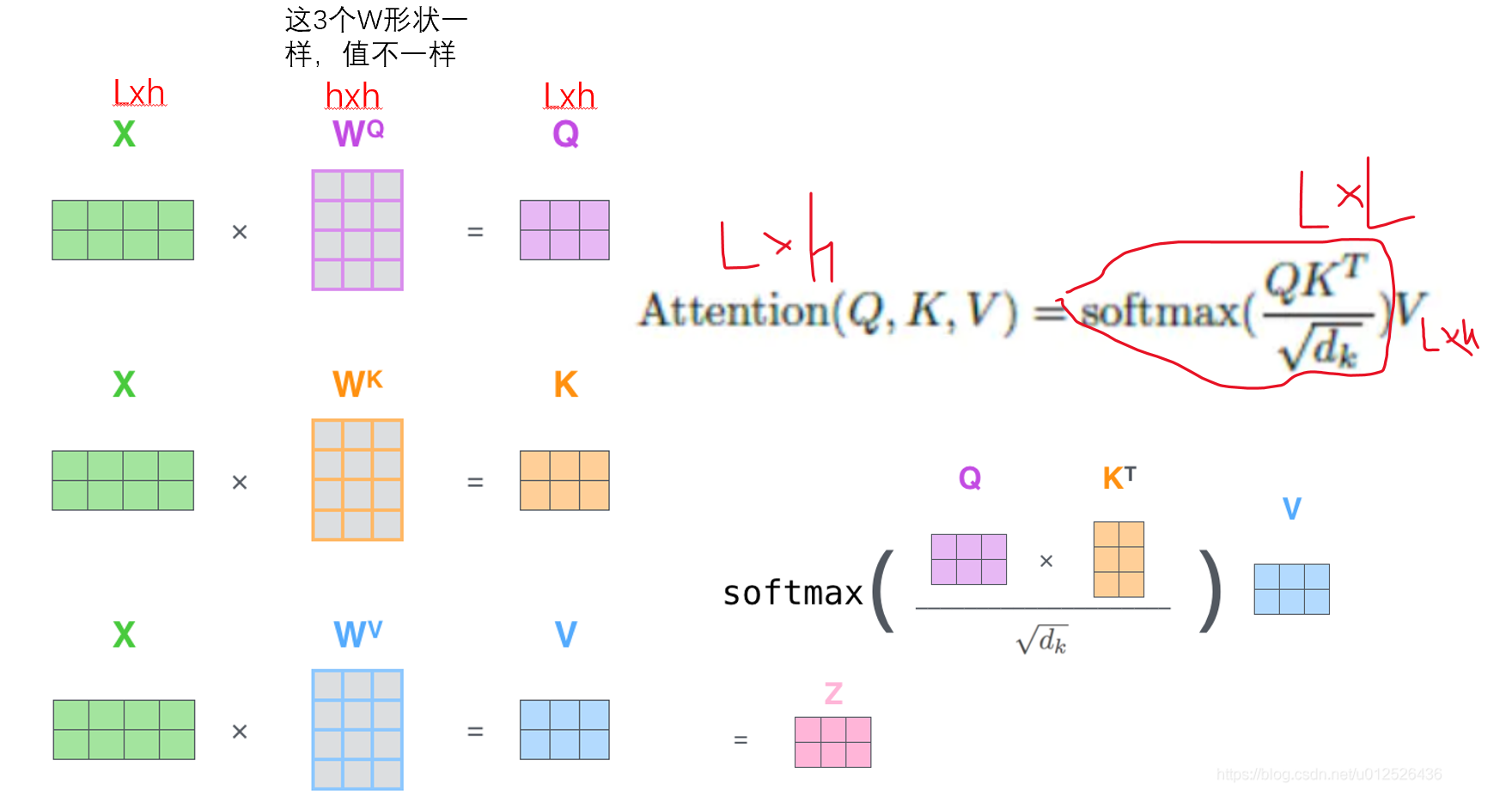
最终得到下图,如此便可以学习到文本中词与词的语义关联。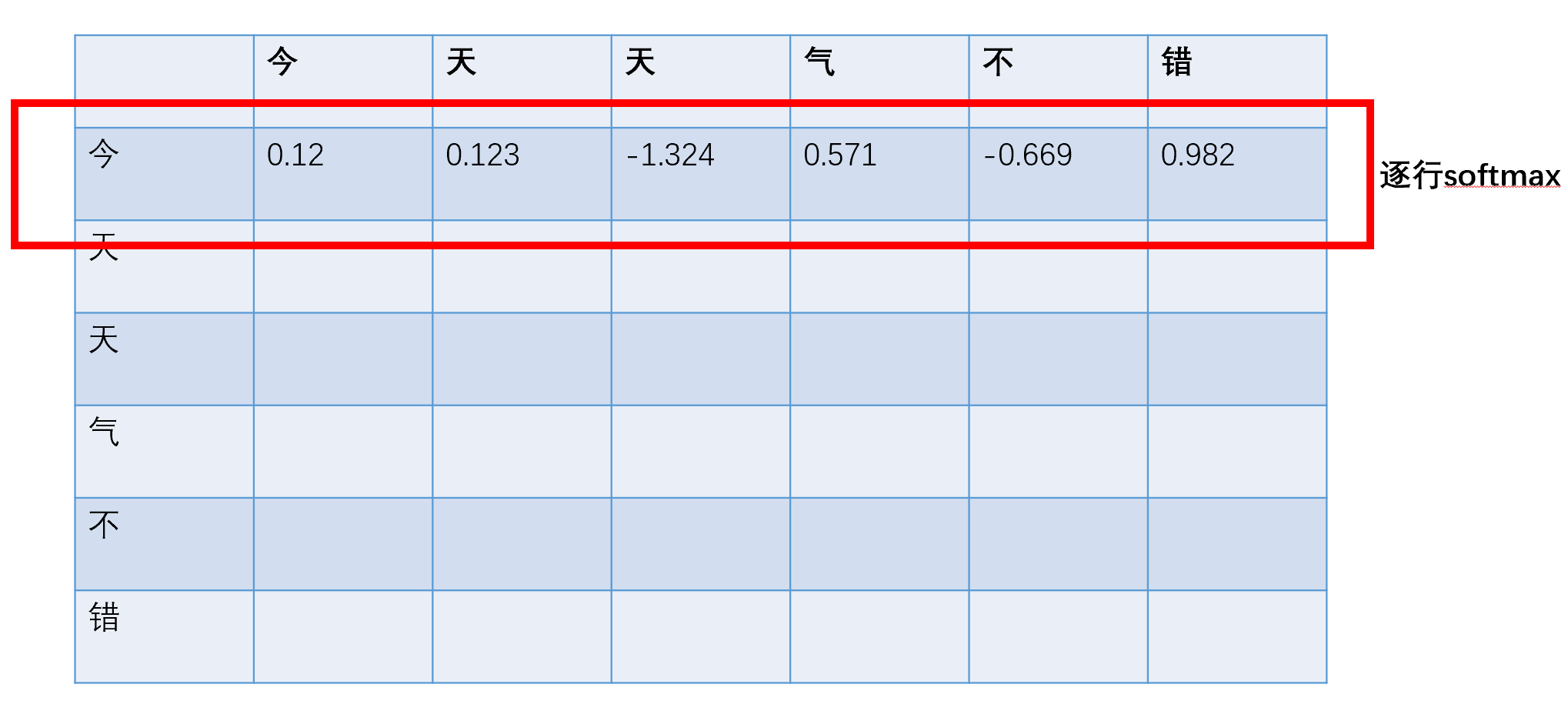
- 生成Q、K、V矩阵:每个X(就是上一步embedding层的输出)分别乘以不同的可学习权重矩阵,得到查询(Q)、键(K)、值(V)。
4. BERT的Multi-Head(多头机制)
为从多个角度捕捉语义,BERT采用多头注意力机制(BERT-base为8头)。
举个例子:假设我们要理解 “今天天气不错,适合去公园散步” 这句话:
第一个 “头” 可能专注于语法结构:关注 “今天” 和 “天气” 的主谓关系,“公园” 和 “散步” 的动宾关系;
第二个 “头” 可能专注于逻辑推理:从 “天气不错” 推导出 “适合户外活动”,再关联到 “公园散步” 的合理性;
第三个 “头” 可能专注于场景联想:由 “公园散步” 联想到 “阳光、绿树、休闲” 等具体画面;
……
(BERT-base 默认有 8 个这样的 “头”,每个头都有自己的关注点)
这些 “头” 各自独立分析文本后,会把所有视角的结果拼接起来,再通过一个线性层融合,最终得到一个全面且精准的语义表示。
- 实现过程如下图所示
- 计算得到Q、K、V后,将它们分别劈成n份,这n份再通过多个线性层,生成多组独立的“头”;
- 每组头独立执行Scaled Dot-Product Attention(缩放点积注意力);
- 拼接所有头的输出,再通过一个线性层融合,得到最终结果。
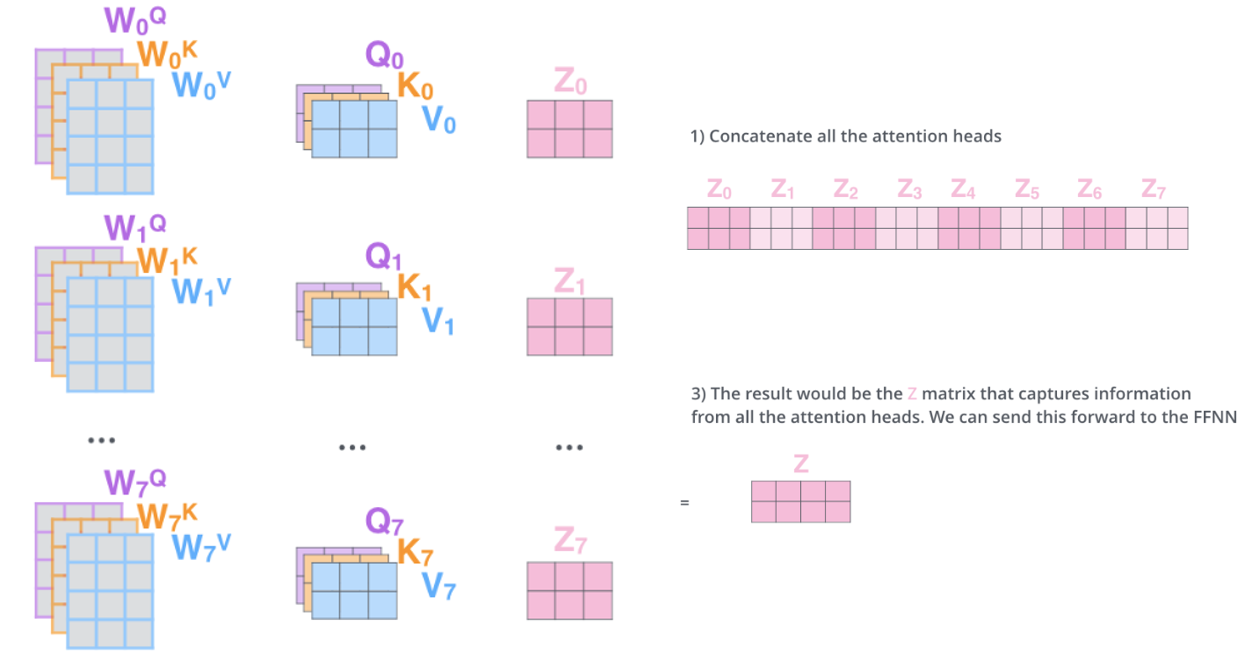
5. 残差连接
残差连接的作用:向量在经过无数层Transformer块训练之后,会丢失很多最原本的由embedding层输出的X的信息,通过把X和Z相加,再过一个归一化层,X的信息会再次带入到Z中。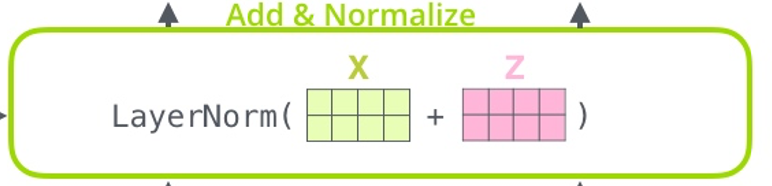
(四) BERT优势劣势
优势
- 充分利用海量无标注数据,无需人工标注,降低数据成本;
- 动态文本表征,能精准区分多义词、歧义句,语义理解更深刻;
- Transformer结构支持长距离语义关联捕捉,不受词间距影响;
- 在情感分析、命名实体识别等11个NLP任务中大幅刷新当时最优成绩。
劣势
- 预训练成本高:需要海量数据、超长训练时间和高性能GPU(开源模型已缓解此问题);
- 生成式任务短板:擅长文本理解(分类、匹配、问答),不适合文本生成(写文章、翻译);
- 运算复杂度高:参数量大(BERT-base约1.1亿参数),难以适配边缘设备等低性能场景;
- 依赖微调数据:缺乏具体任务的标注数据时,预训练模型的效果会大幅下降。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)