让AI学会了“自我把关“:DeepConf如何让模型推理既聪明又高效?
DeepConf的突破在于,首次让模型在推理过程中主动"自我把关",而非依赖事后处理。其"即插即用"的特性(无需训练、兼容所有模型)和显著的效率提升,为大规模落地提供了可能。未来,这一技术或可扩展至代码生成、科学推理等更多领域,推动大模型从"量变"走向"质变"。正如研究者所言:"大模型知道自己何时不确定,只是我们一直没认真听它的'思考过程'。"DeepConf的出现,或许正是打开这一"黑箱"的关键
当大模型在复杂推理中"胡思乱想"时,我们能否让它像人类高手一样,及时识别并淘汰低质量思路,专注走"高置信度路径"?近日,Meta AI与加州大学圣地亚哥分校联合提出的Deep Think with Confidence(DeepConf)给出了突破性答案——通过动态置信度筛选,首次让开源模型在国际顶尖数学竞赛AIME 2025中达成99.9%准确率,且无需任何工具辅助,同时将推理token消耗锐减84.7%!
核心突破:用"置信度信号"实时纠偏推理路径
传统大模型推理常面临两大痛点:要么"广撒网"生成大量低质量路径(浪费算力),要么依赖事后筛选(效率低下)。DeepConf的创新在于将"置信度评估"嵌入推理过程,通过"并行生成+动态筛选"的双轨机制,实现效率与精度的双重突破。
关键机制:三步打造"高置信度推理链"
- 并行生成,广撒网:模型同时生成多条推理路径(如数学解题的不同思路),覆盖多种可能性;
- 实时置信度评估:在每一步生成时,模型会为当前路径的"局部置信度"打分(绿色=高置信度,红色=低置信度),通过滑动窗口评估最近步骤的平均置信度,重点关注结尾的结论段;
- 动态筛选,优中选优:
- 离线模式:生成全部路径后,按置信度排序,淘汰后10%低质量路径,剩余路径通过置信度加权投票(高置信度路径的投票权重更高)得出最终答案;
- 在线模式:生成过程中,若某路径的置信度低于预设阈值(通过离线预热阶段标定),立即终止该路径,避免无效token消耗。
实验结果:刷爆纪录的"双优表现"
DeepConf在多项权威测试中验证了其颠覆性:
- 精度碾压:在AIME 2025上,离线模式达到99.9%准确率(基线97%),超越GPT-5等闭源模型;在5个模型×5个数据集的跨场景测试中,平均准确率提升约10%;
- 效率飞跃:在线模式下,AIME 2025测试中token消耗减少85%(GPT-OSS-120B模型),同时保持97.9%准确率;所有基准测试中节省33%-85%的算力;
- 普适性强:支持从8B到120B的开源模型(如Llama、Mixtral),无需额外训练或超参数调整,仅需50行代码即可集成到vLLM框架。
技术深挖:离线与在线模式的"双引擎"设计
离线模式:事后筛选,精准聚合
当模型已生成全部推理路径后,DeepConf通过两步优化答案:
- 置信度过滤:保留前90%或前10%的路径(前10%适合少数高质量路径场景,前90%适合需多样性的场景);
- 加权投票:每条路径的投票权重与其置信度正相关,避免低质量路径"拉低"结果。
在线模式:边生成边筛选,实时止损
通过"离线预热+自适应采样"实现动态终止:
- 离线预热:先生成少量路径(如16条),标定置信度阈值(如前10%的最低置信度);
- 在线生成:实时监控每条路径的置信度,若低于阈值立即终止;同时根据路径间的一致性(多数投票权重比)自适应调整生成数量,难题多生成,简单题早停止。
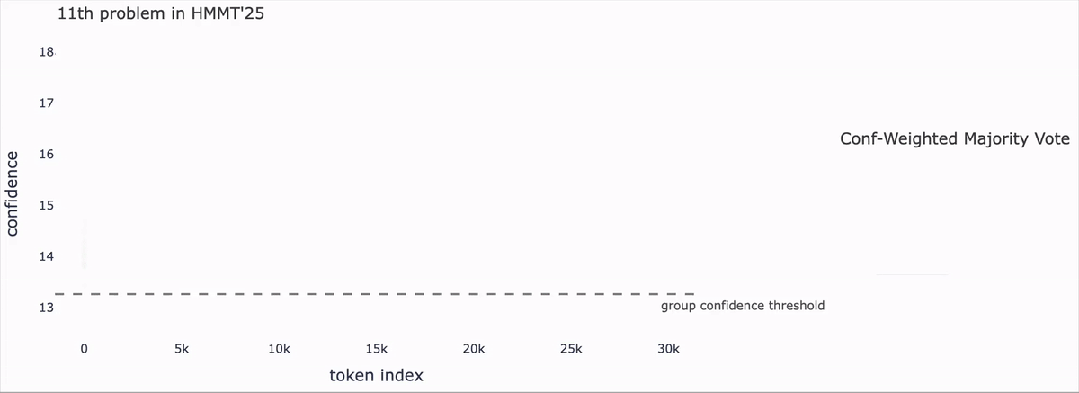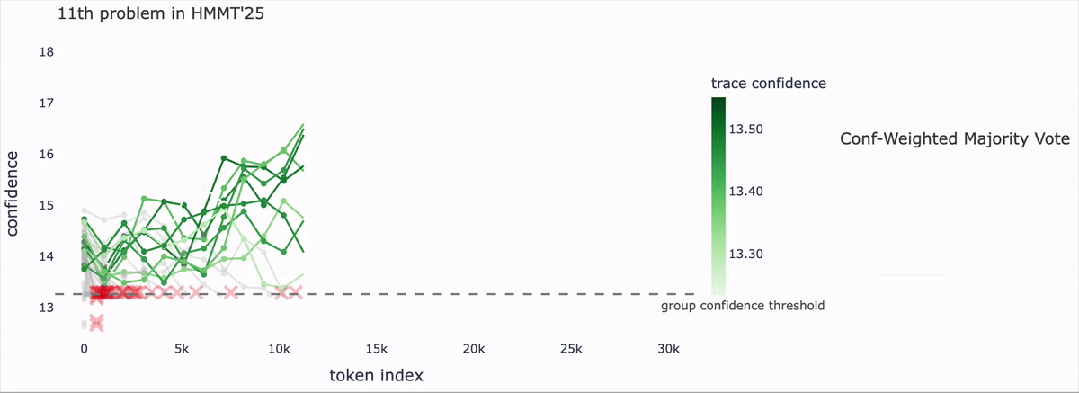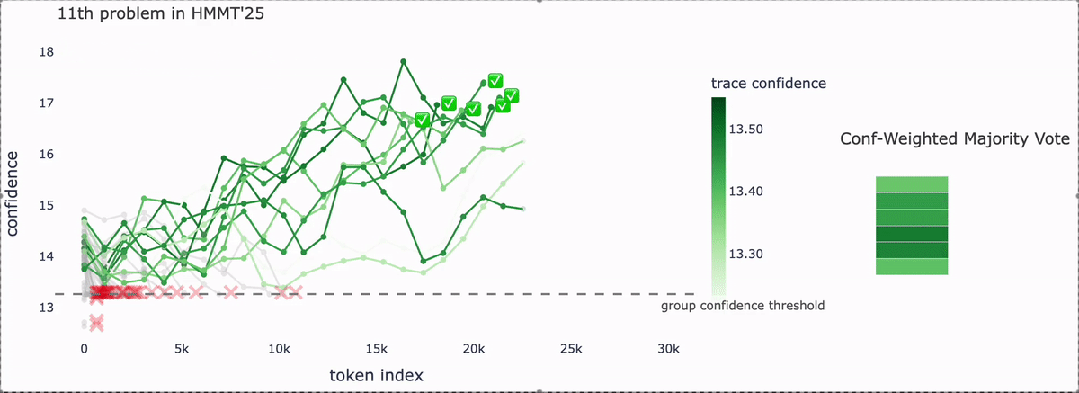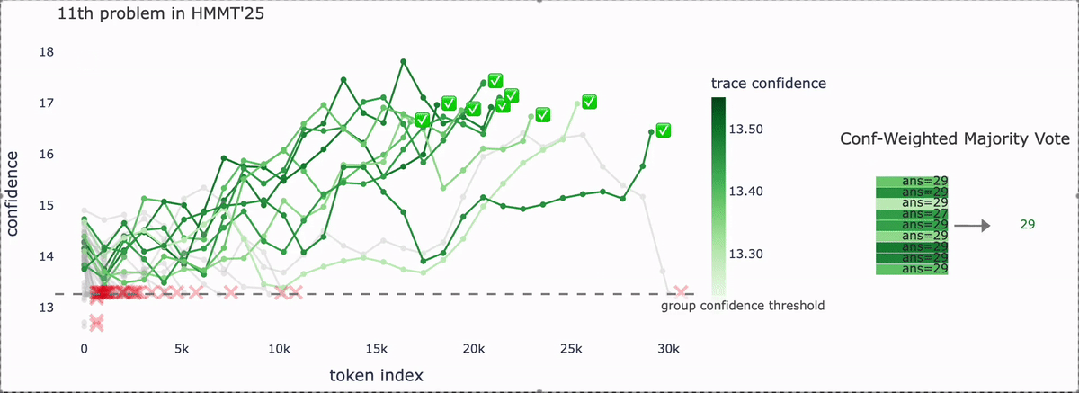
案例解析:从"勾股三元组计数"看DeepConf如何工作
以HMMT 25数学题为例,DeepConf的推理过程如下:
- 离线预热:生成5条完整路径,计算每条的置信度分数,确定终止阈值s(绿色箭头);
- 在线生成:并行生成多条路径,实时评估每一步的置信度:
- 绿色路径(如"勾股三元组公式推导...")置信度持续高位,继续生成;
- 红色路径(如"让我再想想...")置信度骤降,触发终止;
- 最终投票:保留的高置信度路径通过加权投票,得出统一答案(如29)。
意义与展望:重新定义大模型推理的"效率-精度"边界
DeepConf的突破在于,首次让模型在推理过程中主动"自我把关",而非依赖事后处理。其"即插即用"的特性(无需训练、兼容所有模型)和显著的效率提升,为大规模落地提供了可能。未来,这一技术或可扩展至代码生成、科学推理等更多领域,推动大模型从"量变"走向"质变"。
正如研究者所言:"大模型知道自己何时不确定,只是我们一直没认真听它的'思考过程'。"DeepConf的出现,或许正是打开这一"黑箱"的关键钥匙。

葡萄城是专业的软件开发技术和低代码平台提供商,聚焦软件开发技术,以“赋能开发者”为使命,致力于通过表格控件、低代码和BI等各类软件开发工具和服务
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)